 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Vision-Language Models on Optical Character Recognition in Dynamic Video Environments
Feb 10, 2025


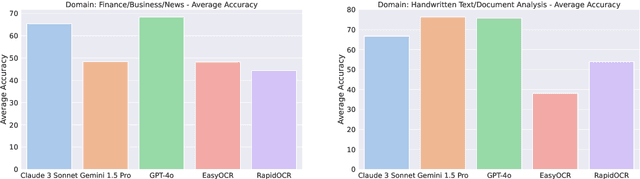
This paper introduces an open-source benchmark for evaluating Vision-Language Models (VLMs) on Optical Character Recognition (OCR) tasks in dynamic video environments. We present a curated dataset containing 1,477 manually annotated frames spanning diverse domains, including code editors, news broadcasts, YouTube videos, and advertisements. Three state of the art VLMs - Claude-3, Gemini-1.5, and GPT-4o are benchmarked against traditional OCR systems such as EasyOCR and RapidOCR. Evaluation metrics include Word Error Rate (WER), Character Error Rate (CER), and Accuracy. Our results highlight the strengths and limitations of VLMs in video-based OCR tasks, demonstrating their potential to outperform conventional OCR models in many scenarios. However, challenges such as hallucinations, content security policies, and sensitivity to occluded or stylized text remain. The dataset and benchmarking framework are publicly available to foster further research.