 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLookupViT: Compressing visual information to a limited number of tokens
Paper and Code
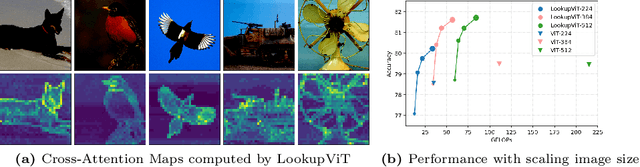
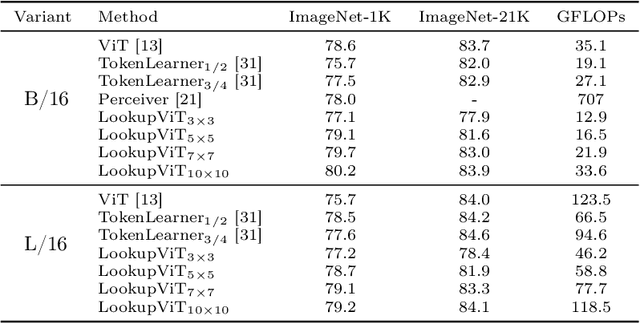
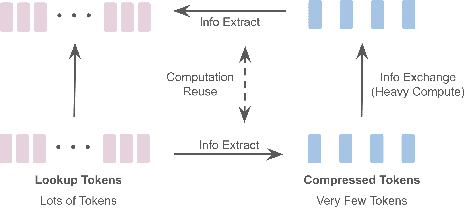
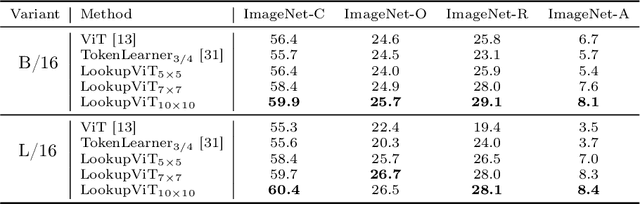
Vision Transformers (ViT) have emerged as the de-facto choice for numerous industry grade vision solutions. But their inference cost can be prohibitive for many settings, as they compute self-attention in each layer which suffers from quadratic computational complexity in the number of tokens. On the other hand, spatial information in images and spatio-temporal information in videos is usually sparse and redundant. In this work, we introduce LookupViT, that aims to exploit this information sparsity to reduce ViT inference cost. LookupViT provides a novel general purpose vision transformer block that operates by compressing information from higher resolution tokens to a fixed number of tokens. These few compressed tokens undergo meticulous processing, while the higher-resolution tokens are passed through computationally cheaper layers. Information sharing between these two token sets is enabled through a bidirectional cross-attention mechanism. The approach offers multiple advantages - (a) easy to implement on standard ML accelerators (GPUs/TPUs) via standard high-level operators, (b) applicable to standard ViT and its variants, thus generalizes to various tasks, (c) can handle different tokenization and attention approaches. LookupViT also offers flexibility for the compressed tokens, enabling performance-computation trade-offs in a single trained model. We show LookupViT's effectiveness on multiple domains - (a) for image-classification (ImageNet-1K and ImageNet-21K), (b) video classification (Kinetics400 and Something-Something V2), (c) image captioning (COCO-Captions) with a frozen encoder. LookupViT provides $2\times$ reduction in FLOPs while upholding or improving accuracy across these domains. In addition, LookupViT also demonstrates out-of-the-box robustness and generalization on image classification (ImageNet-C,R,A,O), improving by up to $4\%$ over ViT.