 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective, Controlled and Domain-Agnostic Unlearning in Pretrained CLIP: A Training- and Data-Free Approach
Dec 16, 2025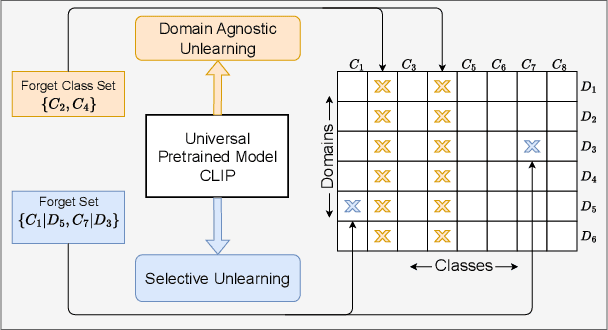
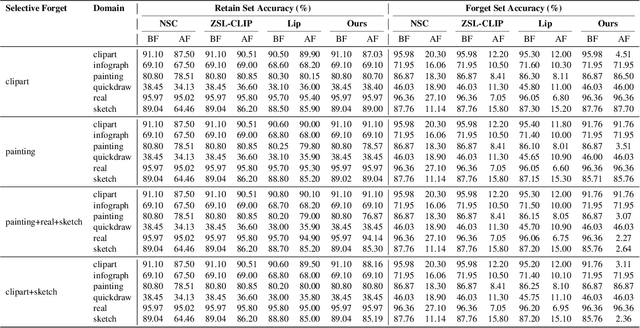
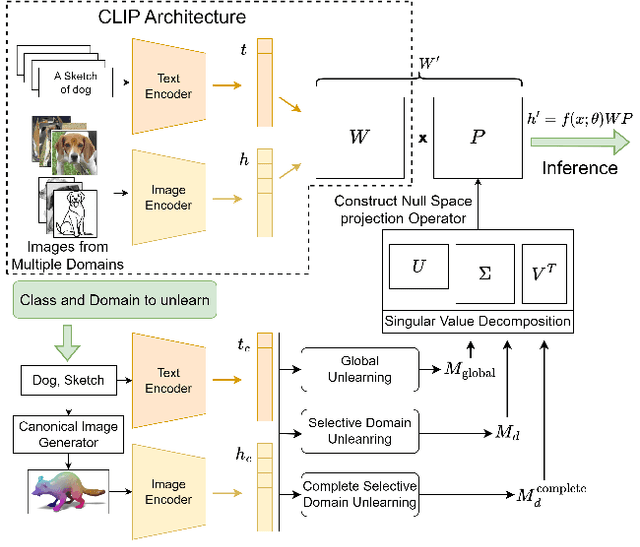
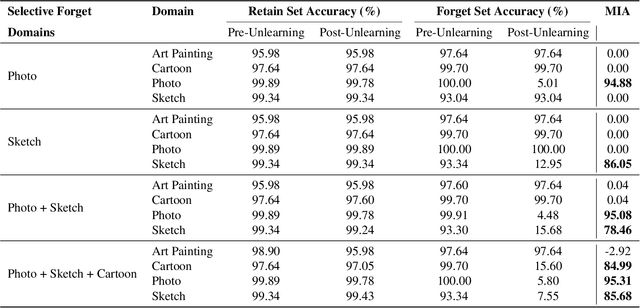
Pretrained models like CLIP have demonstrated impressive zero-shot classification capabilities across diverse visual domains, spanning natural images, artistic renderings, and abstract representations. However, real-world applications often demand the removal (or "unlearning") of specific object classes without requiring additional data or retraining, or affecting the model's performance on unrelated tasks. In this paper, we propose a novel training- and data-free unlearning framework that enables three distinct forgetting paradigms: (1) global unlearning of selected objects across all domains, (2) domain-specific knowledge removal (e.g., eliminating sketch representations while preserving photo recognition), and (3) complete unlearning in selective domains. By leveraging a multimodal nullspace through synergistic integration of text prompts and synthesized visual prototypes derived from CLIP's joint embedding space, our method efficiently removes undesired class information while preserving the remaining knowledge. This approach overcomes the limitations of existing retraining-based methods and offers a flexible and computationally efficient solution for controlled model forgetting.
Erasing CLIP Memories: Non-Destructive, Data-Free Zero-Shot class Unlearning in CLIP Models
Dec 16, 2025We introduce a novel, closed-form approach for selective unlearning in multimodal models, specifically targeting pretrained models such as CLIP. Our method leverages nullspace projection to erase the target class information embedded in the final projection layer, without requiring any retraining or the use of images from the forget set. By computing an orthonormal basis for the subspace spanned by target text embeddings and projecting these directions, we dramatically reduce the alignment between image features and undesired classes. Unlike traditional unlearning techniques that rely on iterative fine-tuning and extensive data curation, our approach is both computationally efficient and surgically precise. This leads to a pronounced drop in zero-shot performance for the target classes while preserving the overall multimodal knowledge of the model. Our experiments demonstrate that even a partial projection can balance between complete unlearning and retaining useful information, addressing key challenges in model decontamination and privacy preservation.
BadScan: An Architectural Backdoor Attack on Visual State Space Models
Nov 26, 2024The newly introduced Visual State Space Model (VMamba), which employs \textit{State Space Mechanisms} (SSM) to interpret images as sequences of patches, has shown exceptional performance compared to Vision Transformers (ViT) across various computer vision tasks. However, recent studies have highlighted that deep models are susceptible to adversarial attacks. One common approach is to embed a trigger in the training data to retrain the model, causing it to misclassify data samples into a target class, a phenomenon known as a backdoor attack. In this paper, we first evaluate the robustness of the VMamba model against existing backdoor attacks. Based on this evaluation, we introduce a novel architectural backdoor attack, termed BadScan, designed to deceive the VMamba model. This attack utilizes bit plane slicing to create visually imperceptible backdoored images. During testing, if a trigger is detected by performing XOR operations between the $k^{th}$ bit planes of the modified triggered patches, the traditional 2D selective scan (SS2D) mechanism in the visual state space (VSS) block of VMamba is replaced with our newly designed BadScan block, which incorporates four newly developed scanning patterns. We demonstrate that the BadScan backdoor attack represents a significant threat to visual state space models and remains effective even after complete retraining from scratch. Experimental results on two widely used image classification datasets, CIFAR-10, and ImageNet-1K, reveal that while visual state space models generally exhibit robustness against current backdoor attacks, the BadScan attack is particularly effective, achieving a higher Triggered Accuracy Ratio (TAR) in misleading the VMamba model and its variants.
Online Lifelong Generalized Zero-Shot Learning
Mar 22, 2021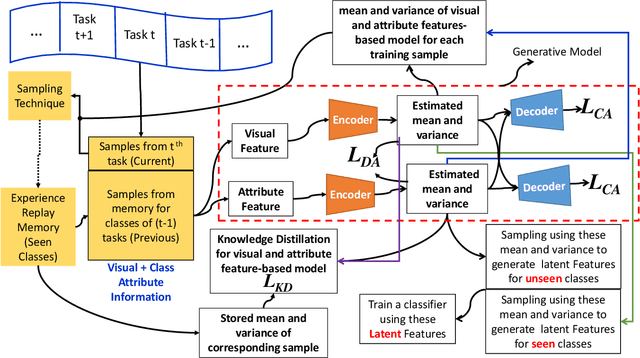
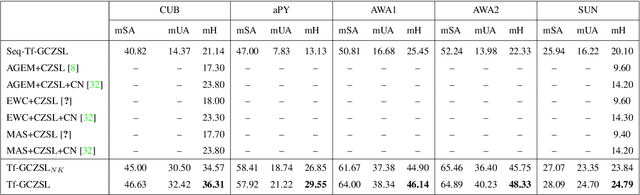
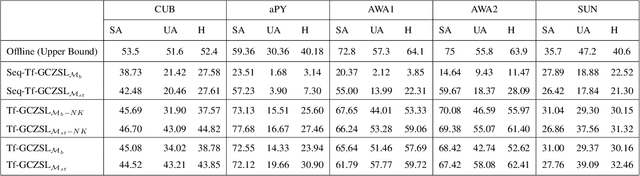
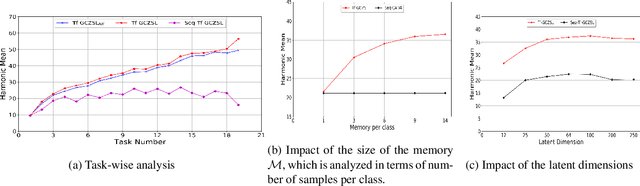
Methods proposed in the literature for zero-shot learning (ZSL) are typically suitable for offline learning and cannot continually learn from sequential streaming data. The sequential data comes in the form of tasks during training. Recently, a few attempts have been made to handle this issue and develop continual ZSL (CZSL) methods. However, these CZSL methods require clear task-boundary information between the tasks during training, which is not practically possible. This paper proposes a task-free (i.e., task-agnostic) CZSL method, which does not require any task information during continual learning. The proposed task-free CZSL method employs a variational autoencoder (VAE) for performing ZSL. To develop the CZSL method, we combine the concept of experience replay with knowledge distillation and regularization. Here, knowledge distillation is performed using the training sample's dark knowledge, which essentially helps overcome the catastrophic forgetting issue. Further, it is enabled for task-free learning using short-term memory. Finally, a classifier is trained on the synthetic features generated at the latent space of the VAE. Moreover, the experiments are conducted in a challenging and practical ZSL setup, i.e., generalized ZSL (GZSL). These experiments are conducted for two kinds of single-head continual learning settings: (i) mild setting-: task-boundary is known only during training but not during testing; (ii) strict setting-: task-boundary is not known at training, as well as testing. Experimental results on five benchmark datasets exhibit the validity of the approach for CZSL.
Generative Replay-based Continual Zero-Shot Learning
Jan 22, 2021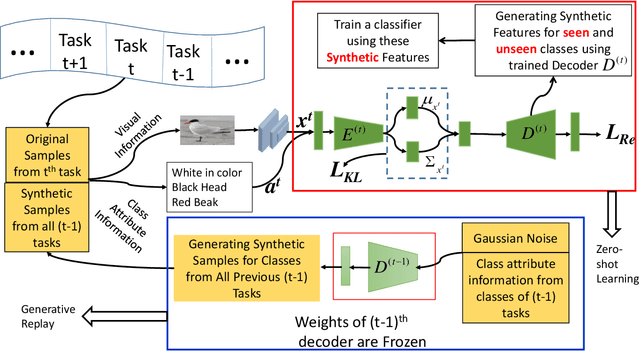


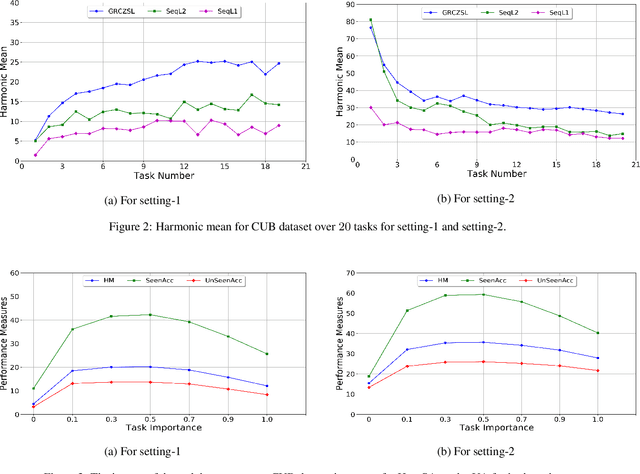
Zero-shot learning is a new paradigm to classify objects from classes that are not available at training time. Zero-shot learning (ZSL) methods have attracted considerable attention in recent years because of their ability to classify unseen/novel class examples. Most of the existing approaches on ZSL works when all the samples from seen classes are available to train the model, which does not suit real life. In this paper, we tackle this hindrance by developing a generative replay-based continual ZSL (GRCZSL). The proposed method endows traditional ZSL to learn from streaming data and acquire new knowledge without forgetting the previous tasks' gained experience. We handle catastrophic forgetting in GRCZSL by replaying the synthetic samples of seen classes, which have appeared in the earlier tasks. These synthetic samples are synthesized using the trained conditional variational autoencoder (VAE) over the immediate past task. Moreover, we only require the current and immediate previous VAE at any time for training and testing. The proposed GRZSL method is developed for a single-head setting of continual learning, simulating a real-world problem setting. In this setting, task identity is given during training but unavailable during testing. GRCZSL performance is evaluated on five benchmark datasets for the generalized setup of ZSL with fixed and incremental class settings of continual learning. Experimental results show that the proposed method significantly outperforms the baseline method and makes it more suitable for real-world applications.
Generalized Continual Zero-Shot Learning
Nov 17, 2020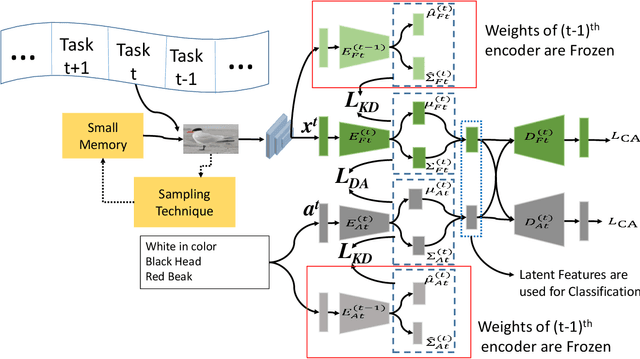
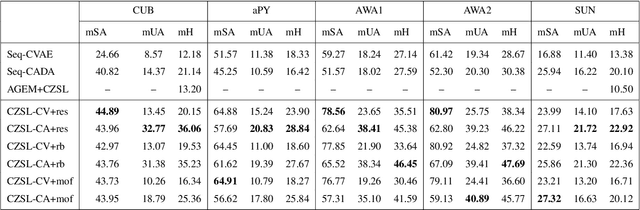
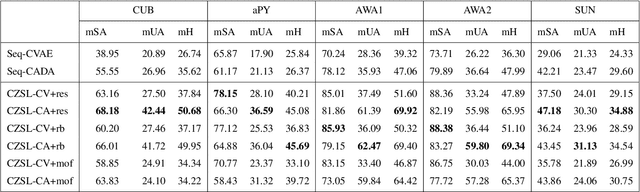
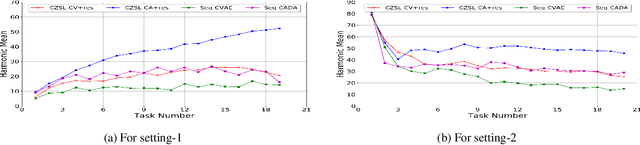
Recently, zero-shot learning (ZSL) emerged as an exciting topic and attracted a lot of attention. ZSL aims to classify unseen classes by transferring the knowledge from seen classes to unseen classes based on the class description. Despite showing promising performance, ZSL approaches assume that the training samples from all seen classes are available during the training, which is practically not feasible. To address this issue, we propose a more generalized and practical setup for ZSL, i.e., continual ZSL (CZSL), where classes arrive sequentially in the form of a task and it actively learns from the changing environment by leveraging the past experience. Further, to enhance the reliability, we develop CZSL for a single head continual learning setting where task identity is revealed during the training process but not during the testing. To avoid catastrophic forgetting and intransigence, we use knowledge distillation and storing and replay the few samples from previous tasks using a small episodic memory. We develop baselines and evaluate generalized CZSL on five ZSL benchmark datasets for two different settings of continual learning: with and without class incremental. Moreover, CZSL is developed for two types of variational autoencoders, which generates two types of features for classification: (i) generated features at output space and (ii) generated discriminative features at the latent space. The experimental results clearly indicate the single head CZSL is more generalizable and suitable for practical applications.
Towards Zero-Shot Learning with Fewer Seen Class Examples
Nov 14, 2020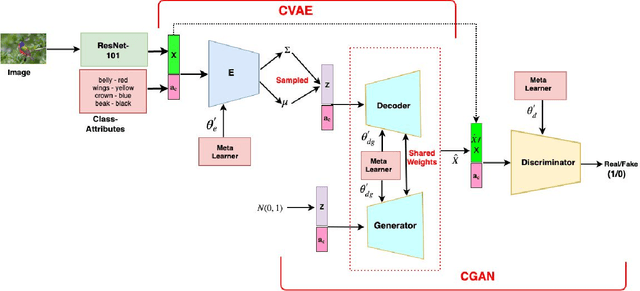
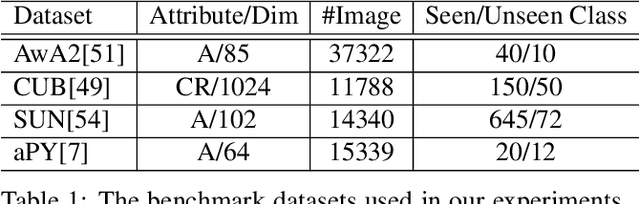
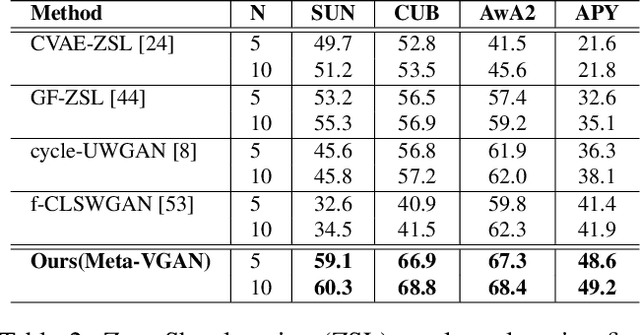
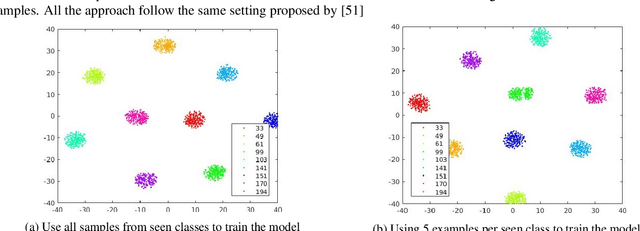
We present a meta-learning based generative model for zero-shot learning (ZSL) towards a challenging setting when the number of training examples from each \emph{seen} class is very few. This setup contrasts with the conventional ZSL approaches, where training typically assumes the availability of a sufficiently large number of training examples from each of the seen classes. The proposed approach leverages meta-learning to train a deep generative model that integrates variational autoencoder and generative adversarial networks. We propose a novel task distribution where meta-train and meta-validation classes are disjoint to simulate the ZSL behaviour in training. Once trained, the model can generate synthetic examples from seen and unseen classes. Synthesize samples can then be used to train the ZSL framework in a supervised manner. The meta-learner enables our model to generates high-fidelity samples using only a small number of training examples from seen classes. We conduct extensive experiments and ablation studies on four benchmark datasets of ZSL and observe that the proposed model outperforms state-of-the-art approaches by a significant margin when the number of examples per seen class is very small.
Fuzzy Unique Image Transformation: Defense Against Adversarial Attacks On Deep COVID-19 Models
Sep 08, 2020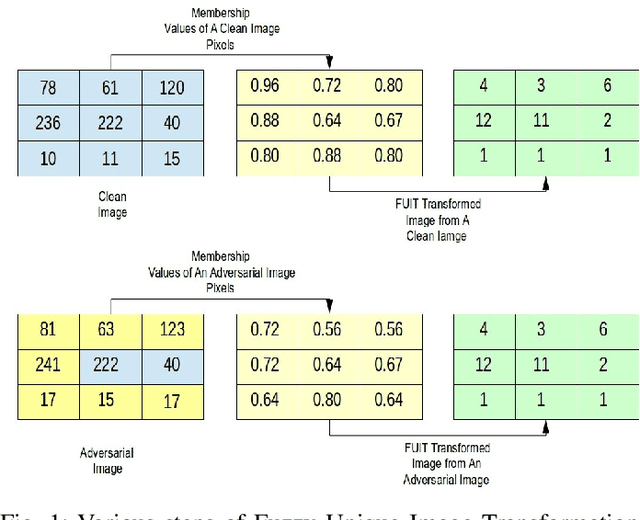
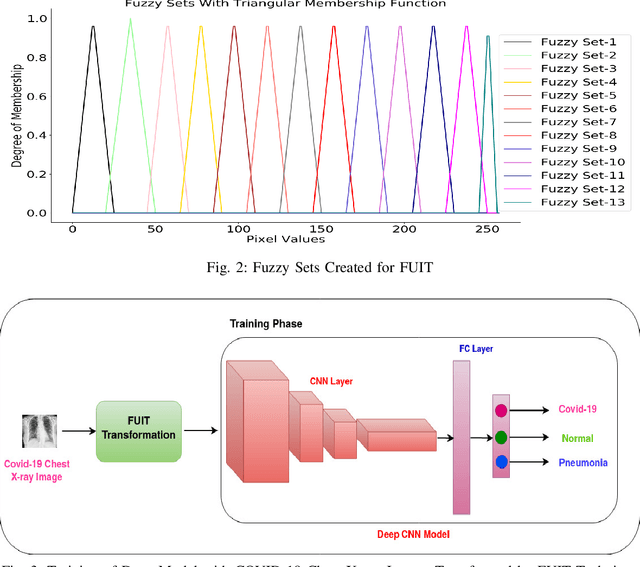
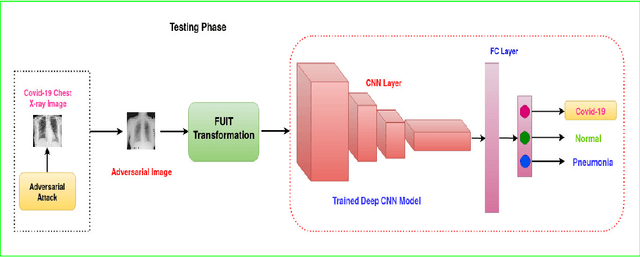
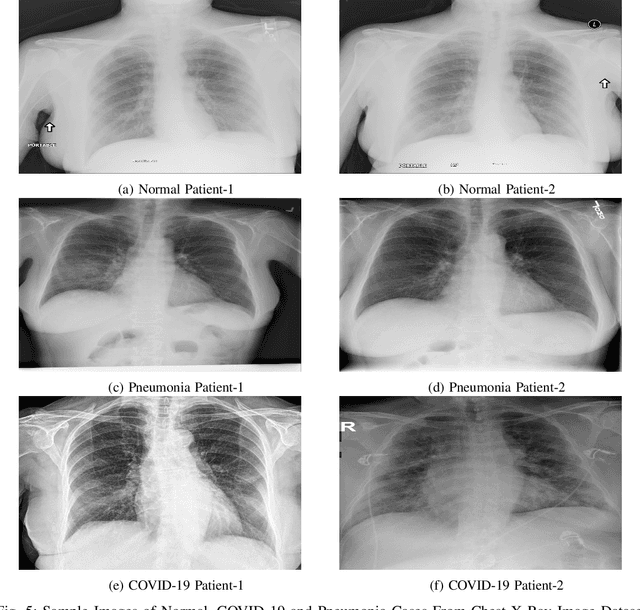
Early identification of COVID-19 using a deep model trained on Chest X-Ray and CT images has gained considerable attention from researchers to speed up the process of identification of active COVID-19 cases. These deep models act as an aid to hospitals that suffer from the unavailability of specialists or radiologists, specifically in remote areas. Various deep models have been proposed to detect the COVID-19 cases, but few works have been performed to prevent the deep models against adversarial attacks capable of fooling the deep model by using a small perturbation in image pixels. This paper presents an evaluation of the performance of deep COVID-19 models against adversarial attacks. Also, it proposes an efficient yet effective Fuzzy Unique Image Transformation (FUIT) technique that downsamples the image pixels into an interval. The images obtained after the FUIT transformation are further utilized for training the secure deep model that preserves high accuracy of the diagnosis of COVID-19 cases and provides reliable defense against the adversarial attacks. The experiments and results show the proposed model prevents the deep model against the six adversarial attacks and maintains high accuracy to classify the COVID-19 cases from the Chest X-Ray image and CT image Datasets. The results also recommend that a careful inspection is required before practically applying the deep models to diagnose the COVID-19 cases.
Stacked Adversarial Network for Zero-Shot Sketch based Image Retrieval
Jan 18, 2020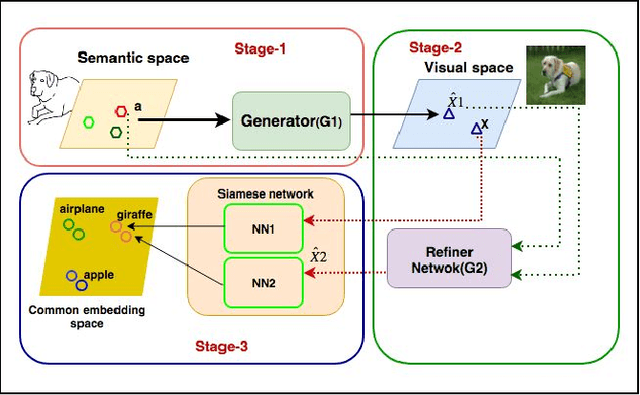
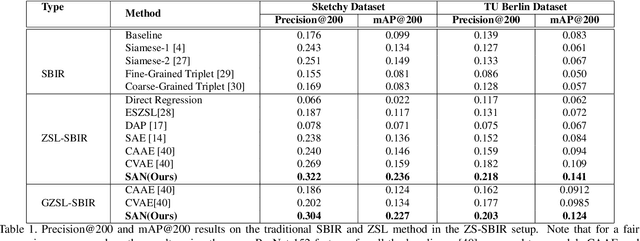
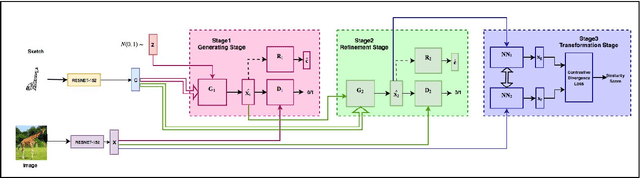
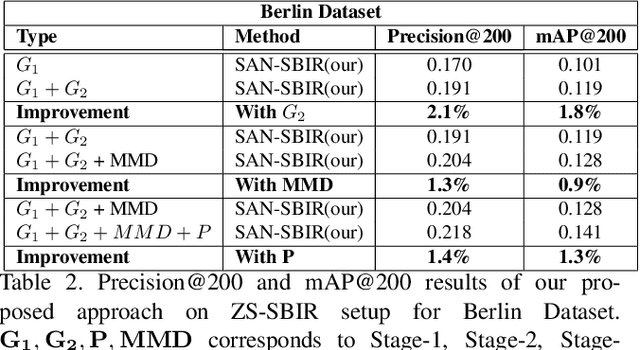
Conventional approaches to Sketch-Based Image Retrieval (SBIR) assume that the data of all the classes are available during training. The assumption may not always be practical since the data of a few classes may be unavailable, or the classes may not appear at the time of training. Zero-Shot Sketch-Based Image Retrieval (ZS-SBIR) relaxes this constraint and allows the algorithm to handle previously unseen classes during the test. This paper proposes a generative approach based on the Stacked Adversarial Network (SAN) and the advantage of Siamese Network (SN) for ZS-SBIR. While SAN generates a high-quality sample, SN learns a better distance metric compared to that of the nearest neighbor search. The capability of the generative model to synthesize image features based on the sketch reduces the SBIR problem to that of an image-to-image retrieval problem. We evaluate the efficacy of our proposed approach on TU-Berlin, and Sketchy database in both standard ZSL and generalized ZSL setting. The proposed method yields a significant improvement in standard ZSL as well as in a more challenging generalized ZSL setting (GZSL) for SBIR.
Generative Model for Zero-Shot Sketch-Based Image Retrieval
Apr 18, 2019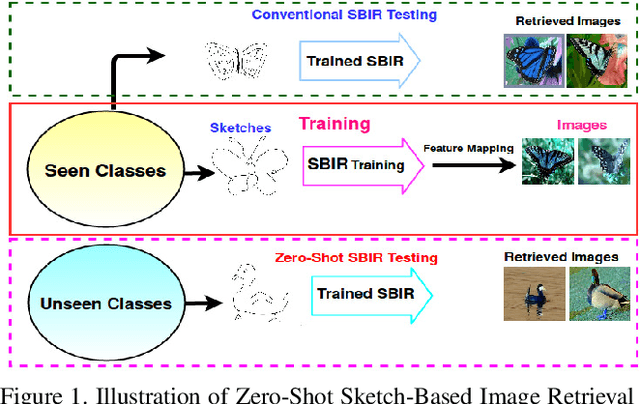
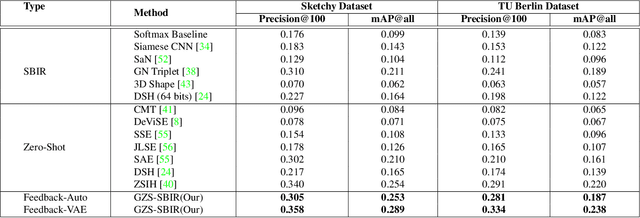
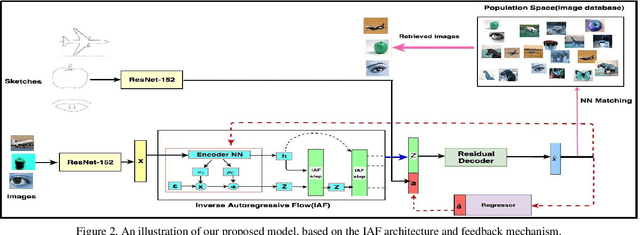
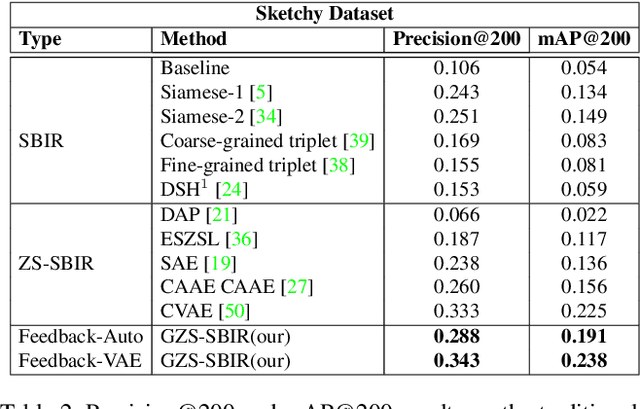
We present a probabilistic model for Sketch-Based Image Retrieval (SBIR) where, at retrieval time, we are given sketches from novel classes, that were not present at training time. Existing SBIR methods, most of which rely on learning class-wise correspondences between sketches and images, typically work well only for previously seen sketch classes, and result in poor retrieval performance on novel classes. To address this, we propose a generative model that learns to generate images, conditioned on a given novel class sketch. This enables us to reduce the SBIR problem to a standard image-to-image search problem. Our model is based on an inverse auto-regressive flow based variational autoencoder, with a feedback mechanism to ensure robust image generation. We evaluate our model on two very challenging datasets, Sketchy, and TU Berlin, with novel train-test split. The proposed approach significantly outperforms various baselines on both the datasets.