 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Vision-Language Models on Optical Character Recognition in Dynamic Video Environments
Feb 10, 2025


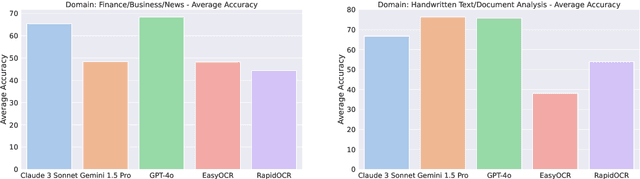
This paper introduces an open-source benchmark for evaluating Vision-Language Models (VLMs) on Optical Character Recognition (OCR) tasks in dynamic video environments. We present a curated dataset containing 1,477 manually annotated frames spanning diverse domains, including code editors, news broadcasts, YouTube videos, and advertisements. Three state of the art VLMs - Claude-3, Gemini-1.5, and GPT-4o are benchmarked against traditional OCR systems such as EasyOCR and RapidOCR. Evaluation metrics include Word Error Rate (WER), Character Error Rate (CER), and Accuracy. Our results highlight the strengths and limitations of VLMs in video-based OCR tasks, demonstrating their potential to outperform conventional OCR models in many scenarios. However, challenges such as hallucinations, content security policies, and sensitivity to occluded or stylized text remain. The dataset and benchmarking framework are publicly available to foster further research.
BadScan: An Architectural Backdoor Attack on Visual State Space Models
Nov 26, 2024The newly introduced Visual State Space Model (VMamba), which employs \textit{State Space Mechanisms} (SSM) to interpret images as sequences of patches, has shown exceptional performance compared to Vision Transformers (ViT) across various computer vision tasks. However, recent studies have highlighted that deep models are susceptible to adversarial attacks. One common approach is to embed a trigger in the training data to retrain the model, causing it to misclassify data samples into a target class, a phenomenon known as a backdoor attack. In this paper, we first evaluate the robustness of the VMamba model against existing backdoor attacks. Based on this evaluation, we introduce a novel architectural backdoor attack, termed BadScan, designed to deceive the VMamba model. This attack utilizes bit plane slicing to create visually imperceptible backdoored images. During testing, if a trigger is detected by performing XOR operations between the $k^{th}$ bit planes of the modified triggered patches, the traditional 2D selective scan (SS2D) mechanism in the visual state space (VSS) block of VMamba is replaced with our newly designed BadScan block, which incorporates four newly developed scanning patterns. We demonstrate that the BadScan backdoor attack represents a significant threat to visual state space models and remains effective even after complete retraining from scratch. Experimental results on two widely used image classification datasets, CIFAR-10, and ImageNet-1K, reveal that while visual state space models generally exhibit robustness against current backdoor attacks, the BadScan attack is particularly effective, achieving a higher Triggered Accuracy Ratio (TAR) in misleading the VMamba model and its variants.
TM-PATHVQA:90000+ Textless Multilingual Questions for Medical Visual Question Answering
Jul 16, 2024In healthcare and medical diagnostics, Visual Question Answering (VQA) mayemergeasapivotal tool in scenarios where analysis of intricate medical images becomes critical for accurate diagnoses. Current text-based VQA systems limit their utility in scenarios where hands-free interaction and accessibility are crucial while performing tasks. A speech-based VQA system may provide a better means of interaction where information can be accessed while performing tasks simultaneously. To this end, this work implements a speech-based VQA system by introducing a Textless Multilingual Pathological VQA (TMPathVQA) dataset, an expansion of the PathVQA dataset, containing spoken questions in English, German & French. This dataset comprises 98,397 multilingual spoken questions and answers based on 5,004 pathological images along with 70 hours of audio. Finally, this work benchmarks and compares TMPathVQA systems implemented using various combinations of acoustic and visual features.