 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrior2Posterior: Model Prior Correction for Long-Tailed Learning
Dec 21, 2024



Learning-based solutions for long-tailed recognition face difficulties in generalizing on balanced test datasets. Due to imbalanced data prior, the learned \textit{a posteriori} distribution is biased toward the most frequent (head) classes, leading to an inferior performance on the least frequent (tail) classes. In general, the performance can be improved by removing such a bias by eliminating the effect of imbalanced prior modeled using the number of class samples (frequencies). We first observe that the \textit{effective prior} on the classes, learned by the model at the end of the training, can differ from the empirical prior obtained using class frequencies. Thus, we propose a novel approach to accurately model the effective prior of a trained model using \textit{a posteriori} probabilities. We propose to correct the imbalanced prior by adjusting the predicted \textit{a posteriori} probabilities (Prior2Posterior: P2P) using the calculated prior in a post-hoc manner after the training, and show that it can result in improved model performance. We present theoretical analysis showing the optimality of our approach for models trained with naive cross-entropy loss as well as logit adjusted loss. Our experiments show that the proposed approach achieves new state-of-the-art (SOTA) on several benchmark datasets from the long-tail literature in the category of logit adjustment methods. Further, the proposed approach can be used to inspect any existing method to capture the \textit{effective prior} and remove any residual bias to improve its performance, post-hoc, without model retraining. We also show that by using the proposed post-hoc approach, the performance of many existing methods can be improved further.
Efficient Curriculum based Continual Learning with Informative Subset Selection for Remote Sensing Scene Classification
Sep 03, 2023We tackle the problem of class incremental learning (CIL) in the realm of landcover classification from optical remote sensing (RS) images in this paper. The paradigm of CIL has recently gained much prominence given the fact that data are generally obtained in a sequential manner for real-world phenomenon. However, CIL has not been extensively considered yet in the domain of RS irrespective of the fact that the satellites tend to discover new classes at different geographical locations temporally. With this motivation, we propose a novel CIL framework inspired by the recent success of replay-memory based approaches and tackling two of their shortcomings. In order to reduce the effect of catastrophic forgetting of the old classes when a new stream arrives, we learn a curriculum of the new classes based on their similarity with the old classes. This is found to limit the degree of forgetting substantially. Next while constructing the replay memory, instead of randomly selecting samples from the old streams, we propose a sample selection strategy which ensures the selection of highly confident samples so as to reduce the effects of noise. We observe a sharp improvement in the CIL performance with the proposed components. Experimental results on the benchmark NWPU-RESISC45, PatternNet, and EuroSAT datasets confirm that our method offers improved stability-plasticity trade-off than the literature.
Directed Variational Cross-encoder Network for Few-shot Multi-image Co-segmentation
Oct 17, 2020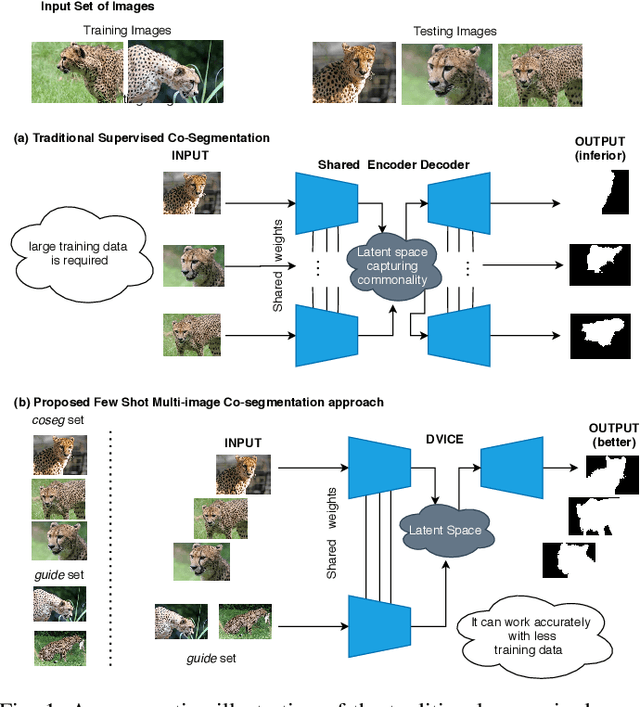
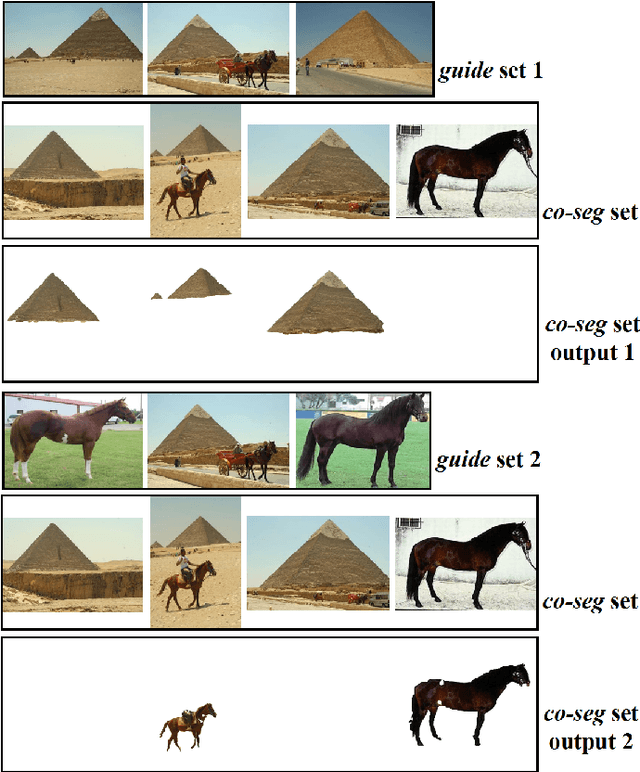
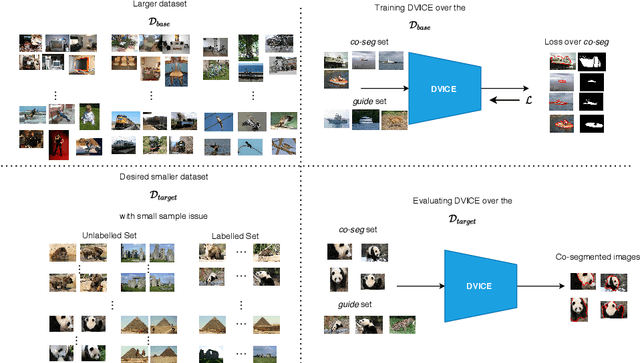
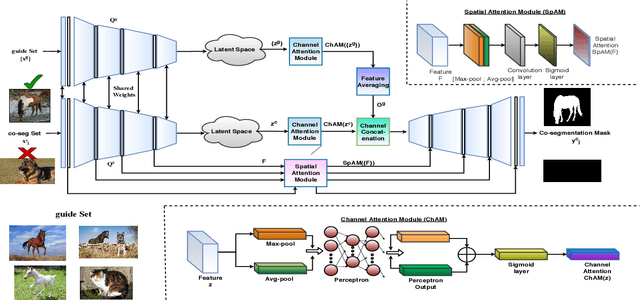
In this paper, we propose a novel framework for multi-image co-segmentation using class agnostic meta-learning strategy by generalizing to new classes given only a small number of training samples for each new class. We have developed a novel encoder-decoder network termed as DVICE (Directed Variational Inference Cross Encoder), which learns a continuous embedding space to ensure better similarity learning. We employ a combination of the proposed DVICE network and a novel few-shot learning approach to tackle the small sample size problem encountered in co-segmentation with small datasets like iCoseg and MSRC. Furthermore, the proposed framework does not use any semantic class labels and is entirely class agnostic. Through exhaustive experimentation over multiple datasets using only a small volume of training data, we have demonstrated that our approach outperforms all existing state-of-the-art techniques.