 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges in Translating Technical Lectures: Insights from the NPTEL
Feb 09, 2026This study examines the practical applications and methodological implications of Machine Translation in Indian Languages, specifically Bangla, Malayalam, and Telugu, within emerging translation workflows and in relation to existing evaluation frameworks. The choice of languages prioritized in this study is motivated by a triangulation of linguistic diversity, which illustrates the significance of multilingual accommodation of educational technology under NEP 2020. This is further supported by the largest MOOC portal, i.e., NPTEL, which has served as a corpus to facilitate the arguments presented in this paper. The curation of a spontaneous speech corpora that accounts for lucid delivery of technical concepts, considering the retention of suitable register and lexical choices are crucial in a diverse country like India. The findings of this study highlight metric-specific sensitivity and the challenges of morphologically rich and semantically compact features when tested against surface overlapping metrics.
Kinship in Speech: Leveraging Linguistic Relatedness for Zero-Shot TTS in Indian Languages
Jun 04, 2025Text-to-speech (TTS) systems typically require high-quality studio data and accurate transcriptions for training. India has 1369 languages, with 22 official using 13 scripts. Training a TTS system for all these languages, most of which have no digital resources, seems a Herculean task. Our work focuses on zero-shot synthesis, particularly for languages whose scripts and phonotactics come from different families. The novelty of our work is in the augmentation of a shared phone representation and modifying the text parsing rules to match the phonotactics of the target language, thus reducing the synthesiser overhead and enabling rapid adaptation. Intelligible and natural speech was generated for Sanskrit, Maharashtrian and Canara Konkani, Maithili and Kurukh by leveraging linguistic connections across languages with suitable synthesisers. Evaluations confirm the effectiveness of this approach, highlighting its potential to expand speech technology access for under-represented languages.
Everyday Speech in the Indian Subcontinent
Oct 14, 2024India has 1369 languages of which 22 are official. About 13 different scripts are used to represent these languages. A Common Label Set (CLS) was developed based on phonetics to address the issue of large vocabulary of units required in the End to End (E2E) framework for multilingual synthesis. This reduced the footprint of the synthesizer and also enabled fast adaptation to new languages which had similar phonotactics, provided language scripts belonged to the same family. In this paper, we provide new insights into speech synthesis, where the script belongs to one family, while the phonotactics comes from another. Indian language text is first converted to CLS, and then a synthesizer that matches the phonotactics of the language is used. Quality akin to that of a native speaker is obtained for Sanskrit and Konkani with zero adaptation data, using Kannada and Marathi synthesizers respectively. Further, this approach also lends itself seamless code switching across 13 Indian languages and English in a given native speaker's voice.
Fast and small footprint Hybrid HMM-HiFiGAN based system for speech synthesis in Indian languages
Feb 13, 2023



Hidden-Markov-model (HMM) based text-to-speech (HTS) offers flexibility in speaking styles along with fast training and synthesis while being computationally less intense. HTS performs well even in low-resource scenarios. The primary drawback is that the voice quality is poor compared to that of E2E systems. A hybrid approach combining HMM-based feature generation and neural-network-based HiFi-GAN vocoder to improve HTS synthesis quality is proposed. HTS is trained on high-resolution mel-spectrograms instead of conventional mel generalized coefficients (MGC), and the output mel-spectrogram corresponding to the input text is used in a HiFi-GAN vocoder trained on Indic languages, to produce naturalness that is equivalent to that of E2E systems, as evidenced from the DMOS and PC tests.
HMM-based data augmentation for E2E systems for building conversational speech synthesis systems
Dec 22, 2022This paper proposes an approach to build a high-quality text-to-speech (TTS) system for technical domains using data augmentation. An end-to-end (E2E) system is trained on hidden Markov model (HMM) based synthesized speech and further fine-tuned with studio-recorded TTS data to improve the timbre of the synthesized voice. The motivation behind the work is that issues of word skips and repetitions are usually absent in HMM systems due to their ability to model the duration distribution of phonemes accurately. Context-dependent pentaphone modeling, along with tree-based clustering and state-tying, takes care of unseen context and out-of-vocabulary words. A language model is also employed to reduce synthesis errors further. Subjective evaluations indicate that speech produced using the proposed system is superior to the baseline E2E synthesis approach in terms of intelligibility when combining complementing attributes from HMM and E2E frameworks. The further analysis highlights the proposed approach's efficacy in low-resource scenarios.
Front-end Diarization for Percussion Separation in Taniavartanam of Carnatic Music Concerts
Mar 04, 2021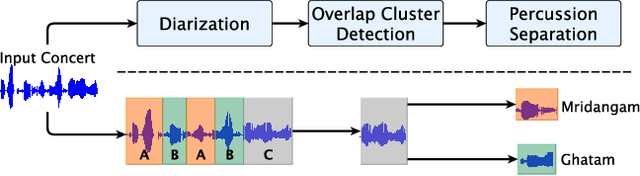
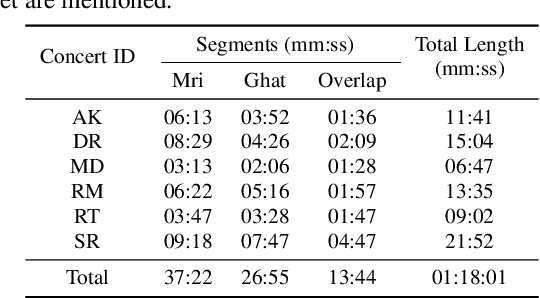
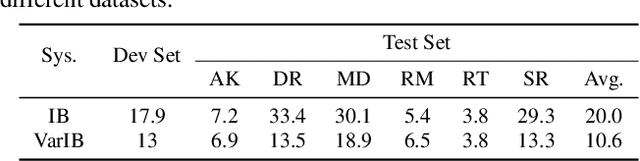
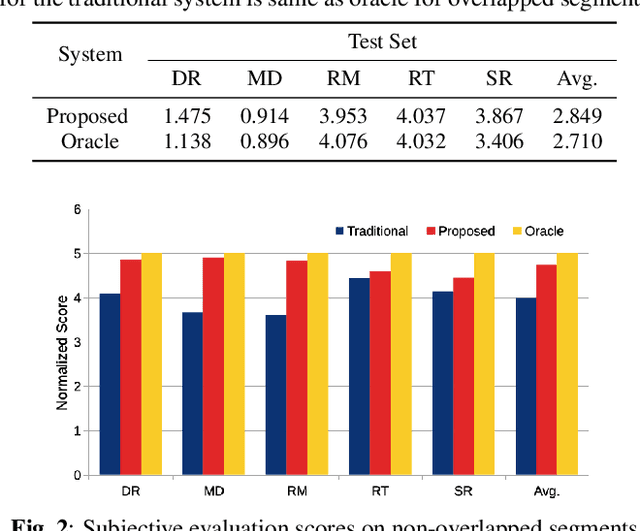
Instrument separation in an ensemble is a challenging task. In this work, we address the problem of separating the percussive voices in the taniavartanam segments of Carnatic music. In taniavartanam, a number of percussive instruments play together or in tandem. Separation of instruments in regions where only one percussion is present leads to interference and artifacts at the output, as source separation algorithms assume the presence of multiple percussive voices throughout the audio segment. We prevent this by first subjecting the taniavartanam to diarization. This process results in homogeneous clusters consisting of segments of either a single voice or multiple voices. A cluster of segments with multiple voices is identified using the Gaussian mixture model (GMM), which is then subjected to source separation. A deep recurrent neural network (DRNN) based approach is used to separate the multiple instrument segments. The effectiveness of the proposed system is evaluated on a standard Carnatic music dataset. The proposed approach provides close-to-oracle performance for non-overlapping segments and a significant improvement over traditional separation schemes.
Towards Zero-Shot Learning with Fewer Seen Class Examples
Nov 14, 2020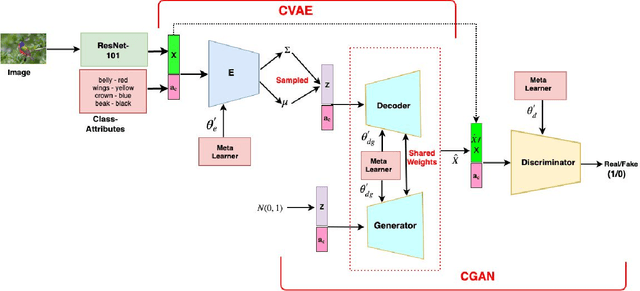
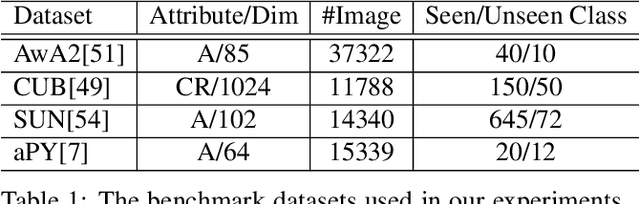
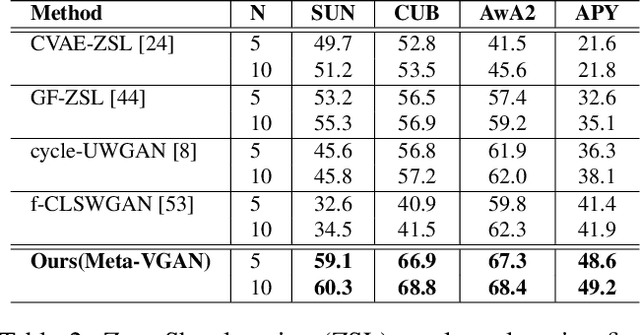
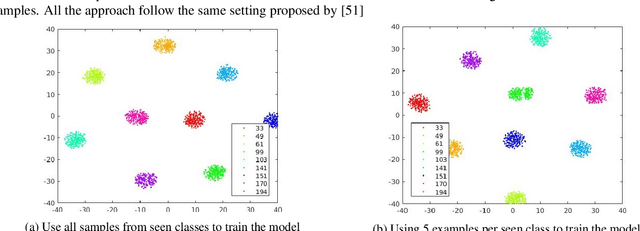
We present a meta-learning based generative model for zero-shot learning (ZSL) towards a challenging setting when the number of training examples from each \emph{seen} class is very few. This setup contrasts with the conventional ZSL approaches, where training typically assumes the availability of a sufficiently large number of training examples from each of the seen classes. The proposed approach leverages meta-learning to train a deep generative model that integrates variational autoencoder and generative adversarial networks. We propose a novel task distribution where meta-train and meta-validation classes are disjoint to simulate the ZSL behaviour in training. Once trained, the model can generate synthetic examples from seen and unseen classes. Synthesize samples can then be used to train the ZSL framework in a supervised manner. The meta-learner enables our model to generates high-fidelity samples using only a small number of training examples from seen classes. We conduct extensive experiments and ablation studies on four benchmark datasets of ZSL and observe that the proposed model outperforms state-of-the-art approaches by a significant margin when the number of examples per seen class is very small.
Stacked Adversarial Network for Zero-Shot Sketch based Image Retrieval
Jan 18, 2020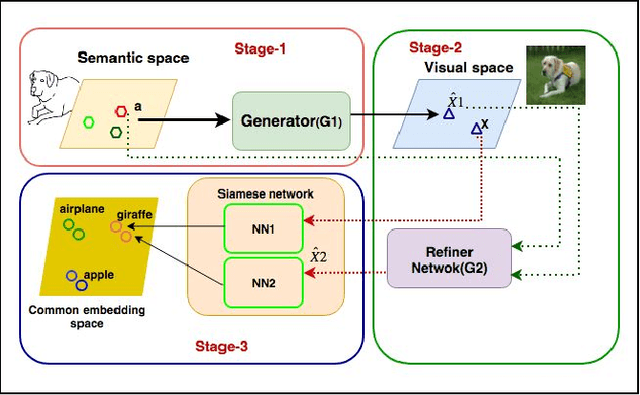
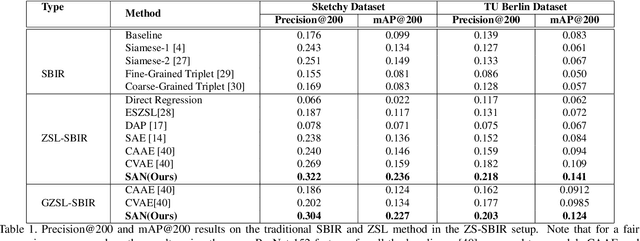
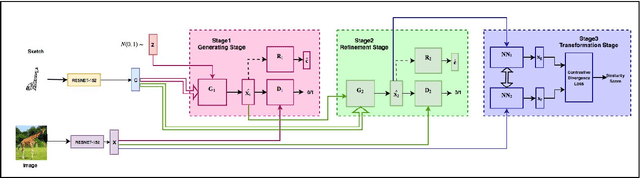
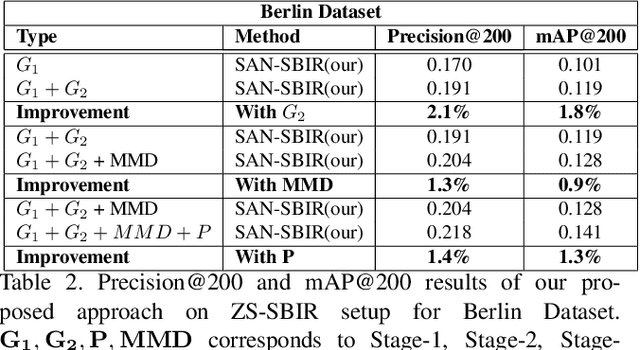
Conventional approaches to Sketch-Based Image Retrieval (SBIR) assume that the data of all the classes are available during training. The assumption may not always be practical since the data of a few classes may be unavailable, or the classes may not appear at the time of training. Zero-Shot Sketch-Based Image Retrieval (ZS-SBIR) relaxes this constraint and allows the algorithm to handle previously unseen classes during the test. This paper proposes a generative approach based on the Stacked Adversarial Network (SAN) and the advantage of Siamese Network (SN) for ZS-SBIR. While SAN generates a high-quality sample, SN learns a better distance metric compared to that of the nearest neighbor search. The capability of the generative model to synthesize image features based on the sketch reduces the SBIR problem to that of an image-to-image retrieval problem. We evaluate the efficacy of our proposed approach on TU-Berlin, and Sketchy database in both standard ZSL and generalized ZSL setting. The proposed method yields a significant improvement in standard ZSL as well as in a more challenging generalized ZSL setting (GZSL) for SBIR.
Spoof detection using x-vector and feature switching
Apr 16, 2019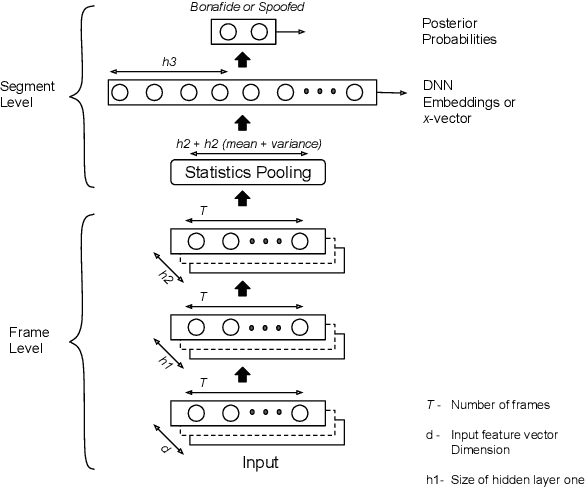
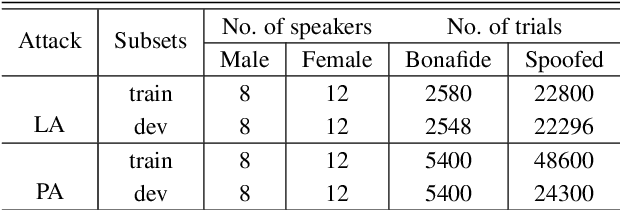
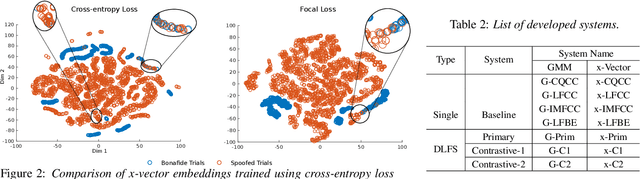
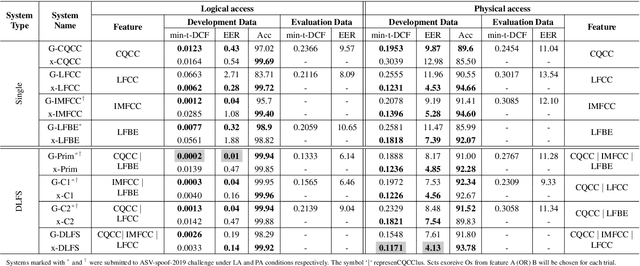
Detecting spoofed utterances is a fundamental problem in voice-based biometrics. Spoofing can be performed either by logical accesses like speech synthesis, voice conversion or by physical accesses such as replaying the pre-recorded utterance. Inspired by the state-of-the-art x-vector based speaker verification approach, this paper proposes a deep neural network (DNN) architecture for spoof detection from both logical and physical access. A novelty of the x-vector approach vis-a-vis conventional DNN based systems is that it can handle variable length utterances during testing. Performance of the proposed x-vector systems and the baseline Gaussian mixture model (GMM) systems is analyzed on the ASV-spoof-2019 dataset. The proposed system surpasses the GMM system for physical access, whereas the GMM system detects logical access better. Compared to the GMM systems, the proposed x-vector approach gives an average relative improvement of 14.64% for physical access. When combined with the decision-level feature switching (DLFS) paradigm, the best system in the proposed approach outperforms the best baseline systems with a relative improvement of 67.48% and 40.04% for both logical and physical access in terms of minimum tandem cost detection function (min-t-DCF), respectively.