 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoDisaster: Benchmarking Orchestrated Agents for Operational Disaster Geo-Intelligence
Jun 15, 2026Remote-sensing vision-language models (RS-VLMs) have advanced Earth-observation analysis toward visual interpretation and instruction-following, yet fall short of operational geo-intelligence, which demands tool-grounded spatial reasoning and structured, evidence-backed decisions. We introduce GeoDisaster, an operational geospatial disaster reasoning benchmark with 2,921 verified instances across 43 question types and five task families: deforestation monitoring, multi-hazard analysis, building-damage assessment, flood-safe routing, and Sentinel-1 SAR flood monitoring. Instances integrate heterogeneous EO/GIS evidence-optical and SAR imagery, raster masks, vector geometries, road networks, and exposure layers-spanning hazard detection, damage assessment, exposure estimation, and diagnostic report generation. Ground-truth answers are grounded in executable geospatial workflows and deterministic consistency checks, removing the need for language-model annotation. We further propose an orchestrated multi-agent framework with 18 disaster-oriented tools, where role-specialized agents coordinate through explicit execution contracts, aligned via Role-Contract Expectation Alignment (RCEA): failure-aware supervised fine-tuning combined with contract-grounded reinforcement learning over dense step-level signals. Experiments show that GeoDisaster challenges existing RS-VLMs and agentic systems, while RCEA improves tool use, evidence grounding, state consistency, and decision generation.
ArcGate: Adaptive Arctangent Gated Activation
May 14, 2026Activation functions are central to deep networks, influencing non-linearity, feature learning, convergence, and robustness. This paper proposes the Adaptive Arctangent Gated Activation (ArcGate) function, a flexible formulation that generates a broad spectrum of activation shapes via a three-stage non-linear transformation. Unlike conventional fixed-shape activations such as ReLU, GELU, or SiLU, ArcGate uses seven learnable parameters per layer, allowing the neural network to autonomously optimize its non-linearity to the specific requirements of the feature hierarchy and data distribution. We evaluate ArcGate using ResNet-50 and Vision Transformer (ViT-B/16) architectures on three widely used remote sensing benchmarks: PatternNet, UC Merced Land Use, and the 13-band EuroSAT MSI multispectral dataset. Experimental results show that ArcGate consistently outperforms standard baselines, achieving a peak overall accuracy of 99.67% on PatternNet. Most notably, ArcGate exhibits superior structural resilience in noisy environments, maintaining a 26.65% performance lead over ReLU under moderate Gaussian noise (standard deviation 0.1). Analysis of the learned parameters reveals a depth-dependent functional evolution, where the model increases gating strength in deeper layers to enhance signal propagation. These findings suggest that ArcGate is a robust and adaptive general node activation function for high-resolution earth observation tasks.
GeoMeld: Toward Semantically Grounded Foundation Models for Remote Sensing
Apr 12, 2026Effective foundation modeling in remote sensing requires spatially aligned heterogeneous modalities coupled with semantically grounded supervision, yet such resources remain limited at scale. We present GeoMeld, a large-scale multimodal dataset with approximately 2.5 million spatially aligned samples. The dataset spans diverse modalities and resolutions and is constructed under a unified alignment protocol for modality-aware representation learning. GeoMeld provides semantically grounded language supervision through an agentic captioning framework that synthesizes and verifies annotations from spectral signals, terrain statistics, and structured geographic metadata, encoding measurable cross-modality relationships within textual descriptions. To leverage this dataset, we introduce GeoMeld-FM, a pretraining framework that combines multi-pretext masked autoencoding over aligned modalities, JEPA representation learning, and caption-vision contrastive alignment. This joint objective enables the learned representation space to capture both reliable cross-sensor physical consistency and grounded semantics. Experiments demonstrate consistent gains in downstream transfer and cross-sensor robustness. Together, GeoMeld and GeoMeld-FM establish a scalable reference framework for semantically grounded multi-modal foundation modeling in remote sensing.
FOCUS: Bridging Fine-Grained Recognition and Open-World Discovery across Domains
Mar 15, 2026We introduce the first unified framework for *Fine-Grained Domain-Generalized Generalized Category Discovery* (FG-DG-GCD), bringing open-world recognition closer to real-world deployment under domain shift. Unlike conventional GCD, which assumes labeled and unlabeled data come from the same distribution, DG-GCD learns only from labeled source data and must both recognize known classes and discover novel ones in unseen, unlabeled target domains. This problem is especially challenging in fine-grained settings, where subtle inter-class differences and large intra-class variation make domain generalization significantly harder. To support systematic evaluation, we establish the first *FG-DG-GCD benchmarks* by creating identity-preserving *painting* and *sketch* domains for CUB-200-2011, Stanford Cars, and FGVC-Aircraft using controlled diffusion-adapter stylization. On top of this ,we propose FoCUS, a single-stage framework that combines *Domain-Consistent Parts Discovery* (DCPD) for geometry-stable part reasoning with *Uncertainty-Aware Feature Augmentation* (UFA) for confidence-calibrated feature regularization through uncertainty-guided perturbations. Extensive experiments show that FoCUS outperforms strong GCD, FG-GCD, and DG-GCD baselines by **3.28%**, **9.68%**, and **2.07%**, respectively, in clustering accuracy on the proposed benchmarks. It also remains competitive on coarse-grained DG-GCD tasks while achieving nearly **3x** higher computational efficiency than the current state of the art. ^[Code and datasets will be released upon acceptance.]
CLIPoint3D: Language-Grounded Few-Shot Unsupervised 3D Point Cloud Domain Adaptation
Feb 23, 2026Recent vision-language models (VLMs) such as CLIP demonstrate impressive cross-modal reasoning, extending beyond images to 3D perception. Yet, these models remain fragile under domain shifts, especially when adapting from synthetic to real-world point clouds. Conventional 3D domain adaptation approaches rely on heavy trainable encoders, yielding strong accuracy but at the cost of efficiency. We introduce CLIPoint3D, the first framework for few-shot unsupervised 3D point cloud domain adaptation built upon CLIP. Our approach projects 3D samples into multiple depth maps and exploits the frozen CLIP backbone, refined through a knowledge-driven prompt tuning scheme that integrates high-level language priors with geometric cues from a lightweight 3D encoder. To adapt task-specific features effectively, we apply parameter-efficient fine-tuning to CLIP's encoders and design an entropy-guided view sampling strategy for selecting confident projections. Furthermore, an optimal transport-based alignment loss and an uncertainty-aware prototype alignment loss collaboratively bridge source-target distribution gaps while maintaining class separability. Extensive experiments on PointDA-10 and GraspNetPC-10 benchmarks show that CLIPoint3D achieves consistent 3-16% accuracy gains over both CLIP-based and conventional encoder-based baselines. Codes are available at https://github.com/SarthakM320/CLIPoint3D.
Revised Regularization for Efficient Continual Learning through Correlation-Based Parameter Update in Bayesian Neural Networks
Nov 21, 2024



We propose a Bayesian neural network-based continual learning algorithm using Variational Inference, aiming to overcome several drawbacks of existing methods. Specifically, in continual learning scenarios, storing network parameters at each step to retain knowledge poses challenges. This is compounded by the crucial need to mitigate catastrophic forgetting, particularly given the limited access to past datasets, which complicates maintaining correspondence between network parameters and datasets across all sessions. Current methods using Variational Inference with KL divergence risk catastrophic forgetting during uncertain node updates and coupled disruptions in certain nodes. To address these challenges, we propose the following strategies. To reduce the storage of the dense layer parameters, we propose a parameter distribution learning method that significantly reduces the storage requirements. In the continual learning framework employing variational inference, our study introduces a regularization term that specifically targets the dynamics and population of the mean and variance of the parameters. This term aims to retain the benefits of KL divergence while addressing related challenges. To ensure proper correspondence between network parameters and the data, our method introduces an importance-weighted Evidence Lower Bound term to capture data and parameter correlations. This enables storage of common and distinctive parameter hyperspace bases. The proposed method partitions the parameter space into common and distinctive subspaces, with conditions for effective backward and forward knowledge transfer, elucidating the network-parameter dataset correspondence. The experimental results demonstrate the effectiveness of our method across diverse datasets and various combinations of sequential datasets, yielding superior performance compared to existing approaches.
Efficient Curriculum based Continual Learning with Informative Subset Selection for Remote Sensing Scene Classification
Sep 03, 2023We tackle the problem of class incremental learning (CIL) in the realm of landcover classification from optical remote sensing (RS) images in this paper. The paradigm of CIL has recently gained much prominence given the fact that data are generally obtained in a sequential manner for real-world phenomenon. However, CIL has not been extensively considered yet in the domain of RS irrespective of the fact that the satellites tend to discover new classes at different geographical locations temporally. With this motivation, we propose a novel CIL framework inspired by the recent success of replay-memory based approaches and tackling two of their shortcomings. In order to reduce the effect of catastrophic forgetting of the old classes when a new stream arrives, we learn a curriculum of the new classes based on their similarity with the old classes. This is found to limit the degree of forgetting substantially. Next while constructing the replay memory, instead of randomly selecting samples from the old streams, we propose a sample selection strategy which ensures the selection of highly confident samples so as to reduce the effects of noise. We observe a sharp improvement in the CIL performance with the proposed components. Experimental results on the benchmark NWPU-RESISC45, PatternNet, and EuroSAT datasets confirm that our method offers improved stability-plasticity trade-off than the literature.
Physically Plausible 3D Human-Scene Reconstruction from Monocular RGB Image using an Adversarial Learning Approach
Jul 27, 2023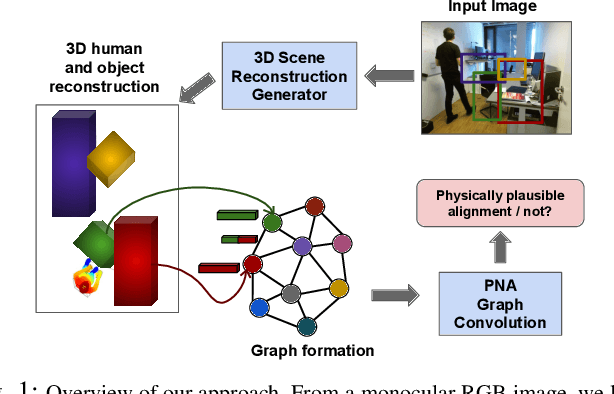
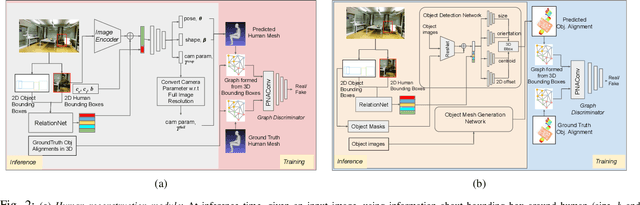

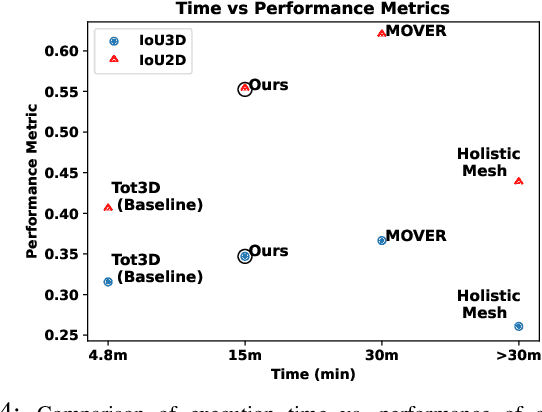
Holistic 3D human-scene reconstruction is a crucial and emerging research area in robot perception. A key challenge in holistic 3D human-scene reconstruction is to generate a physically plausible 3D scene from a single monocular RGB image. The existing research mainly proposes optimization-based approaches for reconstructing the scene from a sequence of RGB frames with explicitly defined physical laws and constraints between different scene elements (humans and objects). However, it is hard to explicitly define and model every physical law in every scenario. This paper proposes using an implicit feature representation of the scene elements to distinguish a physically plausible alignment of humans and objects from an implausible one. We propose using a graph-based holistic representation with an encoded physical representation of the scene to analyze the human-object and object-object interactions within the scene. Using this graphical representation, we adversarially train our model to learn the feasible alignments of the scene elements from the training data itself without explicitly defining the laws and constraints between them. Unlike the existing inference-time optimization-based approaches, we use this adversarially trained model to produce a per-frame 3D reconstruction of the scene that abides by the physical laws and constraints. Our learning-based method achieves comparable 3D reconstruction quality to existing optimization-based holistic human-scene reconstruction methods and does not need inference time optimization. This makes it better suited when compared to existing methods, for potential use in robotic applications, such as robot navigation, etc.
MultiScale Probability Map guided Index Pooling with Attention-based learning for Road and Building Segmentation
Feb 18, 2023



Efficient road and building footprint extraction from satellite images are predominant in many remote sensing applications. However, precise segmentation map extraction is quite challenging due to the diverse building structures camouflaged by trees, similar spectral responses between the roads and buildings, and occlusions by heterogeneous traffic over the roads. Existing convolutional neural network (CNN)-based methods focus on either enriched spatial semantics learning for the building extraction or the fine-grained road topology extraction. The profound semantic information loss due to the traditional pooling mechanisms in CNN generates fragmented and disconnected road maps and poorly segmented boundaries for the densely spaced small buildings in complex surroundings. In this paper, we propose a novel attention-aware segmentation framework, Multi-Scale Supervised Dilated Multiple-Path Attention Network (MSSDMPA-Net), equipped with two new modules Dynamic Attention Map Guided Index Pooling (DAMIP) and Dynamic Attention Map Guided Spatial and Channel Attention (DAMSCA) to precisely extract the building footprints and road maps from remotely sensed images. DAMIP mines the salient features by employing a novel index pooling mechanism to retain important geometric information. On the other hand, DAMSCA simultaneously extracts the multi-scale spatial and spectral features. Besides, using dilated convolution and multi-scale deep supervision in optimizing MSSDMPA-Net helps achieve stellar performance. Experimental results over multiple benchmark building and road extraction datasets, ensures MSSDMPA-Net as the state-of-the-art (SOTA) method for building and road extraction.
Prototypical quadruplet for few-shot class incremental learning
Nov 09, 2022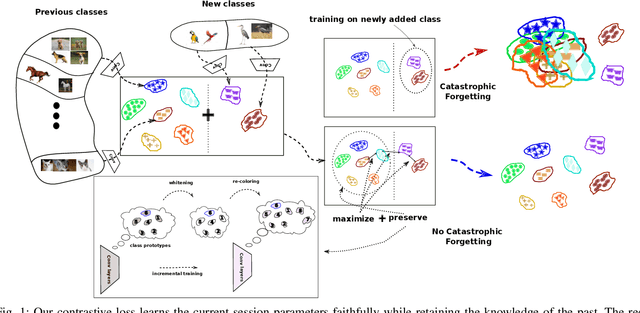
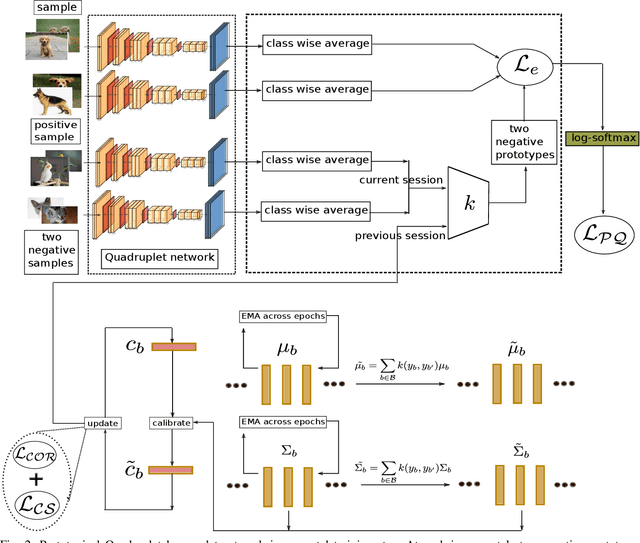
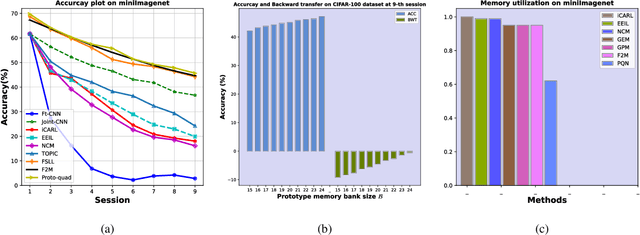
Many modern computer vision algorithms suffer from two major bottlenecks: scarcity of data and learning new tasks incrementally. While training the model with new batches of data the model looses it's ability to classify the previous data judiciously which is termed as catastrophic forgetting. Conventional methods have tried to mitigate catastrophic forgetting of the previously learned data while the training at the current session has been compromised. The state-of-the-art generative replay based approaches use complicated structures such as generative adversarial network (GAN) to deal with catastrophic forgetting. Additionally, training a GAN with few samples may lead to instability. In this work, we present a novel method to deal with these two major hurdles. Our method identifies a better embedding space with an improved contrasting loss to make classification more robust. Moreover, our approach is able to retain previously acquired knowledge in the embedding space even when trained with new classes. We update previous session class prototypes while training in such a way that it is able to represent the true class mean. This is of prime importance as our classification rule is based on the nearest class mean classification strategy. We have demonstrated our results by showing that the embedding space remains intact after training the model with new classes. We showed that our method preformed better than the existing state-of-the-art algorithms in terms of accuracy across different sessions.