 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study of 3D Person Detection: Sensor Modalities and Robustness in Diverse Indoor and Outdoor Environments
Feb 05, 2026Accurate 3D person detection is critical for safety in applications such as robotics, industrial monitoring, and surveillance. This work presents a systematic evaluation of 3D person detection using camera-only, LiDAR-only, and camera-LiDAR fusion. While most existing research focuses on autonomous driving, we explore detection performance and robustness in diverse indoor and outdoor scenes using the JRDB dataset. We compare three representative models - BEVDepth (camera), PointPillars (LiDAR), and DAL (camera-LiDAR fusion) - and analyze their behavior under varying occlusion and distance levels. Our results show that the fusion-based approach consistently outperforms single-modality models, particularly in challenging scenarios. We further investigate robustness against sensor corruptions and misalignments, revealing that while DAL offers improved resilience, it remains sensitive to sensor misalignment and certain LiDAR-based corruptions. In contrast, the camera-based BEVDepth model showed the lowest performance and was most affected by occlusion, distance, and noise. Our findings highlight the importance of utilizing sensor fusion for enhanced 3D person detection, while also underscoring the need for ongoing research to address the vulnerabilities inherent in these systems.
Finding Dino: A plug-and-play framework for unsupervised detection of out-of-distribution objects using prototypes
Apr 11, 2024



Detecting and localising unknown or Out-of-distribution (OOD) objects in any scene can be a challenging task in vision. Particularly, in safety-critical cases involving autonomous systems like automated vehicles or trains. Supervised anomaly segmentation or open-world object detection models depend on training on exhaustively annotated datasets for every domain and still struggle in distinguishing between background and OOD objects. In this work, we present a plug-and-play generalised framework - PRototype-based zero-shot OOD detection Without Labels (PROWL). It is an inference-based method that does not require training on the domain dataset and relies on extracting relevant features from self-supervised pre-trained models. PROWL can be easily adapted to detect OOD objects in any operational design domain by specifying a list of known classes from this domain. PROWL, as an unsupervised method, outperforms other supervised methods trained without auxiliary OOD data on the RoadAnomaly and RoadObstacle datasets provided in SegmentMeIfYouCan (SMIYC) benchmark. We also demonstrate its suitability for other domains such as rail and maritime scenes.
Enhancing Interpretability of Vertebrae Fracture Grading using Human-interpretable Prototypes
Apr 03, 2024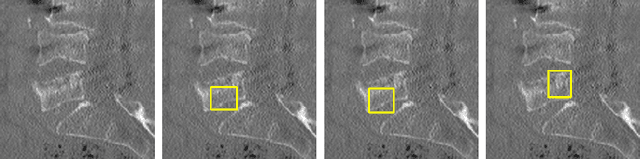

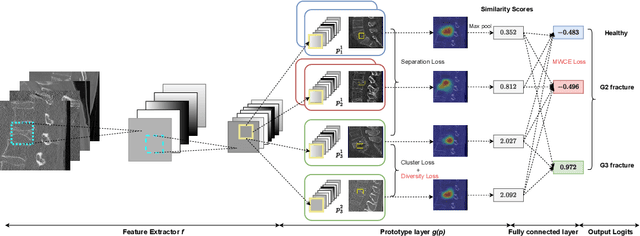

Vertebral fracture grading classifies the severity of vertebral fractures, which is a challenging task in medical imaging and has recently attracted Deep Learning (DL) models. Only a few works attempted to make such models human-interpretable despite the need for transparency and trustworthiness in critical use cases like DL-assisted medical diagnosis. Moreover, such models either rely on post-hoc methods or additional annotations. In this work, we propose a novel interpretable-by-design method, ProtoVerse, to find relevant sub-parts of vertebral fractures (prototypes) that reliably explain the model's decision in a human-understandable way. Specifically, we introduce a novel diversity-promoting loss to mitigate prototype repetitions in small datasets with intricate semantics. We have experimented with the VerSe'19 dataset and outperformed the existing prototype-based method. Further, our model provides superior interpretability against the post-hoc method. Importantly, expert radiologists validated the visual interpretability of our results, showing clinical applicability.
Preventing Errors in Person Detection: A Part-Based Self-Monitoring Framework
Jul 10, 2023The ability to detect learned objects regardless of their appearance is crucial for autonomous systems in real-world applications. Especially for detecting humans, which is often a fundamental task in safety-critical applications, it is vital to prevent errors. To address this challenge, we propose a self-monitoring framework that allows for the perception system to perform plausibility checks at runtime. We show that by incorporating an additional component for detecting human body parts, we are able to significantly reduce the number of missed human detections by factors of up to 9 when compared to a baseline setup, which was trained only on holistic person objects. Additionally, we found that training a model jointly on humans and their body parts leads to a substantial reduction in false positive detections by up to 50% compared to training on humans alone. We performed comprehensive experiments on the publicly available datasets DensePose and Pascal VOC in order to demonstrate the effectiveness of our framework. Code is available at https://github.com/ FraunhoferIKS/smf-object-detection.
Diffusion Denoised Smoothing for Certified and Adversarial Robust Out-Of-Distribution Detection
Mar 29, 2023
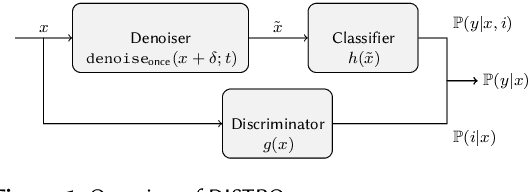
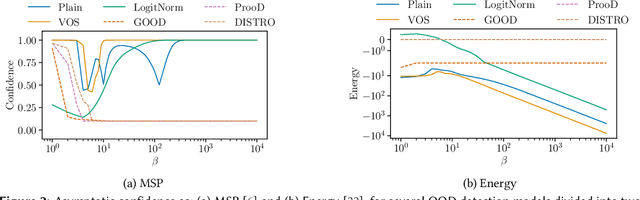
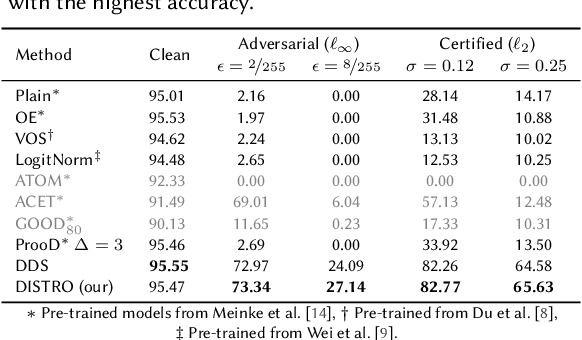
As the use of machine learning continues to expand, the importance of ensuring its safety cannot be overstated. A key concern in this regard is the ability to identify whether a given sample is from the training distribution, or is an "Out-Of-Distribution" (OOD) sample. In addition, adversaries can manipulate OOD samples in ways that lead a classifier to make a confident prediction. In this study, we present a novel approach for certifying the robustness of OOD detection within a $\ell_2$-norm around the input, regardless of network architecture and without the need for specific components or additional training. Further, we improve current techniques for detecting adversarial attacks on OOD samples, while providing high levels of certified and adversarial robustness on in-distribution samples. The average of all OOD detection metrics on CIFAR10/100 shows an increase of $\sim 13 \% / 5\%$ relative to previous approaches.
Towards Human-Interpretable Prototypes for Visual Assessment of Image Classification Models
Nov 22, 2022Explaining black-box Artificial Intelligence (AI) models is a cornerstone for trustworthy AI and a prerequisite for its use in safety critical applications such that AI models can reliably assist humans in critical decisions. However, instead of trying to explain our models post-hoc, we need models which are interpretable-by-design built on a reasoning process similar to humans that exploits meaningful high-level concepts such as shapes, texture or object parts. Learning such concepts is often hindered by its need for explicit specification and annotation up front. Instead, prototype-based learning approaches such as ProtoPNet claim to discover visually meaningful prototypes in an unsupervised way. In this work, we propose a set of properties that those prototypes have to fulfill to enable human analysis, e.g. as part of a reliable model assessment case, and analyse such existing methods in the light of these properties. Given a 'Guess who?' game, we find that these prototypes still have a long way ahead towards definite explanations. We quantitatively validate our findings by conducting a user study indicating that many of the learnt prototypes are not considered useful towards human understanding. We discuss about the missing links in the existing methods and present a potential real-world application motivating the need to progress towards truly human-interpretable prototypes.
Is it all a cluster game? -- Exploring Out-of-Distribution Detection based on Clustering in the Embedding Space
Mar 16, 2022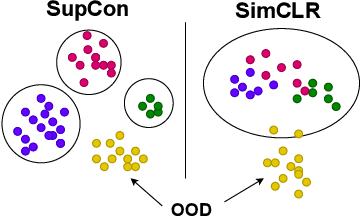
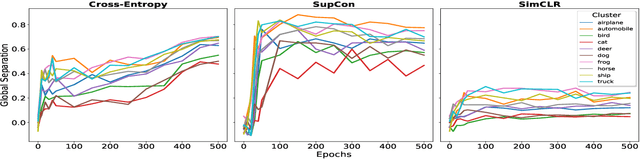
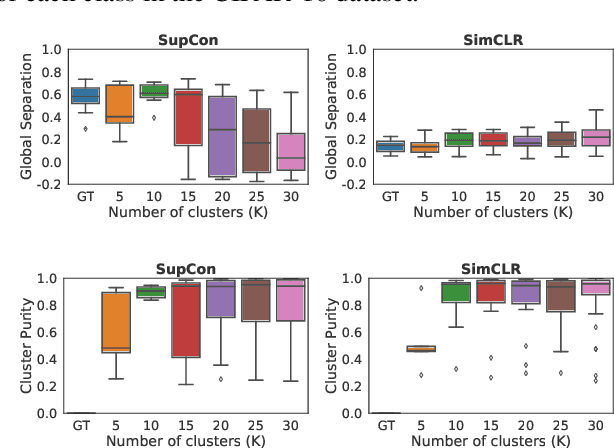
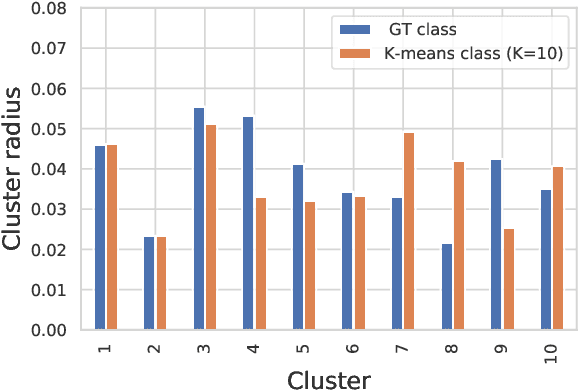
It is essential for safety-critical applications of deep neural networks to determine when new inputs are significantly different from the training distribution. In this paper, we explore this out-of-distribution (OOD) detection problem for image classification using clusters of semantically similar embeddings of the training data and exploit the differences in distance relationships to these clusters between in- and out-of-distribution data. We study the structure and separation of clusters in the embedding space and find that supervised contrastive learning leads to well-separated clusters while its self-supervised counterpart fails to do so. In our extensive analysis of different training methods, clustering strategies, distance metrics, and thresholding approaches, we observe that there is no clear winner. The optimal approach depends on the model architecture and selected datasets for in- and out-of-distribution. While we could reproduce the outstanding results for contrastive training on CIFAR-10 as in-distribution data, we find standard cross-entropy paired with cosine similarity outperforms all contrastive training methods when training on CIFAR-100 instead. Cross-entropy provides competitive results as compared to expensive contrastive training methods.
OODformer: Out-Of-Distribution Detection Transformer
Jul 19, 2021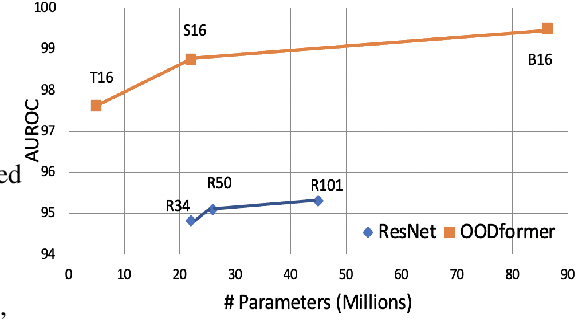
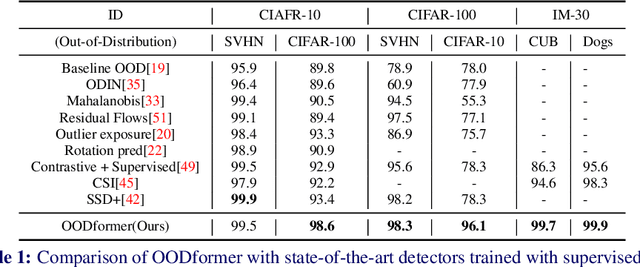
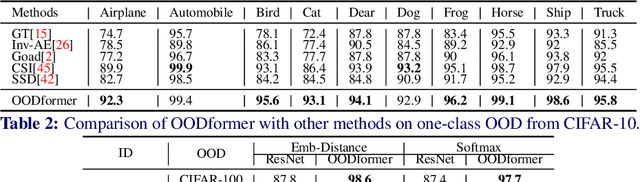

A serious problem in image classification is that a trained model might perform well for input data that originates from the same distribution as the data available for model training, but performs much worse for out-of-distribution (OOD) samples. In real-world safety-critical applications, in particular, it is important to be aware if a new data point is OOD. To date, OOD detection is typically addressed using either confidence scores, auto-encoder based reconstruction, or by contrastive learning. However, the global image context has not yet been explored to discriminate the non-local objectness between in-distribution and OOD samples. This paper proposes a first-of-its-kind OOD detection architecture named OODformer that leverages the contextualization capabilities of the transformer. Incorporating the trans\-former as the principal feature extractor allows us to exploit the object concepts and their discriminate attributes along with their co-occurrence via visual attention. Using the contextualised embedding, we demonstrate OOD detection using both class-conditioned latent space similarity and a network confidence score. Our approach shows improved generalizability across various datasets. We have achieved a new state-of-the-art result on CIFAR-10/-100 and ImageNet30.
From Black-box to White-box: Examining Confidence Calibration under different Conditions
Jan 08, 2021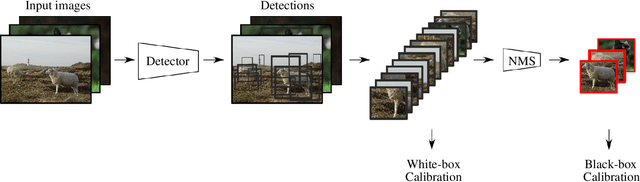
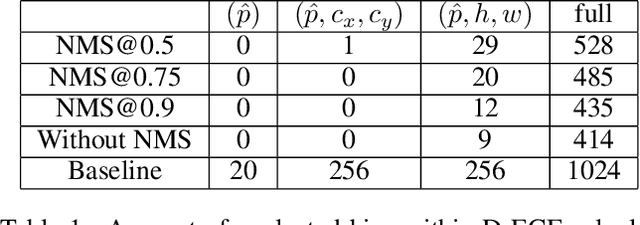

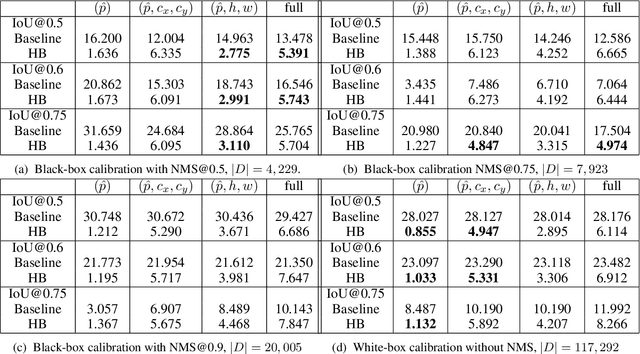
Confidence calibration is a major concern when applying artificial neural networks in safety-critical applications. Since most research in this area has focused on classification in the past, confidence calibration in the scope of object detection has gained more attention only recently. Based on previous work, we study the miscalibration of object detection models with respect to image location and box scale. Our main contribution is to additionally consider the impact of box selection methods like non-maximum suppression to calibration. We investigate the default intrinsic calibration of object detection models and how it is affected by these post-processing techniques. For this purpose, we distinguish between black-box calibration with non-maximum suppression and white-box calibration with raw network outputs. Our experiments reveal that post-processing highly affects confidence calibration. We show that non-maximum suppression has the potential to degrade initially well-calibrated predictions, leading to overconfident and thus miscalibrated models.