 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Dino: A plug-and-play framework for unsupervised detection of out-of-distribution objects using prototypes
Apr 11, 2024



Detecting and localising unknown or Out-of-distribution (OOD) objects in any scene can be a challenging task in vision. Particularly, in safety-critical cases involving autonomous systems like automated vehicles or trains. Supervised anomaly segmentation or open-world object detection models depend on training on exhaustively annotated datasets for every domain and still struggle in distinguishing between background and OOD objects. In this work, we present a plug-and-play generalised framework - PRototype-based zero-shot OOD detection Without Labels (PROWL). It is an inference-based method that does not require training on the domain dataset and relies on extracting relevant features from self-supervised pre-trained models. PROWL can be easily adapted to detect OOD objects in any operational design domain by specifying a list of known classes from this domain. PROWL, as an unsupervised method, outperforms other supervised methods trained without auxiliary OOD data on the RoadAnomaly and RoadObstacle datasets provided in SegmentMeIfYouCan (SMIYC) benchmark. We also demonstrate its suitability for other domains such as rail and maritime scenes.
CDAD-Net: Bridging Domain Gaps in Generalized Category Discovery
Apr 08, 2024In Generalized Category Discovery (GCD), we cluster unlabeled samples of known and novel classes, leveraging a training dataset of known classes. A salient challenge arises due to domain shifts between these datasets. To address this, we present a novel setting: Across Domain Generalized Category Discovery (AD-GCD) and bring forth CDAD-NET (Class Discoverer Across Domains) as a remedy. CDAD-NET is architected to synchronize potential known class samples across both the labeled (source) and unlabeled (target) datasets, while emphasizing the distinct categorization of the target data. To facilitate this, we propose an entropy-driven adversarial learning strategy that accounts for the distance distributions of target samples relative to source-domain class prototypes. Parallelly, the discriminative nature of the shared space is upheld through a fusion of three metric learning objectives. In the source domain, our focus is on refining the proximity between samples and their affiliated class prototypes, while in the target domain, we integrate a neighborhood-centric contrastive learning mechanism, enriched with an adept neighborsmining approach. To further accentuate the nuanced feature interrelation among semantically aligned images, we champion the concept of conditional image inpainting, underscoring the premise that semantically analogous images prove more efficacious to the task than their disjointed counterparts. Experimentally, CDAD-NET eclipses existing literature with a performance increment of 8-15% on three AD-GCD benchmarks we present.
Unknown Prompt, the only Lacuna: Unveiling CLIP's Potential for Open Domain Generalization
Mar 31, 2024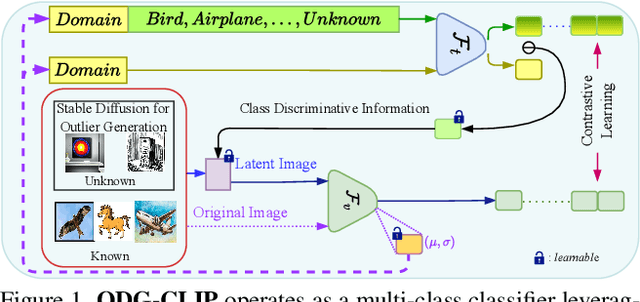
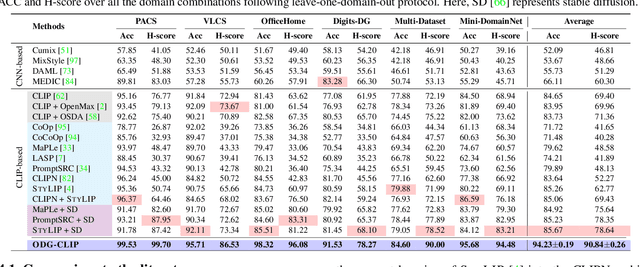
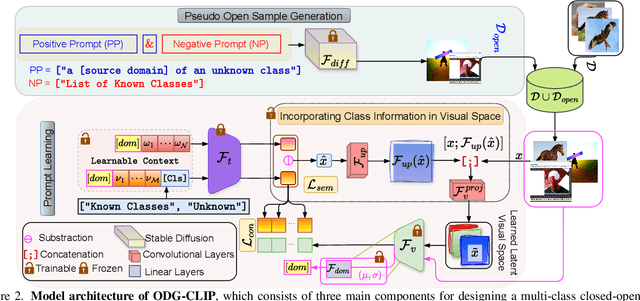
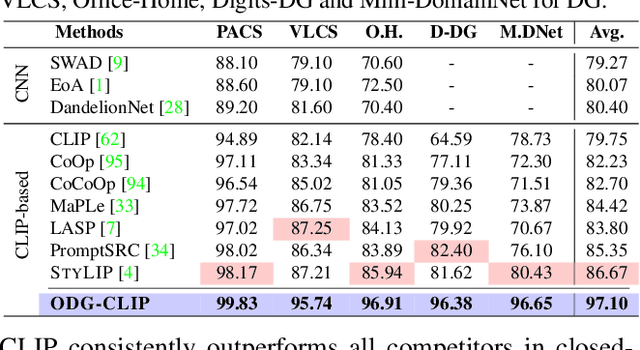
We delve into Open Domain Generalization (ODG), marked by domain and category shifts between training's labeled source and testing's unlabeled target domains. Existing solutions to ODG face limitations due to constrained generalizations of traditional CNN backbones and errors in detecting target open samples in the absence of prior knowledge. Addressing these pitfalls, we introduce ODG-CLIP, harnessing the semantic prowess of the vision-language model, CLIP. Our framework brings forth three primary innovations: Firstly, distinct from prevailing paradigms, we conceptualize ODG as a multi-class classification challenge encompassing both known and novel categories. Central to our approach is modeling a unique prompt tailored for detecting unknown class samples, and to train this, we employ a readily accessible stable diffusion model, elegantly generating proxy images for the open class. Secondly, aiming for domain-tailored classification (prompt) weights while ensuring a balance of precision and simplicity, we devise a novel visual stylecentric prompt learning mechanism. Finally, we infuse images with class-discriminative knowledge derived from the prompt space to augment the fidelity of CLIP's visual embeddings. We introduce a novel objective to safeguard the continuity of this infused semantic intel across domains, especially for the shared classes. Through rigorous testing on diverse datasets, covering closed and open-set DG contexts, ODG-CLIP demonstrates clear supremacy, consistently outpacing peers with performance boosts between 8%-16%. Code will be available at https://github.com/mainaksingha01/ODG-CLIP.
APPLeNet: Visual Attention Parameterized Prompt Learning for Few-Shot Remote Sensing Image Generalization using CLIP
Apr 12, 2023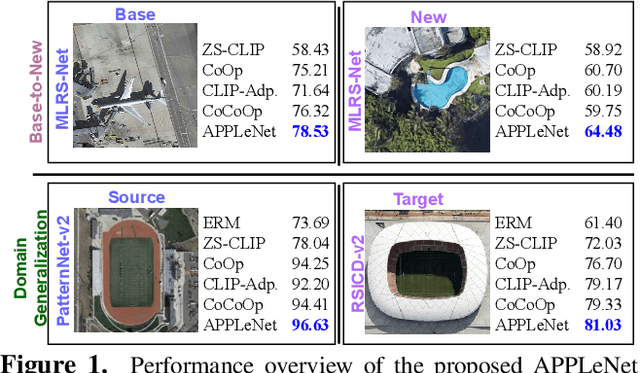

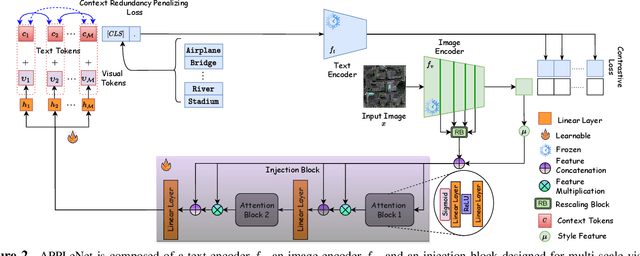
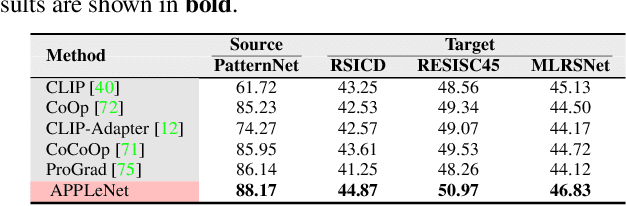
In recent years, the success of large-scale vision-language models (VLMs) such as CLIP has led to their increased usage in various computer vision tasks. These models enable zero-shot inference through carefully crafted instructional text prompts without task-specific supervision. However, the potential of VLMs for generalization tasks in remote sensing (RS) has not been fully realized. To address this research gap, we propose a novel image-conditioned prompt learning strategy called the Visual Attention Parameterized Prompts Learning Network (APPLeNet). APPLeNet emphasizes the importance of multi-scale feature learning in RS scene classification and disentangles visual style and content primitives for domain generalization tasks. To achieve this, APPLeNet combines visual content features obtained from different layers of the vision encoder and style properties obtained from feature statistics of domain-specific batches. An attention-driven injection module is further introduced to generate visual tokens from this information. We also introduce an anti-correlation regularizer to ensure discrimination among the token embeddings, as this visual information is combined with the textual tokens. To validate APPLeNet, we curated four available RS benchmarks and introduced experimental protocols and datasets for three domain generalization tasks. Our results consistently outperform the relevant literature and code is available at https://github.com/mainaksingha01/APPLeNet
StyLIP: Multi-Scale Style-Conditioned Prompt Learning for CLIP-based Domain Generalization
Feb 18, 2023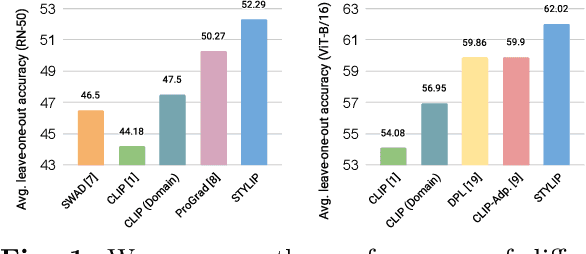
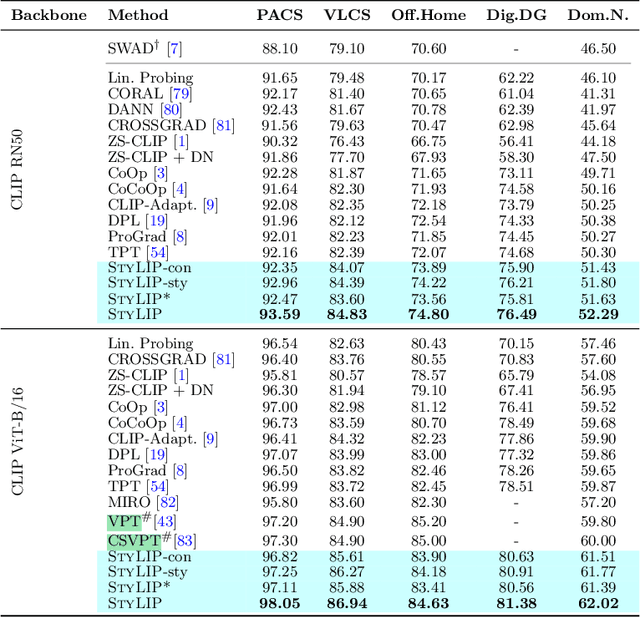
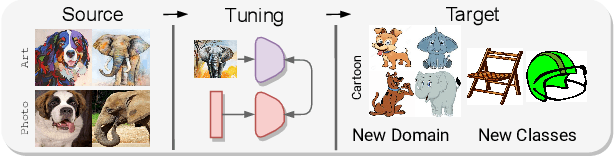
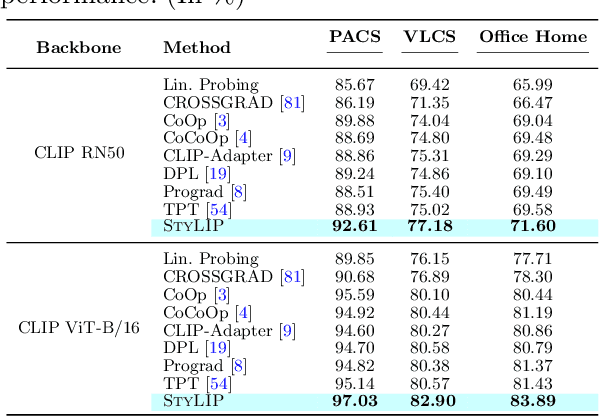
Large-scale foundation models (e.g., CLIP) have shown promising zero-shot generalization performance on downstream tasks by leveraging carefully designed language prompts. However, despite their success, most prompt learning techniques tend to underperform in the presence of domain shift. Our study addresses this problem and, to improve CLIP's generalization ability across domains, proposes \textsc{StyLIP}, a novel approach for Domain Generalization (DG) based on a domain-agnostic prompt learning strategy. In the absence of explicit domain knowledge, we aim to disentangle the visual style and the content information extracted from the pre-trained CLIP in the prompts so they can be effortlessly adapted to novel domains during inference. Furthermore, we consider a set of style projectors to learn the prompt tokens directly from these multi-scale style features, and the generated prompt embeddings are later fused with the multi-scale visual features learned through a content projector. The projectors are contrastively trained, given CLIP's frozen vision and text encoders. We present extensive experiments in five different DG settings on multiple benchmarks, demonstrating that \textsc{StyLIP} consistently outperforms the relevant state-of-the-art methods.
MultiScale Probability Map guided Index Pooling with Attention-based learning for Road and Building Segmentation
Feb 18, 2023



Efficient road and building footprint extraction from satellite images are predominant in many remote sensing applications. However, precise segmentation map extraction is quite challenging due to the diverse building structures camouflaged by trees, similar spectral responses between the roads and buildings, and occlusions by heterogeneous traffic over the roads. Existing convolutional neural network (CNN)-based methods focus on either enriched spatial semantics learning for the building extraction or the fine-grained road topology extraction. The profound semantic information loss due to the traditional pooling mechanisms in CNN generates fragmented and disconnected road maps and poorly segmented boundaries for the densely spaced small buildings in complex surroundings. In this paper, we propose a novel attention-aware segmentation framework, Multi-Scale Supervised Dilated Multiple-Path Attention Network (MSSDMPA-Net), equipped with two new modules Dynamic Attention Map Guided Index Pooling (DAMIP) and Dynamic Attention Map Guided Spatial and Channel Attention (DAMSCA) to precisely extract the building footprints and road maps from remotely sensed images. DAMIP mines the salient features by employing a novel index pooling mechanism to retain important geometric information. On the other hand, DAMSCA simultaneously extracts the multi-scale spatial and spectral features. Besides, using dilated convolution and multi-scale deep supervision in optimizing MSSDMPA-Net helps achieve stellar performance. Experimental results over multiple benchmark building and road extraction datasets, ensures MSSDMPA-Net as the state-of-the-art (SOTA) method for building and road extraction.