 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmentation-guided Domain Adaptation for Efficient Depth Completion
Oct 14, 2022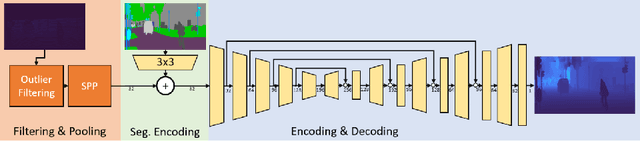


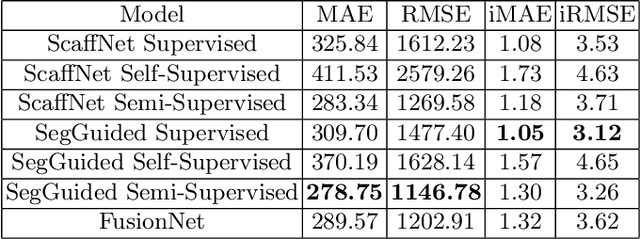
Complete depth information and efficient estimators have become vital ingredients in scene understanding for automated driving tasks. A major problem for LiDAR-based depth completion is the inefficient utilization of convolutions due to the lack of coherent information as provided by the sparse nature of uncorrelated LiDAR point clouds, which often leads to complex and resource-demanding networks. The problem is reinforced by the expensive aquisition of depth data for supervised training. In this work, we propose an efficient depth completion model based on a vgg05-like CNN architecture and propose a semi-supervised domain adaptation approach to transfer knowledge from synthetic to real world data to improve data-efficiency and reduce the need for a large database. In order to boost spatial coherence, we guide the learning process using segmentations as additional source of information. The efficiency and accuracy of our approach is evaluated on the KITTI dataset. Our approach improves on previous efficient and low parameter state of the art approaches while having a noticeably lower computational footprint.