 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and small footprint Hybrid HMM-HiFiGAN based system for speech synthesis in Indian languages
Feb 13, 2023



Hidden-Markov-model (HMM) based text-to-speech (HTS) offers flexibility in speaking styles along with fast training and synthesis while being computationally less intense. HTS performs well even in low-resource scenarios. The primary drawback is that the voice quality is poor compared to that of E2E systems. A hybrid approach combining HMM-based feature generation and neural-network-based HiFi-GAN vocoder to improve HTS synthesis quality is proposed. HTS is trained on high-resolution mel-spectrograms instead of conventional mel generalized coefficients (MGC), and the output mel-spectrogram corresponding to the input text is used in a HiFi-GAN vocoder trained on Indic languages, to produce naturalness that is equivalent to that of E2E systems, as evidenced from the DMOS and PC tests.
HMM-based data augmentation for E2E systems for building conversational speech synthesis systems
Dec 22, 2022This paper proposes an approach to build a high-quality text-to-speech (TTS) system for technical domains using data augmentation. An end-to-end (E2E) system is trained on hidden Markov model (HMM) based synthesized speech and further fine-tuned with studio-recorded TTS data to improve the timbre of the synthesized voice. The motivation behind the work is that issues of word skips and repetitions are usually absent in HMM systems due to their ability to model the duration distribution of phonemes accurately. Context-dependent pentaphone modeling, along with tree-based clustering and state-tying, takes care of unseen context and out-of-vocabulary words. A language model is also employed to reduce synthesis errors further. Subjective evaluations indicate that speech produced using the proposed system is superior to the baseline E2E synthesis approach in terms of intelligibility when combining complementing attributes from HMM and E2E frameworks. The further analysis highlights the proposed approach's efficacy in low-resource scenarios.
Technology Pipeline for Large Scale Cross-Lingual Dubbing of Lecture Videos into Multiple Indian Languages
Nov 01, 2022

Cross-lingual dubbing of lecture videos requires the transcription of the original audio, correction and removal of disfluencies, domain term discovery, text-to-text translation into the target language, chunking of text using target language rhythm, text-to-speech synthesis followed by isochronous lipsyncing to the original video. This task becomes challenging when the source and target languages belong to different language families, resulting in differences in generated audio duration. This is further compounded by the original speaker's rhythm, especially for extempore speech. This paper describes the challenges in regenerating English lecture videos in Indian languages semi-automatically. A prototype is developed for dubbing lectures into 9 Indian languages. A mean-opinion-score (MOS) is obtained for two languages, Hindi and Tamil, on two different courses. The output video is compared with the original video in terms of MOS (1-5) and lip synchronisation with scores of 4.09 and 3.74, respectively. The human effort also reduces by 75%.
Dual Script E2E framework for Multilingual and Code-Switching ASR
Jun 02, 2021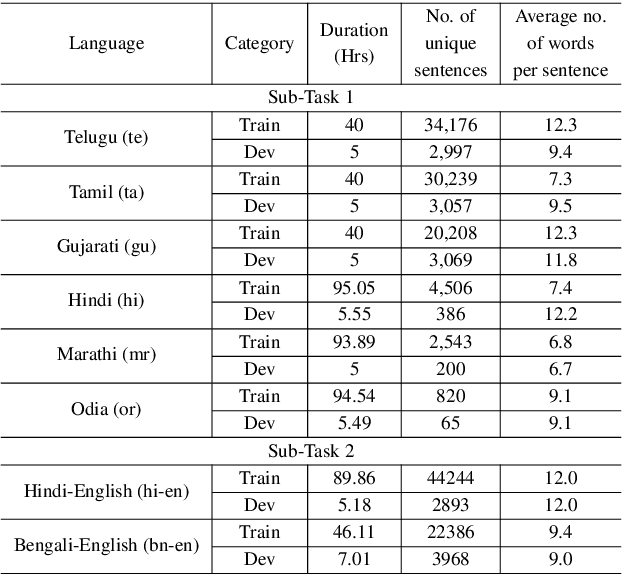
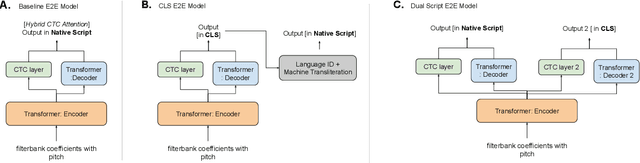
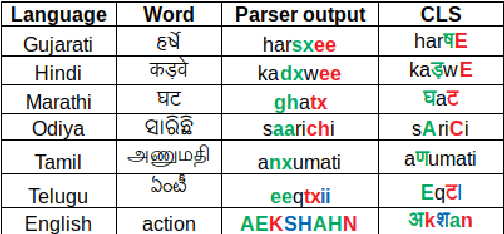
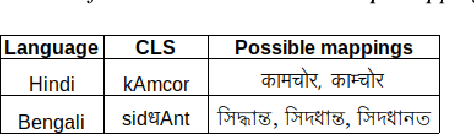
India is home to multiple languages, and training automatic speech recognition (ASR) systems for languages is challenging. Over time, each language has adopted words from other languages, such as English, leading to code-mixing. Most Indian languages also have their own unique scripts, which poses a major limitation in training multilingual and code-switching ASR systems. Inspired by results in text-to-speech synthesis, in this work, we use an in-house rule-based phoneme-level common label set (CLS) representation to train multilingual and code-switching ASR for Indian languages. We propose two end-to-end (E2E) ASR systems. In the first system, the E2E model is trained on the CLS representation, and we use a novel data-driven back-end to recover the native language script. In the second system, we propose a modification to the E2E model, wherein the CLS representation and the native language characters are used simultaneously for training. We show our results on the multilingual and code-switching tasks of the Indic ASR Challenge 2021. Our best results achieve 6% and 5% improvement (approx) in word error rate over the baseline system for the multilingual and code-switching tasks, respectively, on the challenge development data.
Front-end Diarization for Percussion Separation in Taniavartanam of Carnatic Music Concerts
Mar 04, 2021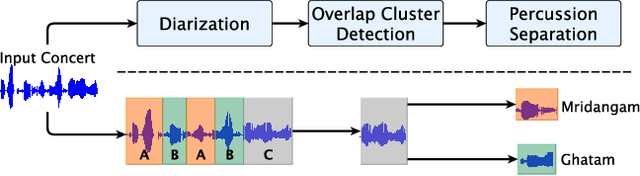
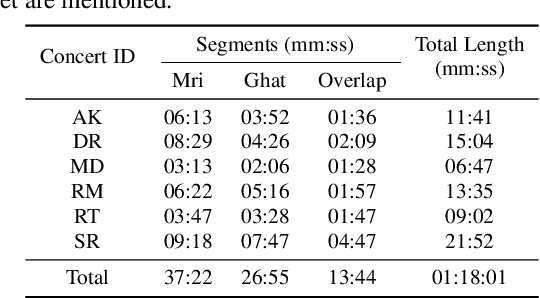
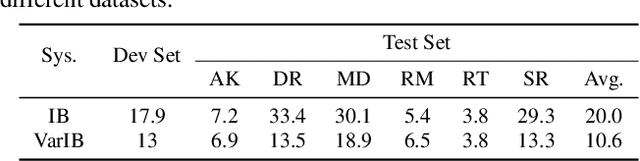
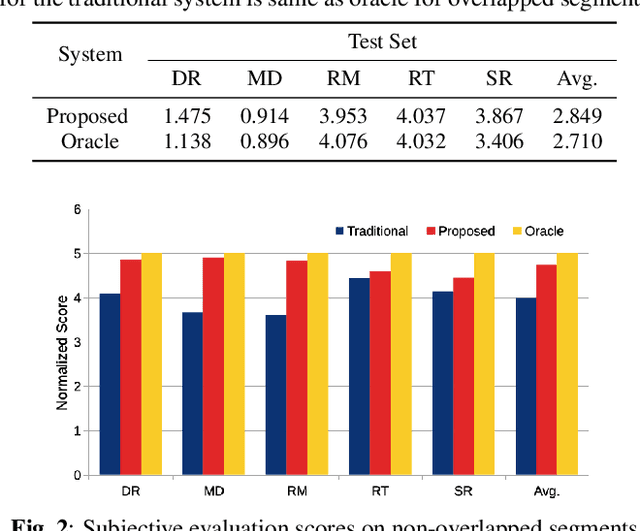
Instrument separation in an ensemble is a challenging task. In this work, we address the problem of separating the percussive voices in the taniavartanam segments of Carnatic music. In taniavartanam, a number of percussive instruments play together or in tandem. Separation of instruments in regions where only one percussion is present leads to interference and artifacts at the output, as source separation algorithms assume the presence of multiple percussive voices throughout the audio segment. We prevent this by first subjecting the taniavartanam to diarization. This process results in homogeneous clusters consisting of segments of either a single voice or multiple voices. A cluster of segments with multiple voices is identified using the Gaussian mixture model (GMM), which is then subjected to source separation. A deep recurrent neural network (DRNN) based approach is used to separate the multiple instrument segments. The effectiveness of the proposed system is evaluated on a standard Carnatic music dataset. The proposed approach provides close-to-oracle performance for non-overlapping segments and a significant improvement over traditional separation schemes.