 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Modeling with Regularized Spatial Transformer Networks for All Weather Crosswind Landing of Aircraft
May 09, 2024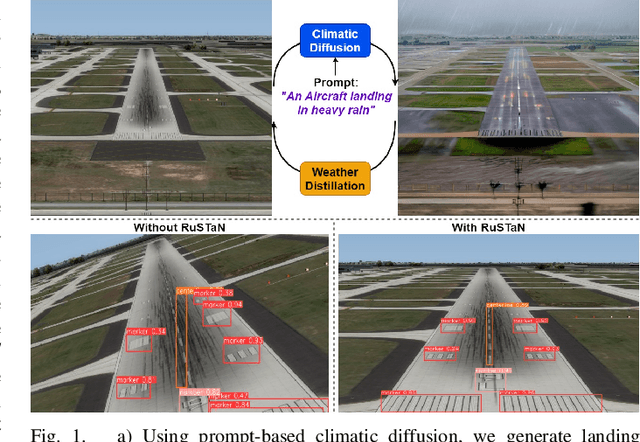
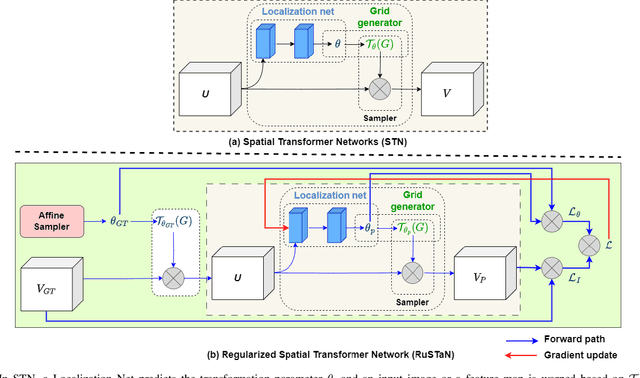
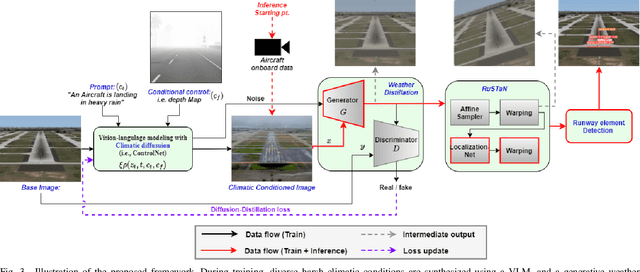

The intrinsic capability to perceive depth of field and extract salient information by the Human Vision System (HVS) stimulates a pilot to perform manual landing over an autoland approach. However, harsh weather creates visibility hindrances, and a pilot must have a clear view of runway elements before the minimum decision altitude. To help a pilot in manual landing, a vision-based system tailored to localize runway elements likewise gets affected, especially during crosswind due to the projective distortion of aircraft camera images. To combat this, we propose to integrate a prompt-based climatic diffusion network with a weather distillation model using a novel diffusion-distillation loss. Precisely, the diffusion model synthesizes climatic-conditioned landing images, and the weather distillation model learns inverse mapping by clearing those visual degradations. Then, to tackle the crosswind landing scenario, a novel Regularized Spatial Transformer Networks (RuSTaN) learns to accurately calibrate for projective distortion using self-supervised learning, which minimizes localization error by the downstream runway object detector. Finally, we have simulated a clear-day landing scenario at the busiest airport globally to curate an image-based Aircraft Landing Dataset (AIRLAD) and experimentally validated our contributions using this dataset to benchmark the performance.
HAVE-Net: Hallucinated Audio-Visual Embeddings for Few-Shot Classification with Unimodal Cues
Sep 23, 2023Recognition of remote sensing (RS) or aerial images is currently of great interest, and advancements in deep learning algorithms added flavor to it in recent years. Occlusion, intra-class variance, lighting, etc., might arise while training neural networks using unimodal RS visual input. Even though joint training of audio-visual modalities improves classification performance in a low-data regime, it has yet to be thoroughly investigated in the RS domain. Here, we aim to solve a novel problem where both the audio and visual modalities are present during the meta-training of a few-shot learning (FSL) classifier; however, one of the modalities might be missing during the meta-testing stage. This problem formulation is pertinent in the RS domain, given the difficulties in data acquisition or sensor malfunctioning. To mitigate, we propose a novel few-shot generative framework, Hallucinated Audio-Visual Embeddings-Network (HAVE-Net), to meta-train cross-modal features from limited unimodal data. Precisely, these hallucinated features are meta-learned from base classes and used for few-shot classification on novel classes during the inference phase. The experimental results on the benchmark ADVANCE and AudioSetZSL datasets show that our hallucinated modality augmentation strategy for few-shot classification outperforms the classifier performance trained with the real multimodal information at least by 0.8-2%.
Domain Adaptive Few-Shot Open-Set Learning
Sep 22, 2023



Few-shot learning has made impressive strides in addressing the crucial challenges of recognizing unknown samples from novel classes in target query sets and managing visual shifts between domains. However, existing techniques fall short when it comes to identifying target outliers under domain shifts by learning to reject pseudo-outliers from the source domain, resulting in an incomplete solution to both problems. To address these challenges comprehensively, we propose a novel approach called Domain Adaptive Few-Shot Open Set Recognition (DA-FSOS) and introduce a meta-learning-based architecture named DAFOSNET. During training, our model learns a shared and discriminative embedding space while creating a pseudo open-space decision boundary, given a fully-supervised source domain and a label-disjoint few-shot target domain. To enhance data density, we use a pair of conditional adversarial networks with tunable noise variances to augment both domains closed and pseudo-open spaces. Furthermore, we propose a domain-specific batch-normalized class prototypes alignment strategy to align both domains globally while ensuring class-discriminativeness through novel metric objectives. Our training approach ensures that DAFOS-NET can generalize well to new scenarios in the target domain. We present three benchmarks for DA-FSOS based on the Office-Home, mini-ImageNet/CUB, and DomainNet datasets and demonstrate the efficacy of DAFOS-NET through extensive experimentation
MultiScale Probability Map guided Index Pooling with Attention-based learning for Road and Building Segmentation
Feb 18, 2023



Efficient road and building footprint extraction from satellite images are predominant in many remote sensing applications. However, precise segmentation map extraction is quite challenging due to the diverse building structures camouflaged by trees, similar spectral responses between the roads and buildings, and occlusions by heterogeneous traffic over the roads. Existing convolutional neural network (CNN)-based methods focus on either enriched spatial semantics learning for the building extraction or the fine-grained road topology extraction. The profound semantic information loss due to the traditional pooling mechanisms in CNN generates fragmented and disconnected road maps and poorly segmented boundaries for the densely spaced small buildings in complex surroundings. In this paper, we propose a novel attention-aware segmentation framework, Multi-Scale Supervised Dilated Multiple-Path Attention Network (MSSDMPA-Net), equipped with two new modules Dynamic Attention Map Guided Index Pooling (DAMIP) and Dynamic Attention Map Guided Spatial and Channel Attention (DAMSCA) to precisely extract the building footprints and road maps from remotely sensed images. DAMIP mines the salient features by employing a novel index pooling mechanism to retain important geometric information. On the other hand, DAMSCA simultaneously extracts the multi-scale spatial and spectral features. Besides, using dilated convolution and multi-scale deep supervision in optimizing MSSDMPA-Net helps achieve stellar performance. Experimental results over multiple benchmark building and road extraction datasets, ensures MSSDMPA-Net as the state-of-the-art (SOTA) method for building and road extraction.