 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELT: Elastic Looped Transformers for Visual Generation
Apr 13, 2026We introduce Elastic Looped Transformers (ELT), a highly parameter-efficient class of visual generative models based on a recurrent transformer architecture. While conventional generative models rely on deep stacks of unique transformer layers, our approach employs iterative, weight-shared transformer blocks to drastically reduce parameter counts while maintaining high synthesis quality. To effectively train these models for image and video generation, we propose the idea of Intra-Loop Self Distillation (ILSD), where student configurations (intermediate loops) are distilled from the teacher configuration (maximum training loops) to ensure consistency across the model's depth in a single training step. Our framework yields a family of elastic models from a single training run, enabling Any-Time inference capability with dynamic trade-offs between computational cost and generation quality, with the same parameter count. ELT significantly shifts the efficiency frontier for visual synthesis. With $4\times$ reduction in parameter count under iso-inference-compute settings, ELT achieves a competitive FID of $2.0$ on class-conditional ImageNet $256 \times 256$ and FVD of $72.8$ on class-conditional UCF-101.
Towards Building efficient Routed systems for Retrieval
Jan 10, 2026Late-interaction retrieval models like ColBERT achieve superior accuracy by enabling token-level interactions, but their computational cost hinders scalability and integration with Approximate Nearest Neighbor Search (ANNS). We introduce FastLane, a novel retrieval framework that dynamically routes queries to their most informative representations, eliminating redundant token comparisons. FastLane employs a learnable routing mechanism optimized alongside the embedding model, leveraging self-attention and differentiable selection to maximize efficiency. Our approach reduces computational complexity by up to 30x while maintaining competitive retrieval performance. By bridging late-interaction models with ANNS, FastLane enables scalable, low-latency retrieval, making it feasible for large-scale applications such as search engines, recommendation systems, and question-answering platforms. This work opens pathways for multi-lingual, multi-modal, and long-context retrieval, pushing the frontier of efficient and adaptive information retrieval.
Succeeding at Scale: Automated Multi-Retriever Fusion and Query-Side Adaptation for Multi-Tenant Search
Jan 08, 2026Large-scale multi-tenant retrieval systems amass vast user query logs yet critically lack the curated relevance labels required for effective domain adaptation. This "dark data" problem is exacerbated by the operational cost of model updates: jointly fine-tuning query and document encoders requires re-indexing the entire corpus, which is prohibitive in multi-tenant environments with thousands of isolated indices. To address these dual challenges, we introduce \textbf{DevRev Search}, a passage retrieval benchmark for technical customer support constructed through a fully automatic pipeline. We employ a \textbf{fusion-based candidate generation} strategy, pooling results from diverse sparse and dense retrievers, and utilize an LLM-as-a-Judge to perform rigorous \textbf{consistency filtering} and relevance assignment. We further propose a practical \textbf{Index-Preserving Adaptation} strategy: by fine-tuning only the query encoder via Low-Rank Adaptation (LoRA), we achieve competitive performance improvements while keeping the document index frozen. Our experiments on DevRev Search and SciFact demonstrate that targeting specific transformer layers in the query encoder yields optimal quality-efficiency trade-offs, offering a scalable path for personalized enterprise search.
Estimating Causal Effects in Gaussian Linear SCMs with Finite Data
Jan 08, 2026Estimating causal effects from observational data remains a fundamental challenge in causal inference, especially in the presence of latent confounders. This paper focuses on estimating causal effects in Gaussian Linear Structural Causal Models (GL-SCMs), which are widely used due to their analytical tractability. However, parameter estimation in GL-SCMs is often infeasible with finite data, primarily due to overparameterization. To address this, we introduce the class of Centralized Gaussian Linear SCMs (CGL-SCMs), a simplified yet expressive subclass where exogenous variables follow standardized distributions. We show that CGL-SCMs are equally expressive in terms of causal effect identifiability from observational distributions and present a novel EM-based estimation algorithm that can learn CGL-SCM parameters and estimate identifiable causal effects from finite observational samples. Our theoretical analysis is validated through experiments on synthetic data and benchmark causal graphs, demonstrating that the learned models accurately recover causal distributions.
AGGRNet: Selective Feature Extraction and Aggregation for Enhanced Medical Image Classification
Nov 15, 2025Medical image analysis for complex tasks such as severity grading and disease subtype classification poses significant challenges due to intricate and similar visual patterns among classes, scarcity of labeled data, and variability in expert interpretations. Despite the usefulness of existing attention-based models in capturing complex visual patterns for medical image classification, underlying architectures often face challenges in effectively distinguishing subtle classes since they struggle to capture inter-class similarity and intra-class variability, resulting in incorrect diagnosis. To address this, we propose AGGRNet framework to extract informative and non-informative features to effectively understand fine-grained visual patterns and improve classification for complex medical image analysis tasks. Experimental results show that our model achieves state-of-the-art performance on various medical imaging datasets, with the best improvement up to 5% over SOTA models on the Kvasir dataset.
Spark Transformer: Reactivating Sparsity in FFN and Attention
Jun 07, 2025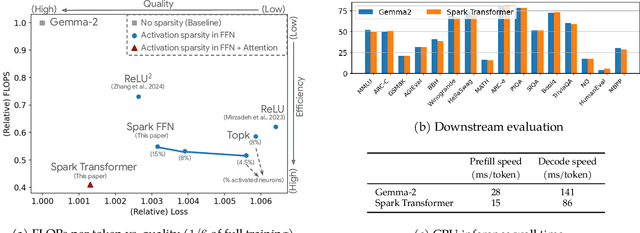
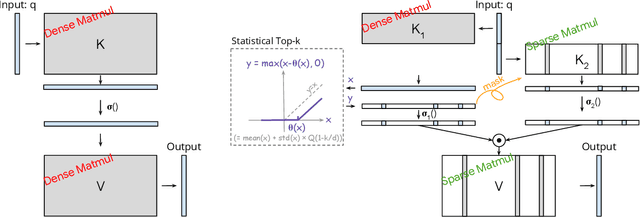
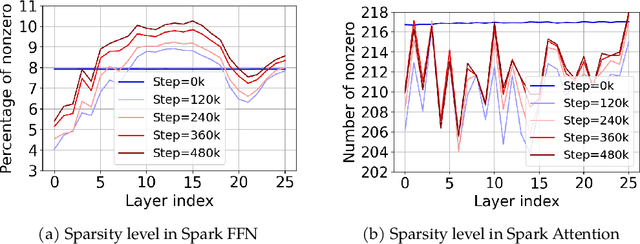
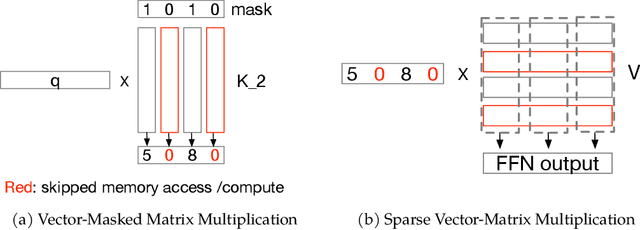
The discovery of the lazy neuron phenomenon in trained Transformers, where the vast majority of neurons in their feed-forward networks (FFN) are inactive for each token, has spurred tremendous interests in activation sparsity for enhancing large model efficiency. While notable progress has been made in translating such sparsity to wall-time benefits, modern Transformers have moved away from the ReLU activation function crucial to this phenomenon. Existing efforts on re-introducing activation sparsity often degrade model quality, increase parameter count, complicate or slow down training. Sparse attention, the application of sparse activation to the attention mechanism, often faces similar challenges. This paper introduces the Spark Transformer, a novel architecture that achieves a high level of activation sparsity in both FFN and the attention mechanism while maintaining model quality, parameter count, and standard training procedures. Our method realizes sparsity via top-k masking for explicit control over sparsity level. Crucially, we introduce statistical top-k, a hardware-accelerator-friendly, linear-time approximate algorithm that avoids costly sorting and mitigates significant training slowdown from standard top-$k$ operators. Furthermore, Spark Transformer reallocates existing FFN parameters and attention key embeddings to form a low-cost predictor for identifying activated entries. This design not only mitigates quality loss from enforced sparsity, but also enhances wall-time benefit. Pretrained with the Gemma-2 recipe, Spark Transformer demonstrates competitive performance on standard benchmarks while exhibiting significant sparsity: only 8% of FFN neurons are activated, and each token attends to a maximum of 256 tokens. This sparsity translates to a 2.5x reduction in FLOPs, leading to decoding wall-time speedups of up to 1.79x on CPU and 1.40x on GPU.
Faster Approx. Top-K: Harnessing the Full Power of Two Stages
Jun 05, 2025We consider the Top-$K$ selection problem, which aims to identify the largest-$K$ elements from an array. Top-$K$ selection arises in many machine learning algorithms and often becomes a bottleneck on accelerators, which are optimized for dense matrix multiplications. To address this problem, \citet{chern2022tpuknnknearestneighbor} proposed a fast two-stage \textit{approximate} Top-$K$ algorithm: (i) partition the input array and select the top-$1$ element from each partition, (ii) sort this \textit{smaller subset} and return the top $K$ elements. In this paper, we consider a generalized version of this algorithm, where the first stage selects top-$K'$ elements, for some $1 \leq K' \leq K$, from each partition. Our contributions are as follows: (i) we derive an expression for the expected recall of this generalized algorithm and show that choosing $K' > 1$ with fewer partitions in the first stage reduces the input size to the second stage more effectively while maintaining the same expected recall as the original algorithm, (ii) we derive a bound on the expected recall for the original algorithm in \citet{chern2022tpuknnknearestneighbor} that is provably tighter by a factor of $2$ than the one in that paper, and (iii) we implement our algorithm on Cloud TPUv5e and achieve around an order of magnitude speedups over the original algorithm without sacrificing recall on real-world tasks.
Matryoshka Model Learning for Improved Elastic Student Models
May 29, 2025Industry-grade ML models are carefully designed to meet rapidly evolving serving constraints, which requires significant resources for model development. In this paper, we propose MatTA, a framework for training multiple accurate Student models using a novel Teacher-TA-Student recipe. TA models are larger versions of the Student models with higher capacity, and thus allow Student models to better relate to the Teacher model and also bring in more domain-specific expertise. Furthermore, multiple accurate Student models can be extracted from the TA model. Therefore, despite only one training run, our methodology provides multiple servable options to trade off accuracy for lower serving cost. We demonstrate the proposed method, MatTA, on proprietary datasets and models. Its practical efficacy is underscored by live A/B tests within a production ML system, demonstrating 20% improvement on a key metric. We also demonstrate our method on GPT-2 Medium, a public model, and achieve relative improvements of over 24% on SAT Math and over 10% on the LAMBADA benchmark.
Efficient Single-Pass Training for Multi-Turn Reasoning
Apr 25, 2025



Training Large Language Models ( LLMs) to generate explicit reasoning before they produce an answer has been shown to improve their performance across various tasks such as mathematics and coding. However, fine-tuning LLMs on multi-turn reasoning datasets presents a unique challenge: LLMs must generate reasoning tokens that are excluded from subsequent inputs to the LLM. This discrepancy prevents us from processing an entire conversation in a single forward pass-an optimization readily available when we fine-tune on a multi-turn non-reasoning dataset. This paper proposes a novel approach that overcomes this limitation through response token duplication and a custom attention mask that enforces appropriate visibility constraints. Our approach significantly reduces the training time and allows efficient fine-tuning on multi-turn reasoning datasets.
Interleaved Gibbs Diffusion for Constrained Generation
Feb 19, 2025We introduce Interleaved Gibbs Diffusion (IGD), a novel generative modeling framework for mixed continuous-discrete data, focusing on constrained generation problems. Prior works on discrete and continuous-discrete diffusion models assume factorized denoising distribution for fast generation, which can hinder the modeling of strong dependencies between random variables encountered in constrained generation. IGD moves beyond this by interleaving continuous and discrete denoising algorithms via a discrete time Gibbs sampling type Markov chain. IGD provides flexibility in the choice of denoisers, allows conditional generation via state-space doubling and inference time scaling via the ReDeNoise method. Empirical evaluations on three challenging tasks-solving 3-SAT, generating molecule structures, and generating layouts-demonstrate state-of-the-art performance. Notably, IGD achieves a 7% improvement on 3-SAT out of the box and achieves state-of-the-art results in molecule generation without relying on equivariant diffusion or domain-specific architectures. We explore a wide range of modeling, and interleaving strategies along with hyperparameters in each of these problems.