 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs it all a cluster game? -- Exploring Out-of-Distribution Detection based on Clustering in the Embedding Space
Paper and Code
Mar 16, 2022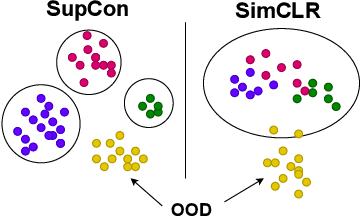
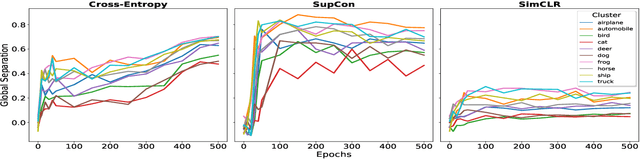
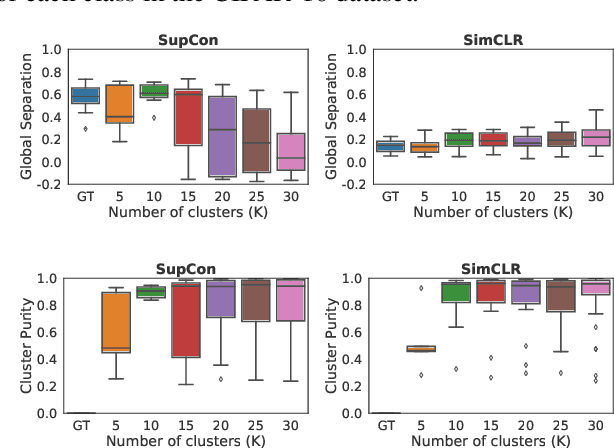
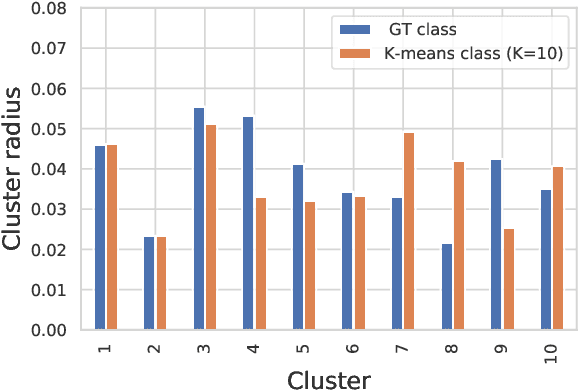
It is essential for safety-critical applications of deep neural networks to determine when new inputs are significantly different from the training distribution. In this paper, we explore this out-of-distribution (OOD) detection problem for image classification using clusters of semantically similar embeddings of the training data and exploit the differences in distance relationships to these clusters between in- and out-of-distribution data. We study the structure and separation of clusters in the embedding space and find that supervised contrastive learning leads to well-separated clusters while its self-supervised counterpart fails to do so. In our extensive analysis of different training methods, clustering strategies, distance metrics, and thresholding approaches, we observe that there is no clear winner. The optimal approach depends on the model architecture and selected datasets for in- and out-of-distribution. While we could reproduce the outstanding results for contrastive training on CIFAR-10 as in-distribution data, we find standard cross-entropy paired with cosine similarity outperforms all contrastive training methods when training on CIFAR-100 instead. Cross-entropy provides competitive results as compared to expensive contrastive training methods.