 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$P^2$GNN: Two Prototype Sets to boost GNN Performance
Mar 10, 2026Message Passing Graph Neural Networks (MP-GNNs) have garnered attention for addressing various industry challenges, such as user recommendation and fraud detection. However, they face two major hurdles: (1) heavy reliance on local context, often lacking information about the global context or graph-level features, and (2) assumption of strong homophily among connected nodes, struggling with noisy local neighborhoods. To tackle these, we introduce $P^2$GNN, a plug-and-play technique leveraging prototypes to optimize message passing, enhancing the performance of the base GNN model. Our approach views the prototypes in two ways: (1) as universally accessible neighbors for all nodes, enriching global context, and (2) aligning messages to clustered prototypes, offering a denoising effect. We demonstrate the extensibility of our proposed method to all message-passing GNNs and conduct extensive experiments across 18 datasets, including proprietary e-commerce datasets and open-source datasets, on node recommendation and node classification tasks. Results show that $P^2$GNN outperforms production models in e-commerce and achieves the top average rank on open-source datasets, establishing it as a leading approach. Qualitative analysis supports the value of global context and noise mitigation in the local neighborhood in enhancing performance.
Leveraging Uncertainty Estimates To Improve Classifier Performance
Nov 20, 2023Binary classification involves predicting the label of an instance based on whether the model score for the positive class exceeds a threshold chosen based on the application requirements (e.g., maximizing recall for a precision bound). However, model scores are often not aligned with the true positivity rate. This is especially true when the training involves a differential sampling across classes or there is distributional drift between train and test settings. In this paper, we provide theoretical analysis and empirical evidence of the dependence of model score estimation bias on both uncertainty and score itself. Further, we formulate the decision boundary selection in terms of both model score and uncertainty, prove that it is NP-hard, and present algorithms based on dynamic programming and isotonic regression. Evaluation of the proposed algorithms on three real-world datasets yield 25%-40% gain in recall at high precision bounds over the traditional approach of using model score alone, highlighting the benefits of leveraging uncertainty.
Small-Variance Asymptotics for Nonparametric Bayesian Overlapping Stochastic Blockmodels
Jul 10, 2018
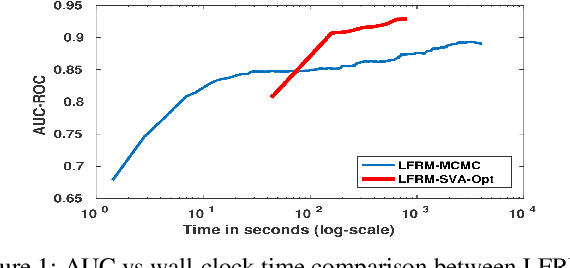

The latent feature relational model (LFRM) is a generative model for graph-structured data to learn a binary vector representation for each node in the graph. The binary vector denotes the node's membership in one or more communities. At its core, the LFRM miller2009nonparametric is an overlapping stochastic blockmodel, which defines the link probability between any pair of nodes as a bilinear function of their community membership vectors. Moreover, using a nonparametric Bayesian prior (Indian Buffet Process) enables learning the number of communities automatically from the data. However, despite its appealing properties, inference in LFRM remains a challenge and is typically done via MCMC methods. This can be slow and may take a long time to converge. In this work, we develop a small-variance asymptotics based framework for the non-parametric Bayesian LFRM. This leads to an objective function that retains the nonparametric Bayesian flavor of LFRM, while enabling us to design deterministic inference algorithms for this model, that are easy to implement (using generic or specialized optimization routines) and are fast in practice. Our results on several benchmark datasets demonstrate that our algorithm is competitive to methods such as MCMC, while being much faster.
Generalized Zero-Shot Learning via Synthesized Examples
Jun 12, 2018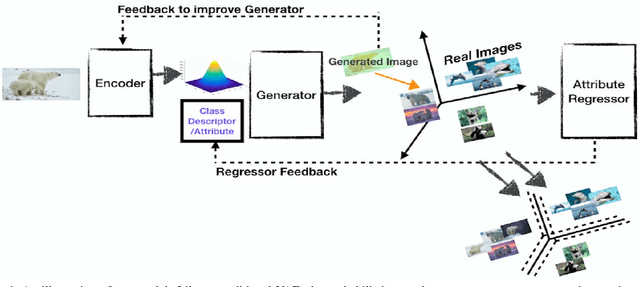
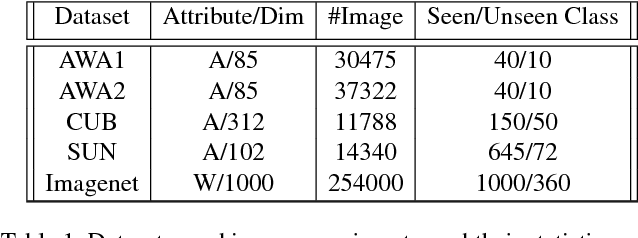

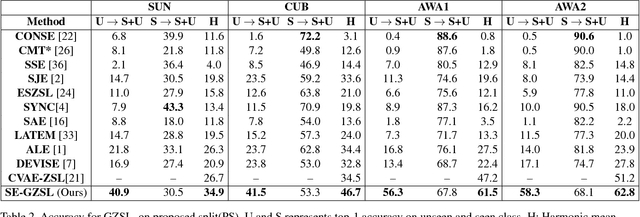
We present a generative framework for generalized zero-shot learning where the training and test classes are not necessarily disjoint. Built upon a variational autoencoder based architecture, consisting of a probabilistic encoder and a probabilistic conditional decoder, our model can generate novel exemplars from seen/unseen classes, given their respective class attributes. These exemplars can subsequently be used to train any off-the-shelf classification model. One of the key aspects of our encoder-decoder architecture is a feedback-driven mechanism in which a discriminator (a multivariate regressor) learns to map the generated exemplars to the corresponding class attribute vectors, leading to an improved generator. Our model's ability to generate and leverage examples from unseen classes to train the classification model naturally helps to mitigate the bias towards predicting seen classes in generalized zero-shot learning settings. Through a comprehensive set of experiments, we show that our model outperforms several state-of-the-art methods, on several benchmark datasets, for both standard as well as generalized zero-shot learning.