 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Dino: A plug-and-play framework for unsupervised detection of out-of-distribution objects using prototypes
Apr 11, 2024



Detecting and localising unknown or Out-of-distribution (OOD) objects in any scene can be a challenging task in vision. Particularly, in safety-critical cases involving autonomous systems like automated vehicles or trains. Supervised anomaly segmentation or open-world object detection models depend on training on exhaustively annotated datasets for every domain and still struggle in distinguishing between background and OOD objects. In this work, we present a plug-and-play generalised framework - PRototype-based zero-shot OOD detection Without Labels (PROWL). It is an inference-based method that does not require training on the domain dataset and relies on extracting relevant features from self-supervised pre-trained models. PROWL can be easily adapted to detect OOD objects in any operational design domain by specifying a list of known classes from this domain. PROWL, as an unsupervised method, outperforms other supervised methods trained without auxiliary OOD data on the RoadAnomaly and RoadObstacle datasets provided in SegmentMeIfYouCan (SMIYC) benchmark. We also demonstrate its suitability for other domains such as rail and maritime scenes.
Spiking CenterNet: A Distillation-boosted Spiking Neural Network for Object Detection
Feb 02, 2024In the era of AI at the edge, self-driving cars, and climate change, the need for energy-efficient, small, embedded AI is growing. Spiking Neural Networks (SNNs) are a promising approach to address this challenge, with their event-driven information flow and sparse activations. We propose Spiking CenterNet for object detection on event data. It combines an SNN CenterNet adaptation with an efficient M2U-Net-based decoder. Our model significantly outperforms comparable previous work on Prophesee's challenging GEN1 Automotive Detection Dataset while using less than half the energy. Distilling the knowledge of a non-spiking teacher into our SNN further increases performance. To the best of our knowledge, our work is the first approach that takes advantage of knowledge distillation in the field of spiking object detection.
Preventing Errors in Person Detection: A Part-Based Self-Monitoring Framework
Jul 10, 2023The ability to detect learned objects regardless of their appearance is crucial for autonomous systems in real-world applications. Especially for detecting humans, which is often a fundamental task in safety-critical applications, it is vital to prevent errors. To address this challenge, we propose a self-monitoring framework that allows for the perception system to perform plausibility checks at runtime. We show that by incorporating an additional component for detecting human body parts, we are able to significantly reduce the number of missed human detections by factors of up to 9 when compared to a baseline setup, which was trained only on holistic person objects. Additionally, we found that training a model jointly on humans and their body parts leads to a substantial reduction in false positive detections by up to 50% compared to training on humans alone. We performed comprehensive experiments on the publicly available datasets DensePose and Pascal VOC in order to demonstrate the effectiveness of our framework. Code is available at https://github.com/ FraunhoferIKS/smf-object-detection.
From Black-box to White-box: Examining Confidence Calibration under different Conditions
Jan 08, 2021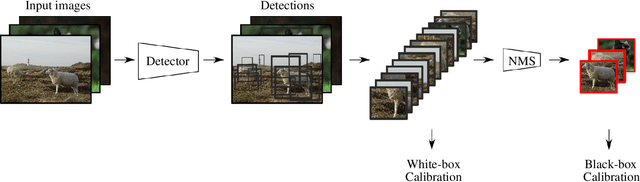
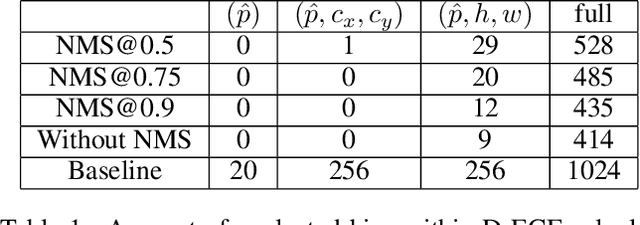

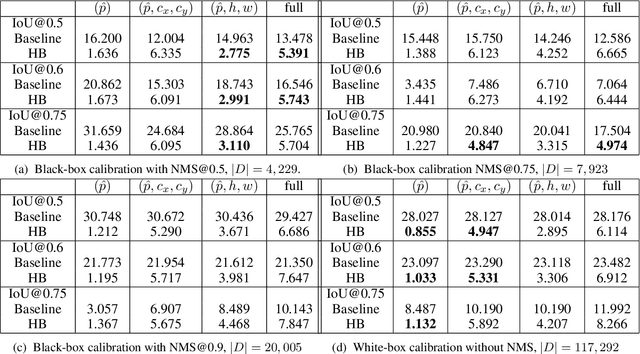
Confidence calibration is a major concern when applying artificial neural networks in safety-critical applications. Since most research in this area has focused on classification in the past, confidence calibration in the scope of object detection has gained more attention only recently. Based on previous work, we study the miscalibration of object detection models with respect to image location and box scale. Our main contribution is to additionally consider the impact of box selection methods like non-maximum suppression to calibration. We investigate the default intrinsic calibration of object detection models and how it is affected by these post-processing techniques. For this purpose, we distinguish between black-box calibration with non-maximum suppression and white-box calibration with raw network outputs. Our experiments reveal that post-processing highly affects confidence calibration. We show that non-maximum suppression has the potential to degrade initially well-calibrated predictions, leading to overconfident and thus miscalibrated models.