 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDB2-TransF: All You Need Is Learnable Daubechies Wavelets for Time Series Forecasting
Dec 10, 2025Time series forecasting requires models that can efficiently capture complex temporal dependencies, especially in large-scale and high-dimensional settings. While Transformer-based architectures excel at modeling long-range dependencies, their quadratic computational complexity poses limitations on scalability and adaptability. To overcome these challenges, we introduce DB2-TransF, a novel Transformer-inspired architecture that replaces the self-attention mechanism with a learnable Daubechies wavelet coefficient layer. This wavelet-based module efficiently captures multi-scale local and global patterns and enhances the modeling of correlations across multiple time series for the time series forecasting task. Extensive experiments on 13 standard forecasting benchmarks demonstrate that DB2-TransF achieves comparable or superior predictive accuracy to conventional Transformers, while substantially reducing memory usage for the time series forecasting task. The obtained experimental results position DB2-TransF as a scalable and resource-efficient framework for advanced time series forecasting. Our code is available at https://github.com/SteadySurfdom/DB2-TransF
BadScan: An Architectural Backdoor Attack on Visual State Space Models
Nov 26, 2024The newly introduced Visual State Space Model (VMamba), which employs \textit{State Space Mechanisms} (SSM) to interpret images as sequences of patches, has shown exceptional performance compared to Vision Transformers (ViT) across various computer vision tasks. However, recent studies have highlighted that deep models are susceptible to adversarial attacks. One common approach is to embed a trigger in the training data to retrain the model, causing it to misclassify data samples into a target class, a phenomenon known as a backdoor attack. In this paper, we first evaluate the robustness of the VMamba model against existing backdoor attacks. Based on this evaluation, we introduce a novel architectural backdoor attack, termed BadScan, designed to deceive the VMamba model. This attack utilizes bit plane slicing to create visually imperceptible backdoored images. During testing, if a trigger is detected by performing XOR operations between the $k^{th}$ bit planes of the modified triggered patches, the traditional 2D selective scan (SS2D) mechanism in the visual state space (VSS) block of VMamba is replaced with our newly designed BadScan block, which incorporates four newly developed scanning patterns. We demonstrate that the BadScan backdoor attack represents a significant threat to visual state space models and remains effective even after complete retraining from scratch. Experimental results on two widely used image classification datasets, CIFAR-10, and ImageNet-1K, reveal that while visual state space models generally exhibit robustness against current backdoor attacks, the BadScan attack is particularly effective, achieving a higher Triggered Accuracy Ratio (TAR) in misleading the VMamba model and its variants.
TM-PATHVQA:90000+ Textless Multilingual Questions for Medical Visual Question Answering
Jul 16, 2024In healthcare and medical diagnostics, Visual Question Answering (VQA) mayemergeasapivotal tool in scenarios where analysis of intricate medical images becomes critical for accurate diagnoses. Current text-based VQA systems limit their utility in scenarios where hands-free interaction and accessibility are crucial while performing tasks. A speech-based VQA system may provide a better means of interaction where information can be accessed while performing tasks simultaneously. To this end, this work implements a speech-based VQA system by introducing a Textless Multilingual Pathological VQA (TMPathVQA) dataset, an expansion of the PathVQA dataset, containing spoken questions in English, German & French. This dataset comprises 98,397 multilingual spoken questions and answers based on 5,004 pathological images along with 70 hours of audio. Finally, this work benchmarks and compares TMPathVQA systems implemented using various combinations of acoustic and visual features.
Fuzzy Unique Image Transformation: Defense Against Adversarial Attacks On Deep COVID-19 Models
Sep 08, 2020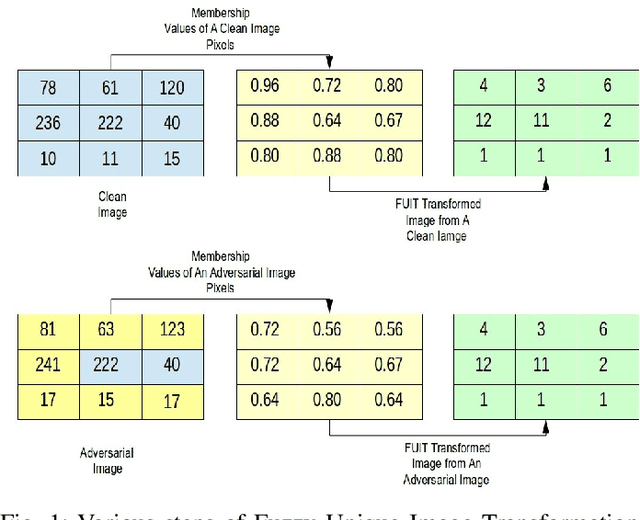
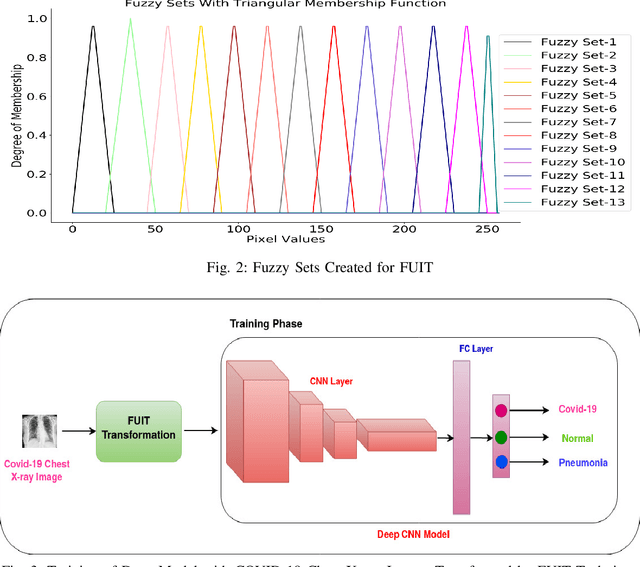
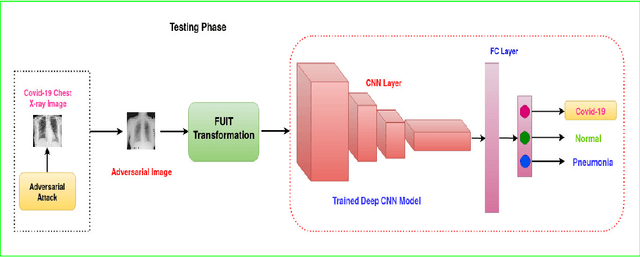
Early identification of COVID-19 using a deep model trained on Chest X-Ray and CT images has gained considerable attention from researchers to speed up the process of identification of active COVID-19 cases. These deep models act as an aid to hospitals that suffer from the unavailability of specialists or radiologists, specifically in remote areas. Various deep models have been proposed to detect the COVID-19 cases, but few works have been performed to prevent the deep models against adversarial attacks capable of fooling the deep model by using a small perturbation in image pixels. This paper presents an evaluation of the performance of deep COVID-19 models against adversarial attacks. Also, it proposes an efficient yet effective Fuzzy Unique Image Transformation (FUIT) technique that downsamples the image pixels into an interval. The images obtained after the FUIT transformation are further utilized for training the secure deep model that preserves high accuracy of the diagnosis of COVID-19 cases and provides reliable defense against the adversarial attacks. The experiments and results show the proposed model prevents the deep model against the six adversarial attacks and maintains high accuracy to classify the COVID-19 cases from the Chest X-Ray image and CT image Datasets. The results also recommend that a careful inspection is required before practically applying the deep models to diagnose the COVID-19 cases.