 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrior2Posterior: Model Prior Correction for Long-Tailed Learning
Dec 21, 2024



Learning-based solutions for long-tailed recognition face difficulties in generalizing on balanced test datasets. Due to imbalanced data prior, the learned \textit{a posteriori} distribution is biased toward the most frequent (head) classes, leading to an inferior performance on the least frequent (tail) classes. In general, the performance can be improved by removing such a bias by eliminating the effect of imbalanced prior modeled using the number of class samples (frequencies). We first observe that the \textit{effective prior} on the classes, learned by the model at the end of the training, can differ from the empirical prior obtained using class frequencies. Thus, we propose a novel approach to accurately model the effective prior of a trained model using \textit{a posteriori} probabilities. We propose to correct the imbalanced prior by adjusting the predicted \textit{a posteriori} probabilities (Prior2Posterior: P2P) using the calculated prior in a post-hoc manner after the training, and show that it can result in improved model performance. We present theoretical analysis showing the optimality of our approach for models trained with naive cross-entropy loss as well as logit adjusted loss. Our experiments show that the proposed approach achieves new state-of-the-art (SOTA) on several benchmark datasets from the long-tail literature in the category of logit adjustment methods. Further, the proposed approach can be used to inspect any existing method to capture the \textit{effective prior} and remove any residual bias to improve its performance, post-hoc, without model retraining. We also show that by using the proposed post-hoc approach, the performance of many existing methods can be improved further.
Deep Learning based Novel View Synthesis
Jul 14, 2021

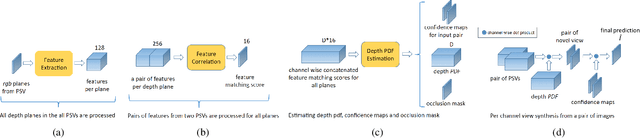
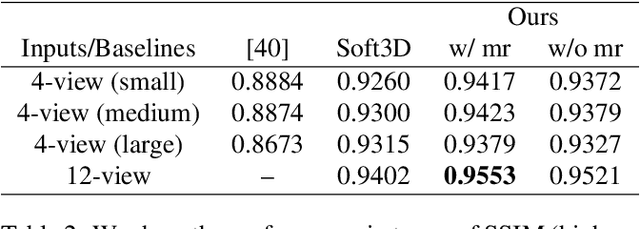
Predicting novel views of a scene from real-world images has always been a challenging task. In this work, we propose a deep convolutional neural network (CNN) which learns to predict novel views of a scene from given collection of images. In comparison to prior deep learning based approaches, which can handle only a fixed number of input images to predict novel view, proposed approach works with different numbers of input images. The proposed model explicitly performs feature extraction and matching from a given pair of input images and estimates, at each pixel, the probability distribution (pdf) over possible depth levels in the scene. This pdf is then used for estimating the novel view. The model estimates multiple predictions of novel view, one estimate per input image pair, from given image collection. The model also estimates an occlusion mask and combines multiple novel view estimates in to a single optimal prediction. The finite number of depth levels used in the analysis may cause occasional blurriness in the estimated view. We mitigate this issue with simple multi-resolution analysis which improves the quality of the estimates. We substantiate the performance on different datasets and show competitive performance.