 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Critical Gaps in Convergent Learning: How Representational Alignment Evolves Across Layers, Training, and Distribution Shifts
Feb 26, 2025

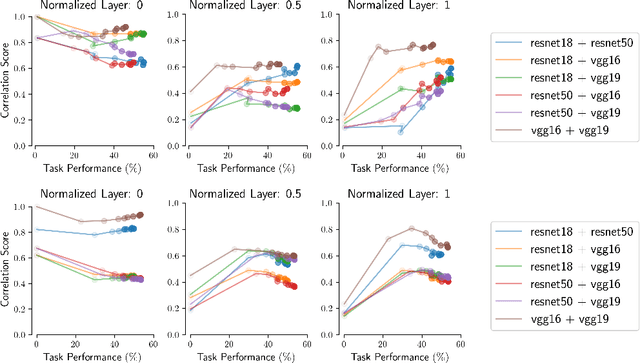

Understanding convergent learning -- the extent to which artificial and biological neural networks develop similar representations -- is crucial for neuroscience and AI, as it reveals shared learning principles and guides brain-like model design. While several studies have noted convergence in early and late layers of vision networks, key gaps remain. First, much existing work relies on a limited set of metrics, overlooking transformation invariances required for proper alignment. We compare three metrics that ignore specific irrelevant transformations: linear regression (ignoring affine transformations), Procrustes (ignoring rotations and reflections), and permutation/soft-matching (ignoring unit order). Notably, orthogonal transformations align representations nearly as effectively as more flexible linear ones, and although permutation scores are lower, they significantly exceed chance, indicating a robust representational basis. A second critical gap lies in understanding when alignment emerges during training. Contrary to expectations that convergence builds gradually with task-specific learning, our findings reveal that nearly all convergence occurs within the first epoch -- long before networks achieve optimal performance. This suggests that shared input statistics, architectural biases, or early training dynamics drive convergence rather than the final task solution. Finally, prior studies have not systematically examined how changes in input statistics affect alignment. Our work shows that out-of-distribution (OOD) inputs consistently amplify differences in later layers, while early layers remain aligned for both in-distribution and OOD inputs, suggesting that this alignment is driven by generalizable features stable across distribution shifts. These findings fill critical gaps in our understanding of representational convergence, with implications for neuroscience and AI.
Evaluating Representational Similarity Measures from the Lens of Functional Correspondence
Nov 21, 2024


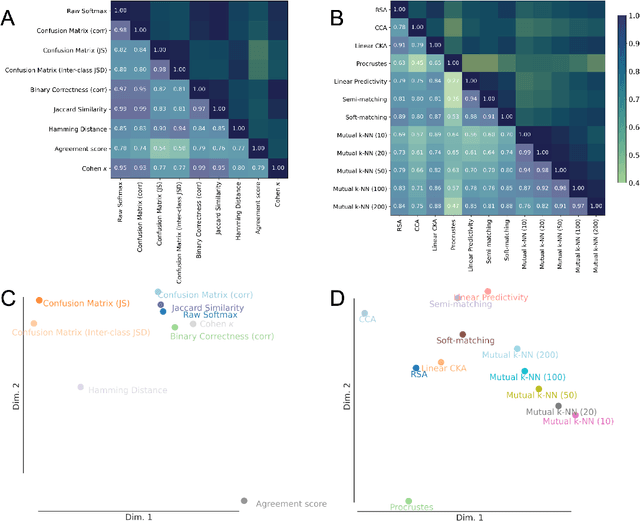
Neuroscience and artificial intelligence (AI) both face the challenge of interpreting high-dimensional neural data, where the comparative analysis of such data is crucial for revealing shared mechanisms and differences between these complex systems. Despite the widespread use of representational comparisons and the abundance classes of comparison methods, a critical question remains: which metrics are most suitable for these comparisons? While some studies evaluate metrics based on their ability to differentiate models of different origins or constructions (e.g., various architectures), another approach is to assess how well they distinguish models that exhibit distinct behaviors. To investigate this, we examine the degree of alignment between various representational similarity measures and behavioral outcomes, employing group statistics and a comprehensive suite of behavioral metrics for comparison. In our evaluation of eight commonly used representational similarity metrics in the visual domain -- spanning alignment-based, Canonical Correlation Analysis (CCA)-based, inner product kernel-based, and nearest-neighbor methods -- we found that metrics like linear Centered Kernel Alignment (CKA) and Procrustes distance, which emphasize the overall geometric structure or shape of representations, excelled in differentiating trained from untrained models and aligning with behavioral measures, whereas metrics such as linear predictivity, commonly used in neuroscience, demonstrated only moderate alignment with behavior. These insights are crucial for selecting metrics that emphasize behaviorally meaningful comparisons in NeuroAI research.
Fast and small footprint Hybrid HMM-HiFiGAN based system for speech synthesis in Indian languages
Feb 13, 2023



Hidden-Markov-model (HMM) based text-to-speech (HTS) offers flexibility in speaking styles along with fast training and synthesis while being computationally less intense. HTS performs well even in low-resource scenarios. The primary drawback is that the voice quality is poor compared to that of E2E systems. A hybrid approach combining HMM-based feature generation and neural-network-based HiFi-GAN vocoder to improve HTS synthesis quality is proposed. HTS is trained on high-resolution mel-spectrograms instead of conventional mel generalized coefficients (MGC), and the output mel-spectrogram corresponding to the input text is used in a HiFi-GAN vocoder trained on Indic languages, to produce naturalness that is equivalent to that of E2E systems, as evidenced from the DMOS and PC tests.
Technology Pipeline for Large Scale Cross-Lingual Dubbing of Lecture Videos into Multiple Indian Languages
Nov 01, 2022

Cross-lingual dubbing of lecture videos requires the transcription of the original audio, correction and removal of disfluencies, domain term discovery, text-to-text translation into the target language, chunking of text using target language rhythm, text-to-speech synthesis followed by isochronous lipsyncing to the original video. This task becomes challenging when the source and target languages belong to different language families, resulting in differences in generated audio duration. This is further compounded by the original speaker's rhythm, especially for extempore speech. This paper describes the challenges in regenerating English lecture videos in Indian languages semi-automatically. A prototype is developed for dubbing lectures into 9 Indian languages. A mean-opinion-score (MOS) is obtained for two languages, Hindi and Tamil, on two different courses. The output video is compared with the original video in terms of MOS (1-5) and lip synchronisation with scores of 4.09 and 3.74, respectively. The human effort also reduces by 75%.
Deep Learning--Based Scene Simplification for Bionic Vision
Jan 30, 2021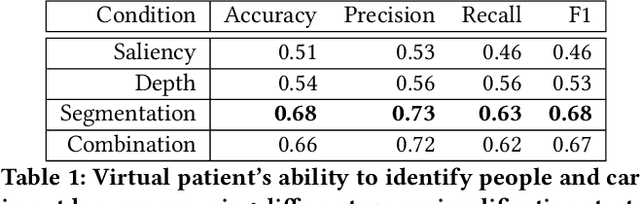
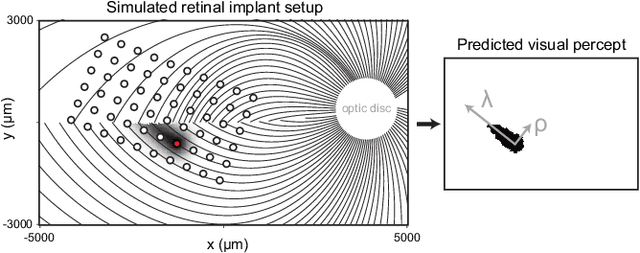
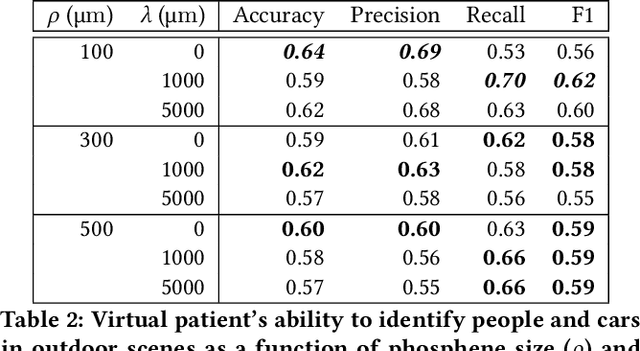

Retinal degenerative diseases cause profound visual impairment in more than 10 million people worldwide, and retinal prostheses are being developed to restore vision to these individuals. Analogous to cochlear implants, these devices electrically stimulate surviving retinal cells to evoke visual percepts (phosphenes). However, the quality of current prosthetic vision is still rudimentary. Rather than aiming to restore "natural" vision, there is potential merit in borrowing state-of-the-art computer vision algorithms as image processing techniques to maximize the usefulness of prosthetic vision. Here we combine deep learning--based scene simplification strategies with a psychophysically validated computational model of the retina to generate realistic predictions of simulated prosthetic vision, and measure their ability to support scene understanding of sighted subjects (virtual patients) in a variety of outdoor scenarios. We show that object segmentation may better support scene understanding than models based on visual saliency and monocular depth estimation. In addition, we highlight the importance of basing theoretical predictions on biologically realistic models of phosphene shape. Overall, this work has the potential to drastically improve the utility of prosthetic vision for people blinded from retinal degenerative diseases.
Deep Cross-Modal Audio-Visual Generation
Apr 26, 2017
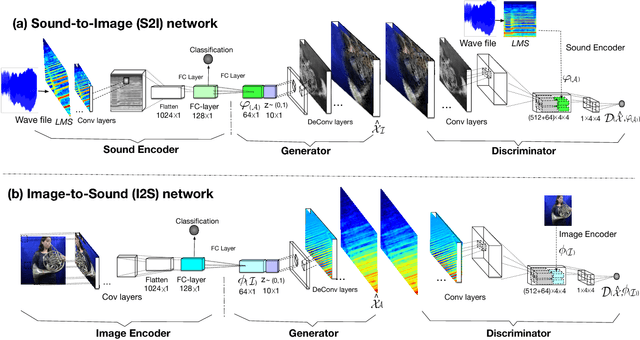


Cross-modal audio-visual perception has been a long-lasting topic in psychology and neurology, and various studies have discovered strong correlations in human perception of auditory and visual stimuli. Despite works in computational multimodal modeling, the problem of cross-modal audio-visual generation has not been systematically studied in the literature. In this paper, we make the first attempt to solve this cross-modal generation problem leveraging the power of deep generative adversarial training. Specifically, we use conditional generative adversarial networks to achieve cross-modal audio-visual generation of musical performances. We explore different encoding methods for audio and visual signals, and work on two scenarios: instrument-oriented generation and pose-oriented generation. Being the first to explore this new problem, we compose two new datasets with pairs of images and sounds of musical performances of different instruments. Our experiments using both classification and human evaluations demonstrate that our model has the ability to generate one modality, i.e., audio/visual, from the other modality, i.e., visual/audio, to a good extent. Our experiments on various design choices along with the datasets will facilitate future research in this new problem space.