 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal2Global query Alignment for Video Instance Segmentation
Jul 27, 2025



Online video segmentation methods excel at handling long sequences and capturing gradual changes, making them ideal for real-world applications. However, achieving temporally consistent predictions remains a challenge, especially with gradual accumulation of noise or drift in on-line propagation, abrupt occlusions and scene transitions. This paper introduces Local2Global, an online framework, for video instance segmentation, exhibiting state-of-the-art performance with simple baseline and training purely in online fashion. Leveraging the DETR-based query propagation framework, we introduce two novel sets of queries:(1) local queries that capture initial object-specific spatial features from each frame and (2) global queries containing past spatio-temporal representations. We propose the L2G-aligner, a novel lightweight transformer decoder, to facilitate an early alignment between local and global queries. This alignment allows our model to effectively utilize current frame information while maintaining temporal consistency, producing a smooth transition between frames. Furthermore, L2G-aligner is integrated within the segmentation model, without relying on additional complex heuristics, or memory mechanisms. Extensive experiments across various challenging VIS and VPS datasets showcase the superiority of our method with simple online training, surpassing current benchmarks without bells and rings. For instance, we achieve 54.3 and 49.4 AP on Youtube-VIS-19/-21 datasets and 37.0 AP on OVIS dataset respectively withthe ResNet-50 backbone.
Perceive, Query & Reason: Enhancing Video QA with Question-Guided Temporal Queries
Dec 26, 2024



Video Question Answering (Video QA) is a challenging video understanding task that requires models to comprehend entire videos, identify the most relevant information based on contextual cues from a given question, and reason accurately to provide answers. Recent advancements in Multimodal Large Language Models (MLLMs) have transformed video QA by leveraging their exceptional commonsense reasoning capabilities. This progress is largely driven by the effective alignment between visual data and the language space of MLLMs. However, for video QA, an additional space-time alignment poses a considerable challenge for extracting question-relevant information across frames. In this work, we investigate diverse temporal modeling techniques to integrate with MLLMs, aiming to achieve question-guided temporal modeling that leverages pre-trained visual and textual alignment in MLLMs. We propose T-Former, a novel temporal modeling method that creates a question-guided temporal bridge between frame-wise visual perception and the reasoning capabilities of LLMs. Our evaluation across multiple video QA benchmarks demonstrates that T-Former competes favorably with existing temporal modeling approaches and aligns with recent advancements in video QA.
LookupViT: Compressing visual information to a limited number of tokens
Jul 17, 2024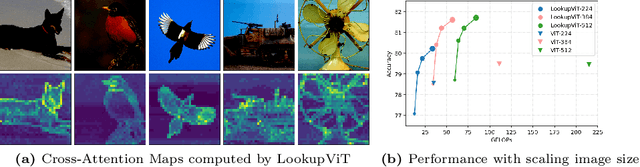
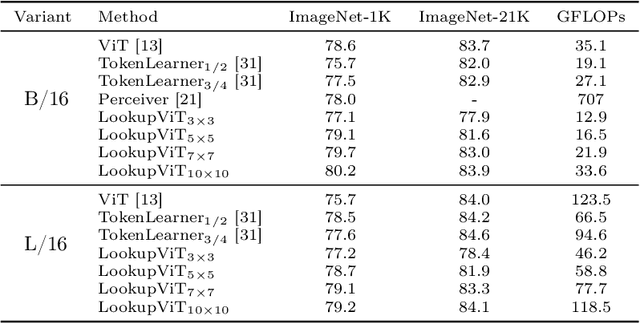
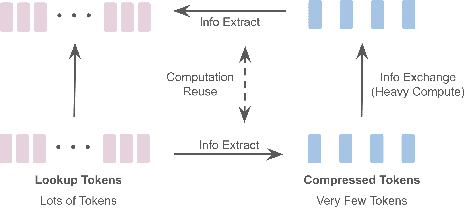
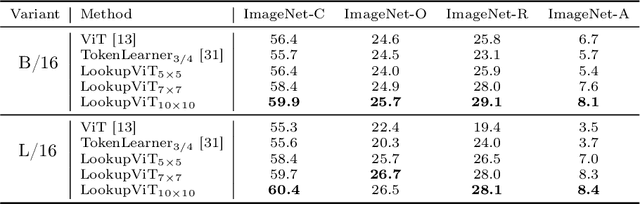
Vision Transformers (ViT) have emerged as the de-facto choice for numerous industry grade vision solutions. But their inference cost can be prohibitive for many settings, as they compute self-attention in each layer which suffers from quadratic computational complexity in the number of tokens. On the other hand, spatial information in images and spatio-temporal information in videos is usually sparse and redundant. In this work, we introduce LookupViT, that aims to exploit this information sparsity to reduce ViT inference cost. LookupViT provides a novel general purpose vision transformer block that operates by compressing information from higher resolution tokens to a fixed number of tokens. These few compressed tokens undergo meticulous processing, while the higher-resolution tokens are passed through computationally cheaper layers. Information sharing between these two token sets is enabled through a bidirectional cross-attention mechanism. The approach offers multiple advantages - (a) easy to implement on standard ML accelerators (GPUs/TPUs) via standard high-level operators, (b) applicable to standard ViT and its variants, thus generalizes to various tasks, (c) can handle different tokenization and attention approaches. LookupViT also offers flexibility for the compressed tokens, enabling performance-computation trade-offs in a single trained model. We show LookupViT's effectiveness on multiple domains - (a) for image-classification (ImageNet-1K and ImageNet-21K), (b) video classification (Kinetics400 and Something-Something V2), (c) image captioning (COCO-Captions) with a frozen encoder. LookupViT provides $2\times$ reduction in FLOPs while upholding or improving accuracy across these domains. In addition, LookupViT also demonstrates out-of-the-box robustness and generalization on image classification (ImageNet-C,R,A,O), improving by up to $4\%$ over ViT.
GRAtt-VIS: Gated Residual Attention for Auto Rectifying Video Instance Segmentation
May 26, 2023Recent trends in Video Instance Segmentation (VIS) have seen a growing reliance on online methods to model complex and lengthy video sequences. However, the degradation of representation and noise accumulation of the online methods, especially during occlusion and abrupt changes, pose substantial challenges. Transformer-based query propagation provides promising directions at the cost of quadratic memory attention. However, they are susceptible to the degradation of instance features due to the above-mentioned challenges and suffer from cascading effects. The detection and rectification of such errors remain largely underexplored. To this end, we introduce \textbf{GRAtt-VIS}, \textbf{G}ated \textbf{R}esidual \textbf{Att}ention for \textbf{V}ideo \textbf{I}nstance \textbf{S}egmentation. Firstly, we leverage a Gumbel-Softmax-based gate to detect possible errors in the current frame. Next, based on the gate activation, we rectify degraded features from its past representation. Such a residual configuration alleviates the need for dedicated memory and provides a continuous stream of relevant instance features. Secondly, we propose a novel inter-instance interaction using gate activation as a mask for self-attention. This masking strategy dynamically restricts the unrepresentative instance queries in the self-attention and preserves vital information for long-term tracking. We refer to this novel combination of Gated Residual Connection and Masked Self-Attention as \textbf{GRAtt} block, which can easily be integrated into the existing propagation-based framework. Further, GRAtt blocks significantly reduce the attention overhead and simplify dynamic temporal modeling. GRAtt-VIS achieves state-of-the-art performance on YouTube-VIS and the highly challenging OVIS dataset, significantly improving over previous methods. Code is available at \url{https://github.com/Tanveer81/GRAttVIS}.
Do DALL-E and Flamingo Understand Each Other?
Dec 23, 2022



A major goal of multimodal research is to improve machine understanding of images and text. Tasks include image captioning, text-to-image generation, and vision-language representation learning. So far, research has focused on the relationships between images and text. For example, captioning models attempt to understand the semantics of images which are then transformed into text. An important question is: which annotation reflects best a deep understanding of image content? Similarly, given a text, what is the best image that can present the semantics of the text? In this work, we argue that the best text or caption for a given image is the text which would generate the image which is the most similar to that image. Likewise, the best image for a given text is the image that results in the caption which is best aligned with the original text. To this end, we propose a unified framework that includes both a text-to-image generative model and an image-to-text generative model. Extensive experiments validate our approach.
InstanceFormer: An Online Video Instance Segmentation Framework
Aug 22, 2022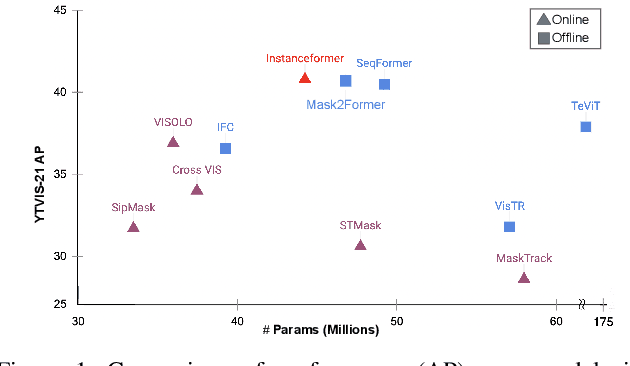
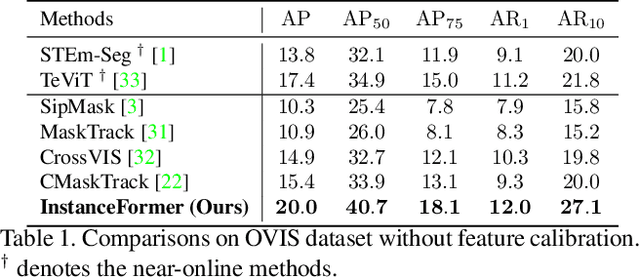
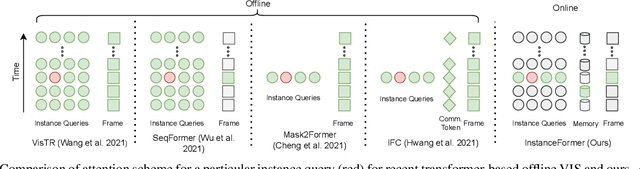
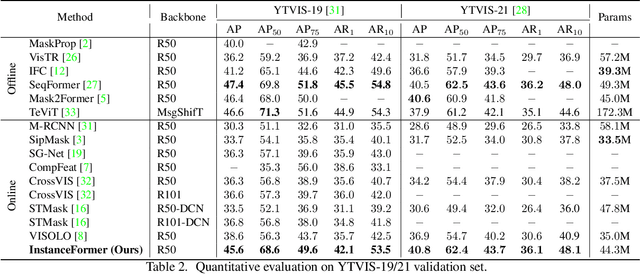
Recent transformer-based offline video instance segmentation (VIS) approaches achieve encouraging results and significantly outperform online approaches. However, their reliance on the whole video and the immense computational complexity caused by full Spatio-temporal attention limit them in real-life applications such as processing lengthy videos. In this paper, we propose a single-stage transformer-based efficient online VIS framework named InstanceFormer, which is especially suitable for long and challenging videos. We propose three novel components to model short-term and long-term dependency and temporal coherence. First, we propagate the representation, location, and semantic information of prior instances to model short-term changes. Second, we propose a novel memory cross-attention in the decoder, which allows the network to look into earlier instances within a certain temporal window. Finally, we employ a temporal contrastive loss to impose coherence in the representation of an instance across all frames. Memory attention and temporal coherence are particularly beneficial to long-range dependency modeling, including challenging scenarios like occlusion. The proposed InstanceFormer outperforms previous online benchmark methods by a large margin across multiple datasets. Most importantly, InstanceFormer surpasses offline approaches for challenging and long datasets such as YouTube-VIS-2021 and OVIS. Code is available at https://github.com/rajatkoner08/InstanceFormer.
Relationformer: A Unified Framework for Image-to-Graph Generation
Mar 19, 2022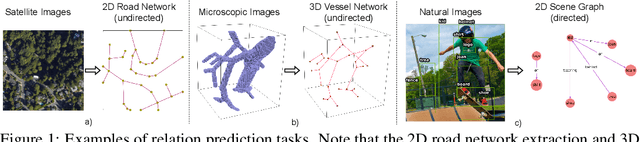

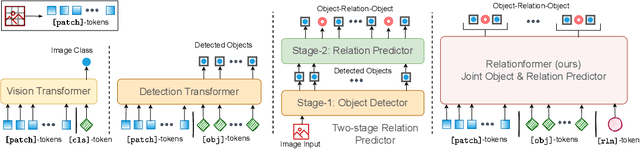
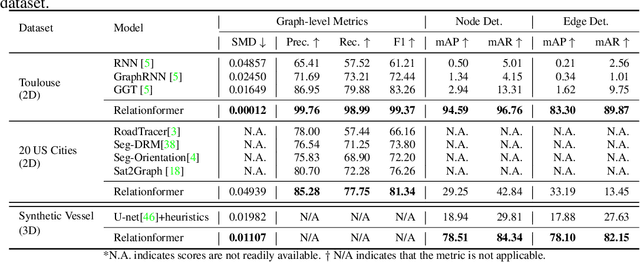
A comprehensive representation of an image requires understanding objects and their mutual relationship, especially in image-to-graph generation, e.g., road network extraction, blood-vessel network extraction, or scene graph generation. Traditionally, image-to-graph generation is addressed with a two-stage approach consisting of object detection followed by a separate relation prediction, which prevents simultaneous object-relation interaction. This work proposes a unified one-stage transformer-based framework, namely Relationformer, that jointly predicts objects and their relations. We leverage direct set-based object prediction and incorporate the interaction among the objects to learn an object-relation representation jointly. In addition to existing [obj]-tokens, we propose a novel learnable token, namely [rln]-token. Together with [obj]-tokens, [rln]-token exploits local and global semantic reasoning in an image through a series of mutual associations. In combination with the pair-wise [obj]-token, the [rln]-token contributes to a computationally efficient relation prediction. We achieve state-of-the-art performance on multiple, diverse and multi-domain datasets that demonstrate our approach's effectiveness and generalizability.
Is it all a cluster game? -- Exploring Out-of-Distribution Detection based on Clustering in the Embedding Space
Mar 16, 2022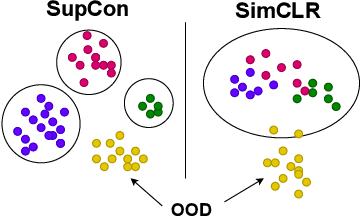
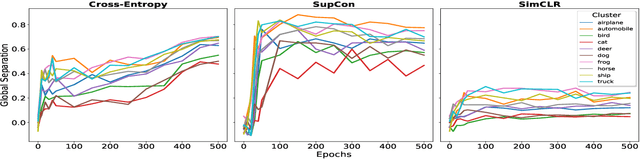
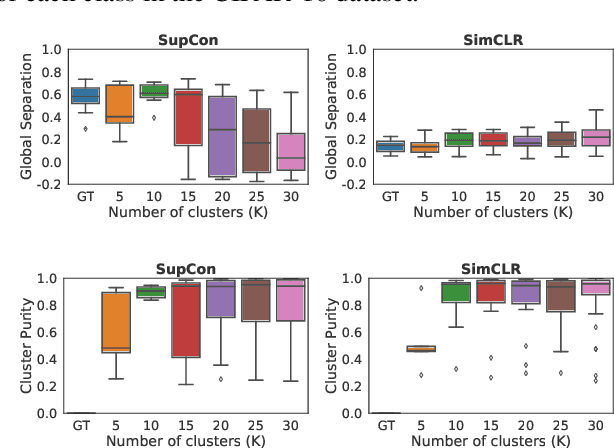
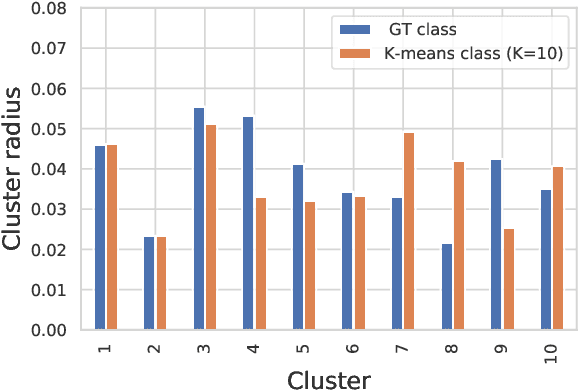
It is essential for safety-critical applications of deep neural networks to determine when new inputs are significantly different from the training distribution. In this paper, we explore this out-of-distribution (OOD) detection problem for image classification using clusters of semantically similar embeddings of the training data and exploit the differences in distance relationships to these clusters between in- and out-of-distribution data. We study the structure and separation of clusters in the embedding space and find that supervised contrastive learning leads to well-separated clusters while its self-supervised counterpart fails to do so. In our extensive analysis of different training methods, clustering strategies, distance metrics, and thresholding approaches, we observe that there is no clear winner. The optimal approach depends on the model architecture and selected datasets for in- and out-of-distribution. While we could reproduce the outstanding results for contrastive training on CIFAR-10 as in-distribution data, we find standard cross-entropy paired with cosine similarity outperforms all contrastive training methods when training on CIFAR-100 instead. Cross-entropy provides competitive results as compared to expensive contrastive training methods.
Box Supervised Video Segmentation Proposal Network
Feb 16, 2022
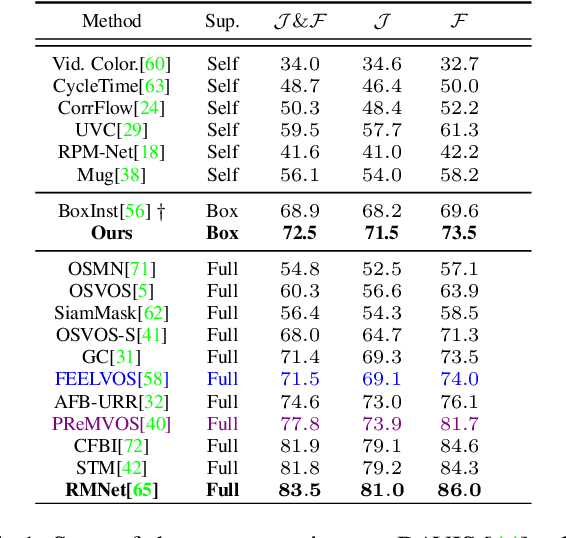
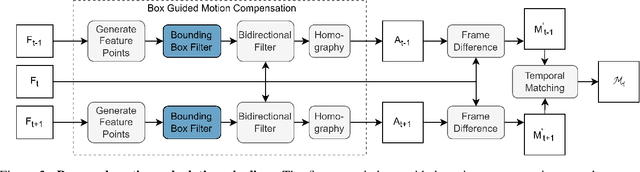
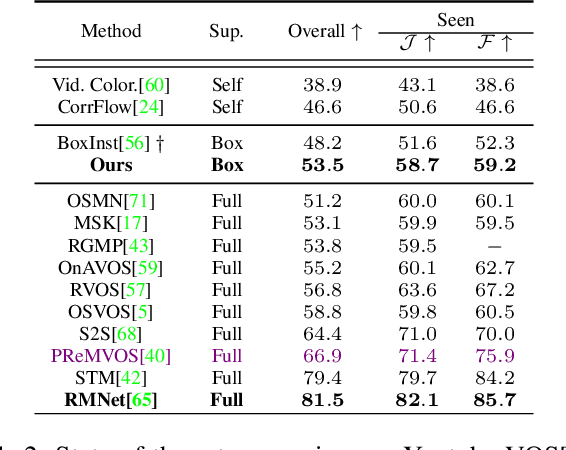
Video Object Segmentation (VOS) has been targeted by various fully-supervised and self-supervised approaches. While fully-supervised methods demonstrate excellent results, self-supervised ones, which do not use pixel-level ground truth, attract much attention. However, self-supervised approaches pose a significant performance gap. Box-level annotations provide a balanced compromise between labeling effort and result quality for image segmentation but have not been exploited for the video domain. In this work, we propose a box-supervised video object segmentation proposal network, which takes advantage of intrinsic video properties. Our method incorporates object motion in the following way: first, motion is computed using a bidirectional temporal difference and a novel bounding box-guided motion compensation. Second, we introduce a novel motion-aware affinity loss that encourages the network to predict positive pixel pairs if they share similar motion and color. The proposed method outperforms the state-of-the-art self-supervised benchmark by 16.4% and 6.9% $\mathcal{J}$ &$\mathcal{F}$ score and the majority of fully supervised methods on the DAVIS and Youtube-VOS dataset without imposing network architectural specifications. We provide extensive tests and ablations on the datasets, demonstrating the robustness of our method.
OODformer: Out-Of-Distribution Detection Transformer
Jul 19, 2021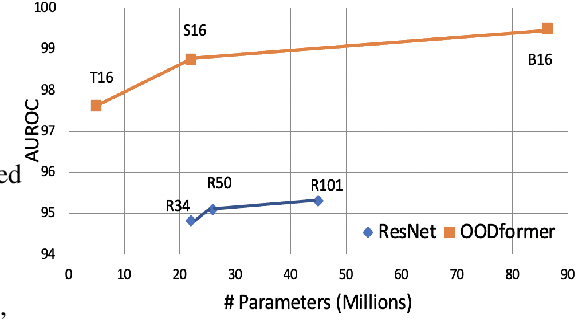
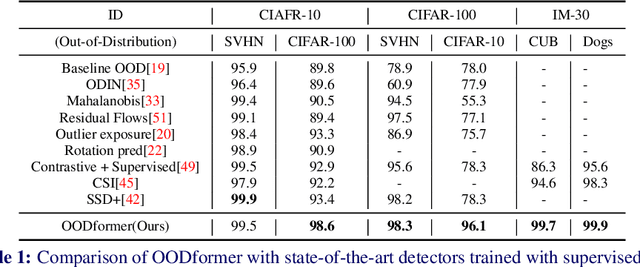
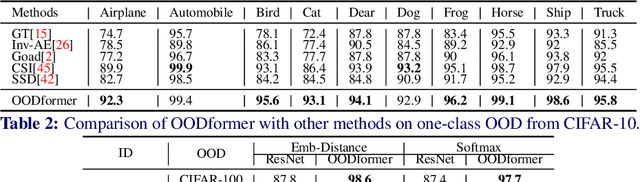

A serious problem in image classification is that a trained model might perform well for input data that originates from the same distribution as the data available for model training, but performs much worse for out-of-distribution (OOD) samples. In real-world safety-critical applications, in particular, it is important to be aware if a new data point is OOD. To date, OOD detection is typically addressed using either confidence scores, auto-encoder based reconstruction, or by contrastive learning. However, the global image context has not yet been explored to discriminate the non-local objectness between in-distribution and OOD samples. This paper proposes a first-of-its-kind OOD detection architecture named OODformer that leverages the contextualization capabilities of the transformer. Incorporating the trans\-former as the principal feature extractor allows us to exploit the object concepts and their discriminate attributes along with their co-occurrence via visual attention. Using the contextualised embedding, we demonstrate OOD detection using both class-conditioned latent space similarity and a network confidence score. Our approach shows improved generalizability across various datasets. We have achieved a new state-of-the-art result on CIFAR-10/-100 and ImageNet30.