 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Local Model Validity using Active Learning
Jun 11, 2024Real-world applications of machine learning models are often subject to legal or policy-based regulations. Some of these regulations require ensuring the validity of the model, i.e., the approximation error being smaller than a threshold. A global metric is generally too insensitive to determine the validity of a specific prediction, whereas evaluating local validity is costly since it requires gathering additional data.We propose learning the model error to acquire a local validity estimate while reducing the amount of required data through active learning. Using model validation benchmarks, we provide empirical evidence that the proposed method can lead to an error model with sufficient discriminative properties using a relatively small amount of data. Furthermore, an increased sensitivity to local changes of the validity bounds compared to alternative approaches is demonstrated.
Segmentation-guided Domain Adaptation for Efficient Depth Completion
Oct 14, 2022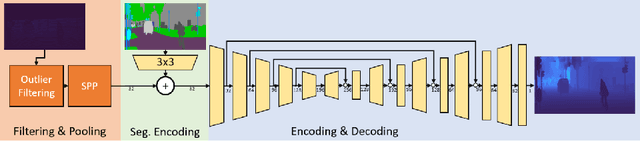


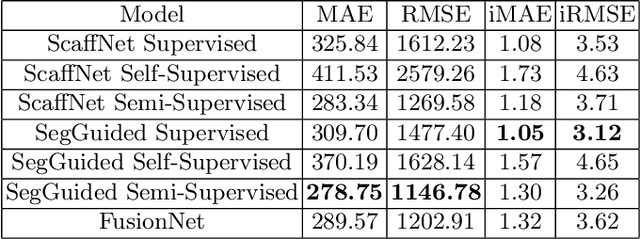
Complete depth information and efficient estimators have become vital ingredients in scene understanding for automated driving tasks. A major problem for LiDAR-based depth completion is the inefficient utilization of convolutions due to the lack of coherent information as provided by the sparse nature of uncorrelated LiDAR point clouds, which often leads to complex and resource-demanding networks. The problem is reinforced by the expensive aquisition of depth data for supervised training. In this work, we propose an efficient depth completion model based on a vgg05-like CNN architecture and propose a semi-supervised domain adaptation approach to transfer knowledge from synthetic to real world data to improve data-efficiency and reduce the need for a large database. In order to boost spatial coherence, we guide the learning process using segmentations as additional source of information. The efficiency and accuracy of our approach is evaluated on the KITTI dataset. Our approach improves on previous efficient and low parameter state of the art approaches while having a noticeably lower computational footprint.
Parametric and Multivariate Uncertainty Calibration for Regression and Object Detection
Jul 04, 2022
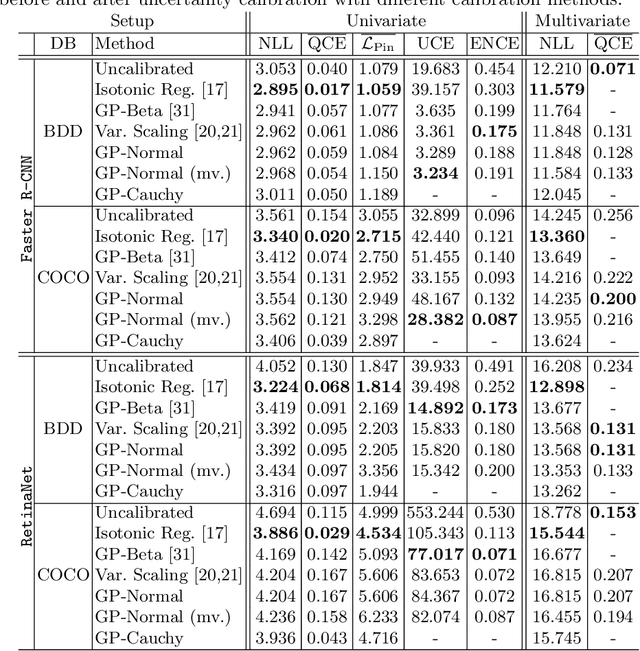
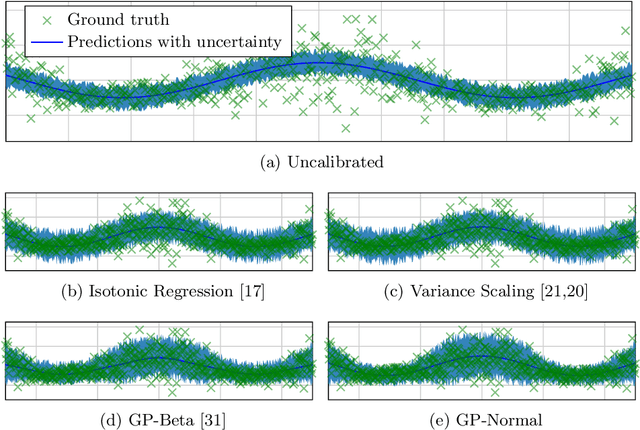
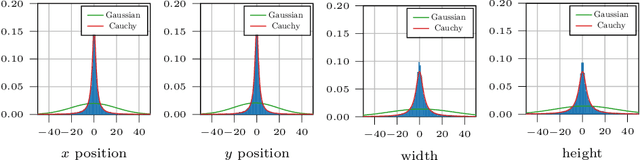
Reliable spatial uncertainty evaluation of object detection models is of special interest and has been subject of recent work. In this work, we review the existing definitions for uncertainty calibration of probabilistic regression tasks. We inspect the calibration properties of common detection networks and extend state-of-the-art recalibration methods. Our methods use a Gaussian process (GP) recalibration scheme that yields parametric distributions as output (e.g. Gaussian or Cauchy). The usage of GP recalibration allows for a local (conditional) uncertainty calibration by capturing dependencies between neighboring samples. The use of parametric distributions such as as Gaussian allows for a simplified adaption of calibration in subsequent processes, e.g., for Kalman filtering in the scope of object tracking. In addition, we use the GP recalibration scheme to perform covariance estimation which allows for post-hoc introduction of local correlations between the output quantities, e.g., position, width, or height in object detection. To measure the joint calibration of multivariate and possibly correlated data, we introduce the quantile calibration error which is based on the Mahalanobis distance between the predicted distribution and the ground truth to determine whether the ground truth is within a predicted quantile. Our experiments show that common detection models overestimate the spatial uncertainty in comparison to the observed error. We show that the simple Isotonic Regression recalibration method is sufficient to achieve a good uncertainty quantification in terms of calibrated quantiles. In contrast, if normal distributions are required for subsequent processes, our GP-Normal recalibration method yields the best results. Finally, we show that our covariance estimation method is able to achieve best calibration results for joint multivariate calibration.
Confidence Calibration for Object Detection and Segmentation
Mar 02, 2022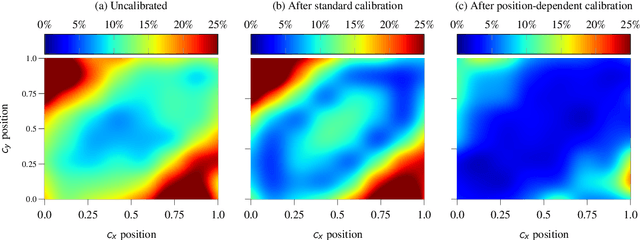
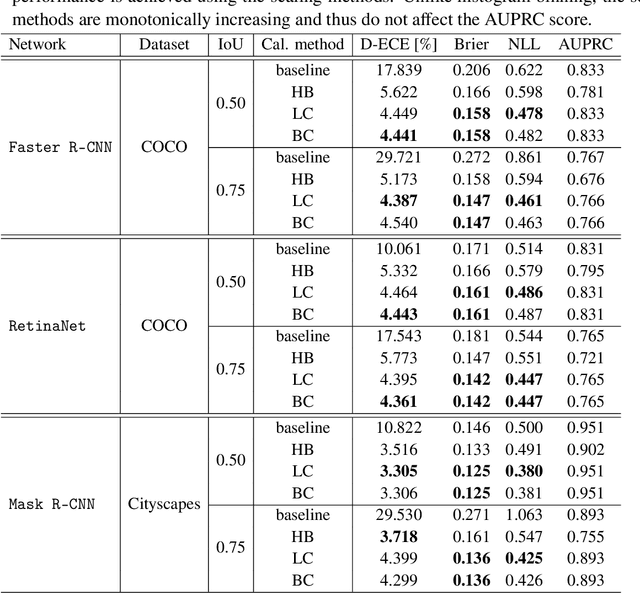
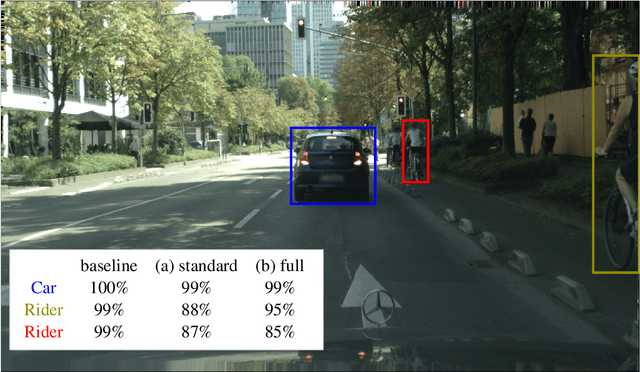
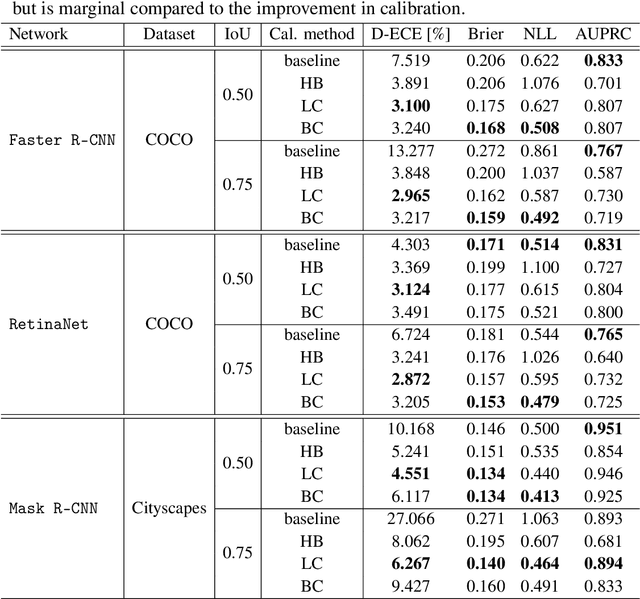
Calibrated confidence estimates obtained from neural networks are crucial, particularly for safety-critical applications such as autonomous driving or medical image diagnosis. However, although the task of confidence calibration has been investigated on classification problems, thorough investigations on object detection and segmentation problems are still missing. Therefore, we focus on the investigation of confidence calibration for object detection and segmentation models in this chapter. We introduce the concept of multivariate confidence calibration that is an extension of well-known calibration methods to the task of object detection and segmentation. This allows for an extended confidence calibration that is also aware of additional features such as bounding box/pixel position, shape information, etc. Furthermore, we extend the expected calibration error (ECE) to measure miscalibration of object detection and segmentation models. We examine several network architectures on MS COCO as well as on Cityscapes and show that especially object detection as well as instance segmentation models are intrinsically miscalibrated given the introduced definition of calibration. Using our proposed calibration methods, we have been able to improve calibration so that it also has a positive impact on the quality of segmentation masks as well.
Bayesian Confidence Calibration for Epistemic Uncertainty Modelling
Sep 21, 2021
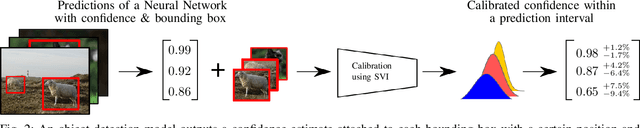
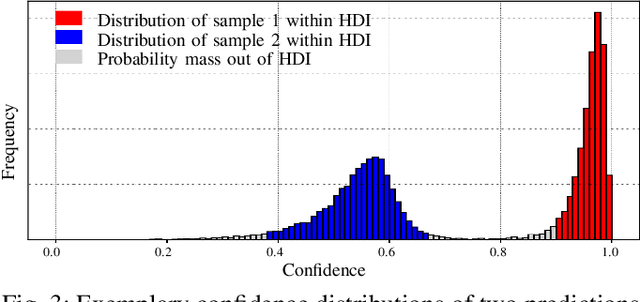
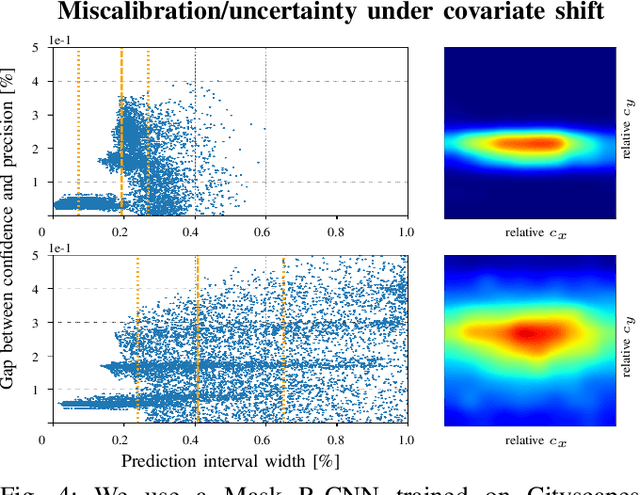
Modern neural networks have found to be miscalibrated in terms of confidence calibration, i.e., their predicted confidence scores do not reflect the observed accuracy or precision. Recent work has introduced methods for post-hoc confidence calibration for classification as well as for object detection to address this issue. Especially in safety critical applications, it is crucial to obtain a reliable self-assessment of a model. But what if the calibration method itself is uncertain, e.g., due to an insufficient knowledge base? We introduce Bayesian confidence calibration - a framework to obtain calibrated confidence estimates in conjunction with an uncertainty of the calibration method. Commonly, Bayesian neural networks (BNN) are used to indicate a network's uncertainty about a certain prediction. BNNs are interpreted as neural networks that use distributions instead of weights for inference. We transfer this idea of using distributions to confidence calibration. For this purpose, we use stochastic variational inference to build a calibration mapping that outputs a probability distribution rather than a single calibrated estimate. Using this approach, we achieve state-of-the-art calibration performance for object detection calibration. Finally, we show that this additional type of uncertainty can be used as a sufficient criterion for covariate shift detection. All code is open source and available at https://github.com/EFS-OpenSource/calibration-framework.
Inspect, Understand, Overcome: A Survey of Practical Methods for AI Safety
Apr 29, 2021The use of deep neural networks (DNNs) in safety-critical applications like mobile health and autonomous driving is challenging due to numerous model-inherent shortcomings. These shortcomings are diverse and range from a lack of generalization over insufficient interpretability to problems with malicious inputs. Cyber-physical systems employing DNNs are therefore likely to suffer from safety concerns. In recent years, a zoo of state-of-the-art techniques aiming to address these safety concerns has emerged. This work provides a structured and broad overview of them. We first identify categories of insufficiencies to then describe research activities aiming at their detection, quantification, or mitigation. Our paper addresses both machine learning experts and safety engineers: The former ones might profit from the broad range of machine learning topics covered and discussions on limitations of recent methods. The latter ones might gain insights into the specifics of modern ML methods. We moreover hope that our contribution fuels discussions on desiderata for ML systems and strategies on how to propel existing approaches accordingly.
From Black-box to White-box: Examining Confidence Calibration under different Conditions
Jan 08, 2021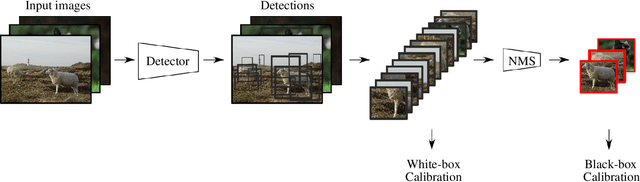
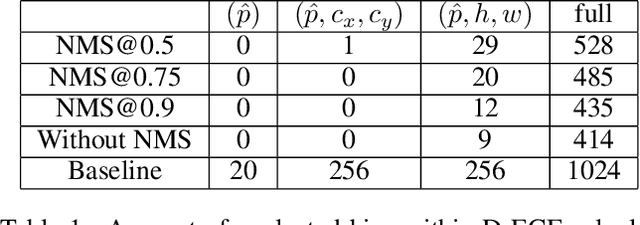

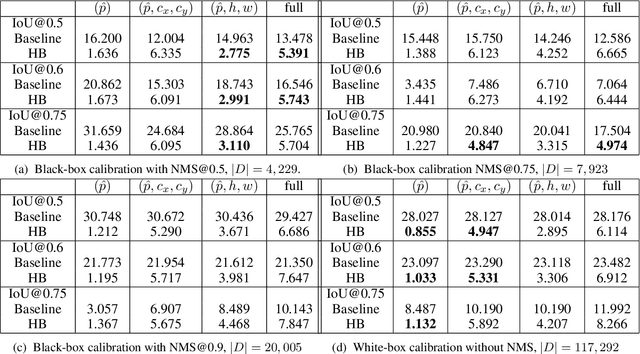
Confidence calibration is a major concern when applying artificial neural networks in safety-critical applications. Since most research in this area has focused on classification in the past, confidence calibration in the scope of object detection has gained more attention only recently. Based on previous work, we study the miscalibration of object detection models with respect to image location and box scale. Our main contribution is to additionally consider the impact of box selection methods like non-maximum suppression to calibration. We investigate the default intrinsic calibration of object detection models and how it is affected by these post-processing techniques. For this purpose, we distinguish between black-box calibration with non-maximum suppression and white-box calibration with raw network outputs. Our experiments reveal that post-processing highly affects confidence calibration. We show that non-maximum suppression has the potential to degrade initially well-calibrated predictions, leading to overconfident and thus miscalibrated models.
Dependency Decomposition and a Reject Option for Explainable Models
Dec 11, 2020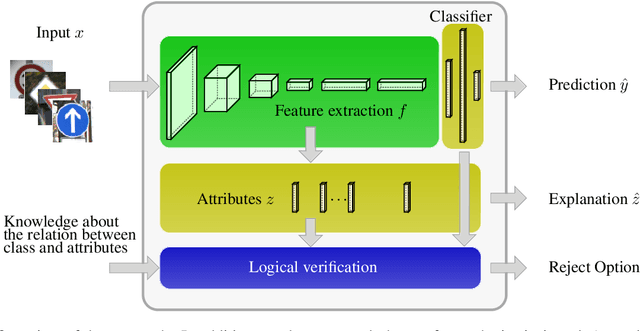
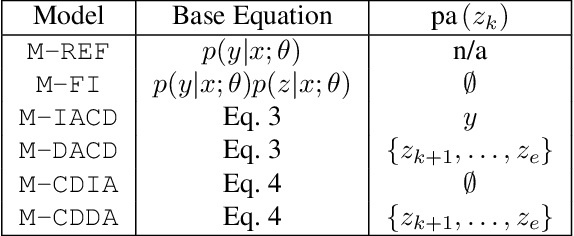
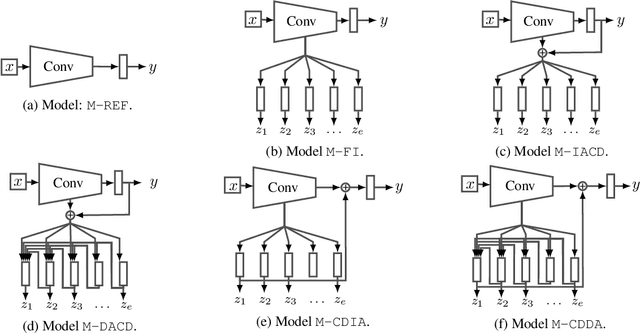
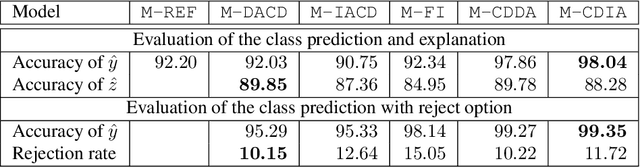
Deploying machine learning models in safety-related do-mains (e.g. autonomous driving, medical diagnosis) demands for approaches that are explainable, robust against adversarial attacks and aware of the model uncertainty. Recent deep learning models perform extremely well in various inference tasks, but the black-box nature of these approaches leads to a weakness regarding the three requirements mentioned above. Recent advances offer methods to visualize features, describe attribution of the input (e.g.heatmaps), provide textual explanations or reduce dimensionality. However,are explanations for classification tasks dependent or are they independent of each other? For in-stance, is the shape of an object dependent on the color? What is the effect of using the predicted class for generating explanations and vice versa? In the context of explainable deep learning models, we present the first analysis of dependencies regarding the probability distribution over the desired image classification outputs and the explaining variables (e.g. attributes, texts, heatmaps). Therefore, we perform an Explanation Dependency Decomposition (EDD). We analyze the implications of the different dependencies and propose two ways of generating the explanation. Finally, we use the explanation to verify (accept or reject) the prediction
Multivariate Confidence Calibration for Object Detection
Apr 28, 2020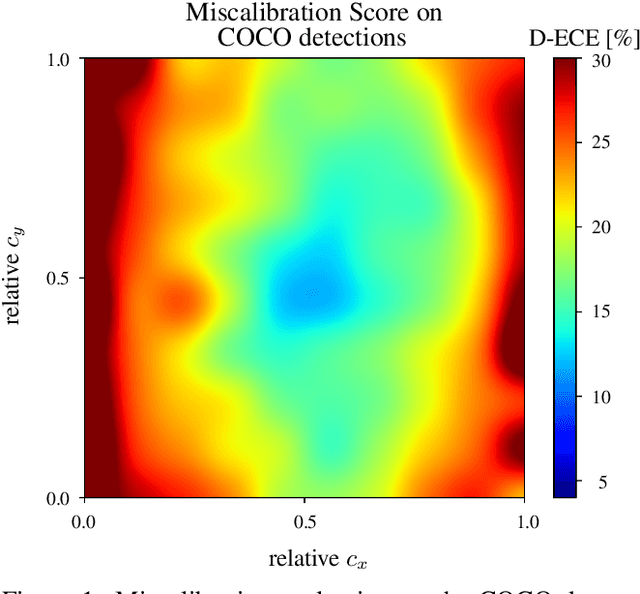
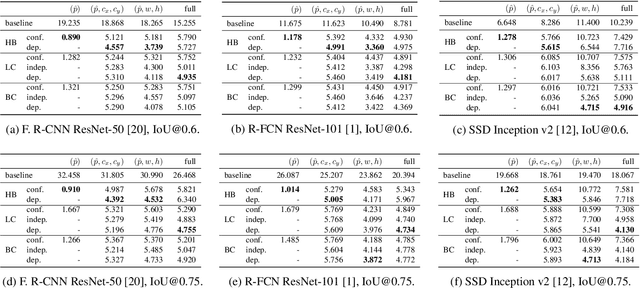

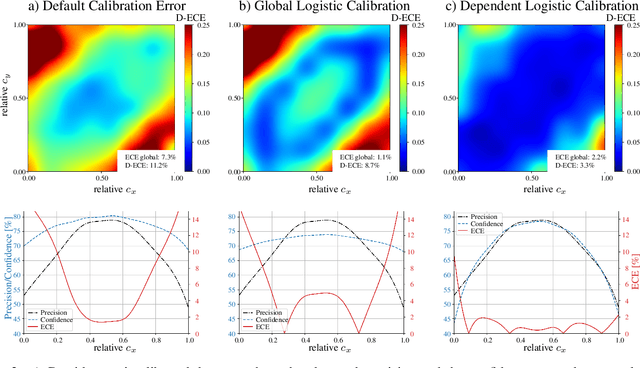
Unbiased confidence estimates of neural networks are crucial especially for safety-critical applications. Many methods have been developed to calibrate biased confidence estimates. Though there is a variety of methods for classification, the field of object detection has not been addressed yet. Therefore, we present a novel framework to measure and calibrate biased (or miscalibrated) confidence estimates of object detection methods. The main difference to related work in the field of classifier calibration is that we also use additional information of the regression output of an object detector for calibration. Our approach allows, for the first time, to obtain calibrated confidence estimates with respect to image location and box scale. In addition, we propose a new measure to evaluate miscalibration of object detectors. Finally, we show that our developed methods outperform state-of-the-art calibration models for the task of object detection and provides reliable confidence estimates across different locations and scales.