 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse In-Context Example Selection After Decomposing Programs and Aligned Utterances Improves Semantic Parsing
Apr 04, 2025LLMs are increasingly used as seq2seq translators from natural language utterances to structured programs, a process called semantic interpretation. Unlike atomic labels or token sequences, programs are naturally represented as abstract syntax trees (ASTs). Such structured representation raises novel issues related to the design and selection of in-context examples (ICEs) presented to the LLM. We focus on decomposing the pool of available ICE trees into fragments, some of which may be better suited to solving the test instance. Next, we propose how to use (additional invocations of) an LLM with prompted syntax constraints to automatically map the fragments to corresponding utterances. Finally, we adapt and extend a recent method for diverse ICE selection to work with whole and fragmented ICE instances. We evaluate our system, SCUD4ICL, on popular diverse semantic parsing benchmarks, showing visible accuracy gains from our proposed decomposed diverse demonstration method. Benefits are particularly notable for smaller LLMs, ICE pools having larger labeled trees, and programs in lower resource languages.
Towards Robust Knowledge Representations in Multilingual LLMs for Equivalence and Inheritance based Consistent Reasoning
Oct 18, 2024Reasoning and linguistic skills form the cornerstone of human intelligence, facilitating problem-solving and decision-making. Recent advances in Large Language Models (LLMs) have led to impressive linguistic capabilities and emergent reasoning behaviors, fueling widespread adoption across application domains. However, LLMs still struggle with complex reasoning tasks, highlighting their systemic limitations. In this work, we focus on evaluating whether LLMs have the requisite representations to reason using two foundational relationships: "equivalence" and "inheritance". We introduce novel tasks and benchmarks spanning six languages and observe that current SOTA LLMs often produce conflicting answers to the same questions across languages in 17.3-57.5% of cases and violate inheritance constraints in up to 37.2% cases. To enhance consistency across languages, we propose novel "Compositional Representations" where tokens are represented as composition of equivalent tokens across languages, with resulting conflict reduction (up to -4.7%) indicating benefits of shared LLM representations.
Intent Detection in the Age of LLMs
Oct 02, 2024Intent detection is a critical component of task-oriented dialogue systems (TODS) which enables the identification of suitable actions to address user utterances at each dialog turn. Traditional approaches relied on computationally efficient supervised sentence transformer encoder models, which require substantial training data and struggle with out-of-scope (OOS) detection. The emergence of generative large language models (LLMs) with intrinsic world knowledge presents new opportunities to address these challenges. In this work, we adapt 7 SOTA LLMs using adaptive in-context learning and chain-of-thought prompting for intent detection, and compare their performance with contrastively fine-tuned sentence transformer (SetFit) models to highlight prediction quality and latency tradeoff. We propose a hybrid system using uncertainty based routing strategy to combine the two approaches that along with negative data augmentation results in achieving the best of both worlds ( i.e. within 2% of native LLM accuracy with 50% less latency). To better understand LLM OOS detection capabilities, we perform controlled experiments revealing that this capability is significantly influenced by the scope of intent labels and the size of the label space. We also introduce a two-step approach utilizing internal LLM representations, demonstrating empirical gains in OOS detection accuracy and F1-score by >5% for the Mistral-7B model.
Leveraging Uncertainty Estimates To Improve Classifier Performance
Nov 20, 2023Binary classification involves predicting the label of an instance based on whether the model score for the positive class exceeds a threshold chosen based on the application requirements (e.g., maximizing recall for a precision bound). However, model scores are often not aligned with the true positivity rate. This is especially true when the training involves a differential sampling across classes or there is distributional drift between train and test settings. In this paper, we provide theoretical analysis and empirical evidence of the dependence of model score estimation bias on both uncertainty and score itself. Further, we formulate the decision boundary selection in terms of both model score and uncertainty, prove that it is NP-hard, and present algorithms based on dynamic programming and isotonic regression. Evaluation of the proposed algorithms on three real-world datasets yield 25%-40% gain in recall at high precision bounds over the traditional approach of using model score alone, highlighting the benefits of leveraging uncertainty.
Interpretability of Epidemiological Models : The Curse of Non-Identifiability
Apr 30, 2021
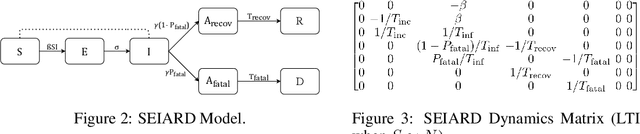


Interpretability of epidemiological models is a key consideration, especially when these models are used in a public health setting. Interpretability is strongly linked to the identifiability of the underlying model parameters, i.e., the ability to estimate parameter values with high confidence given observations. In this paper, we define three separate notions of identifiability that explore the different roles played by the model definition, the loss function, the fitting methodology, and the quality and quantity of data. We define an epidemiological compartmental model framework in which we highlight these non-identifiability issues and their mitigation.
COVID-19: Strategies for Allocation of Test Kits
Apr 03, 2020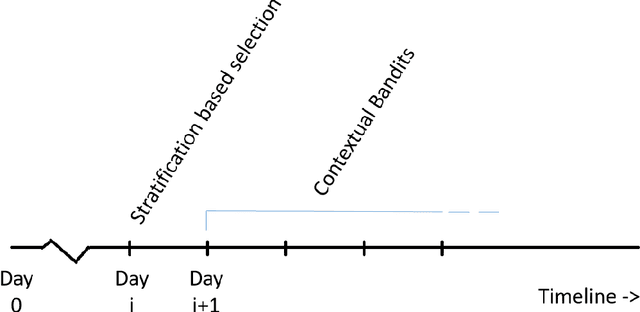
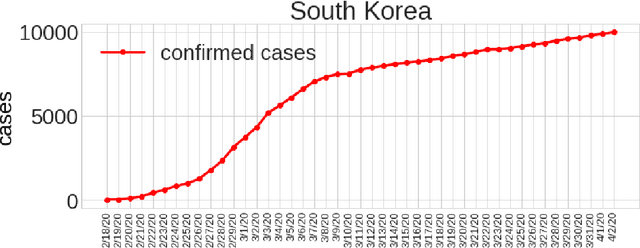
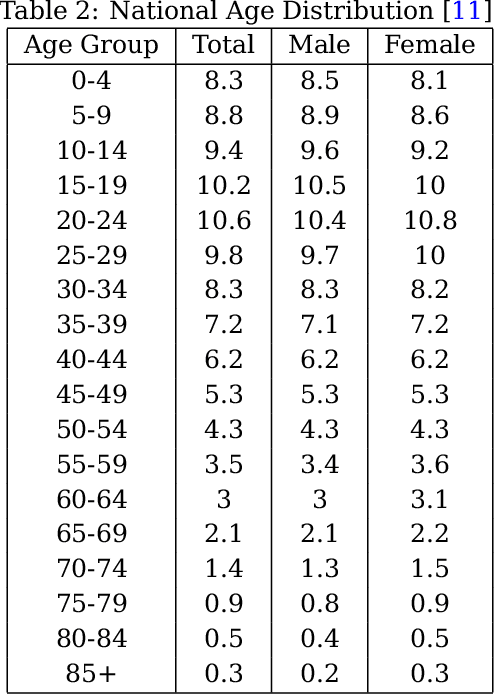
With the increasing spread of COVID-19, it is important to systematically test more and more people. The current strategy for test-kit allocation is mostly rule-based, focusing on individuals having (a) symptoms for COVID-19, (b) travel history or (c) contact history with confirmed COVID-19 patients. Such testing strategy may miss out on detecting asymptomatic individuals who got infected via community spread. Thus, it is important to allocate a separate budget of test-kits per day targeted towards preventing community spread and detecting new cases early on. In this report, we consider the problem of allocating test-kits and discuss some solution approaches. We believe that these approaches will be useful to contain community spread and detect new cases early on. Additionally, these approaches would help in collecting unbiased data which can then be used to improve the accuracy of machine learning models trained to predict COVID-19 infections.