 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRIFT: From Robustness Gaps to Invariance Manifolds for AI-Generated Image Detection
Jun 05, 2026The rapid evolution of generative image models challenges existing AI-generated image detectors, particularly in open-world settings with unseen generators. Recent training-free approaches measure robustness gaps in frozen vision foundation models (VFMs), detecting fakes via perturbation-induced embedding drift. However, these methods rely on fixed invariance geometry inherited from pretraining and lack principled adaptation to the detection task. We instead formulate AI-generated image detection as learning a structured invariance manifold of real images under one-class supervision. Building upon a frozen VFM, we introduce lightweight projection heads that decompose representation space into complementary robust and fragile subspaces. The robust subspace is explicitly trained to suppress variations induced by physically plausible imaging transformations, approximating tangent directions of a real-image manifold, while the fragile subspace retains sensitivity to edit-like perturbations. A structured ordering margin enforces hierarchical separation between physical invariance and edit-induced variability, enabling detection as a margin-violation test relative to the learned manifold. At inference, multi-scale patch-wise drift under both transformation families yields a dual-channel invariance signature and interpretable localization. Extensive experiments demonstrate strong open-world generalization across unseen generators and resolutions, consistently outperforming training-free robustness-based baselines while providing interpretable invariance-violation maps.
Geodesic Flow Matching on a Riemannian Degradation Manifold for Blind Image Restoration
Jun 04, 2026Blind image restoration requires recovering clean images from observations corrupted by unknown and potentially mixed degradations. While recent deterministic flow-based methods model restoration as transport processes that map degraded images to clean ones, they typically rely on Euclidean interpolation, implicitly assuming linear degradation geometry. In this paper, we explicitly model degradations as points on a low-dimensional Riemannian manifold and formulate restoration as geodesic transport on the joint image-manifold space. Using a geodesic flow matching objective, we learn intrinsic transport dynamics that respect the curvature of degradation space. This framework generalizes linear flow matching, provides a principled treatment of mixed degradations as geodesic compositions, and yields a clean theoretical interpretation for generalization beyond observed degradations.
Finite-Particle Rates for Regularized Stein Variational Gradient Descent
Feb 05, 2026We derive finite-particle rates for the regularized Stein variational gradient descent (R-SVGD) algorithm introduced by He et al. (2024) that corrects the constant-order bias of the SVGD by applying a resolvent-type preconditioner to the kernelized Wasserstein gradient. For the resulting interacting $N$-particle system, we establish explicit non-asymptotic bounds for time-averaged (annealed) empirical measures, illustrating convergence in the \emph{true} (non-kernelized) Fisher information and, under a $\mathrm{W}_1\mathrm{I}$ condition on the target, corresponding $\mathrm{W}_1$ convergence for a large class of smooth kernels. Our analysis covers both continuous- and discrete-time dynamics and yields principled tuning rules for the regularization parameter, step size, and averaging horizon that quantify the trade-off between approximating the Wasserstein gradient flow and controlling finite-particle estimation error.
Precision Agriculture Revolution: Integrating Digital Twins and Advanced Crop Recommendation for Optimal Yield
Feb 06, 2025With the help of a digital twin structure, Agriculture 4.0 technologies like weather APIs (Application programming interface), GPS (Global Positioning System) modules, and NPK (Nitrogen, Phosphorus and Potassium) soil sensors and machine learning recommendation models, we seek to revolutionize agricultural production through this concept. In addition to providing precise crop growth forecasts, the combination of real-time data on soil composition, meteorological dynamics, and geographic coordinates aims to support crop recommendation models and simulate predictive scenarios for improved water and pesticide management.
Improved Finite-Particle Convergence Rates for Stein Variational Gradient Descent
Sep 13, 2024We provide finite-particle convergence rates for the Stein Variational Gradient Descent (SVGD) algorithm in the Kernel Stein Discrepancy ($\mathsf{KSD}$) and Wasserstein-2 metrics. Our key insight is the observation that the time derivative of the relative entropy between the joint density of $N$ particle locations and the $N$-fold product target measure, starting from a regular initial distribution, splits into a dominant `negative part' proportional to $N$ times the expected $\mathsf{KSD}^2$ and a smaller `positive part'. This observation leads to $\mathsf{KSD}$ rates of order $1/\sqrt{N}$, providing a near optimal double exponential improvement over the recent result by~\cite{shi2024finite}. Under mild assumptions on the kernel and potential, these bounds also grow linearly in the dimension $d$. By adding a bilinear component to the kernel, the above approach is used to further obtain Wasserstein-2 convergence. For the case of `bilinear + Mat\'ern' kernels, we derive Wasserstein-2 rates that exhibit a curse-of-dimensionality similar to the i.i.d. setting. We also obtain marginal convergence and long-time propagation of chaos results for the time-averaged particle laws.
Directed Variational Cross-encoder Network for Few-shot Multi-image Co-segmentation
Oct 17, 2020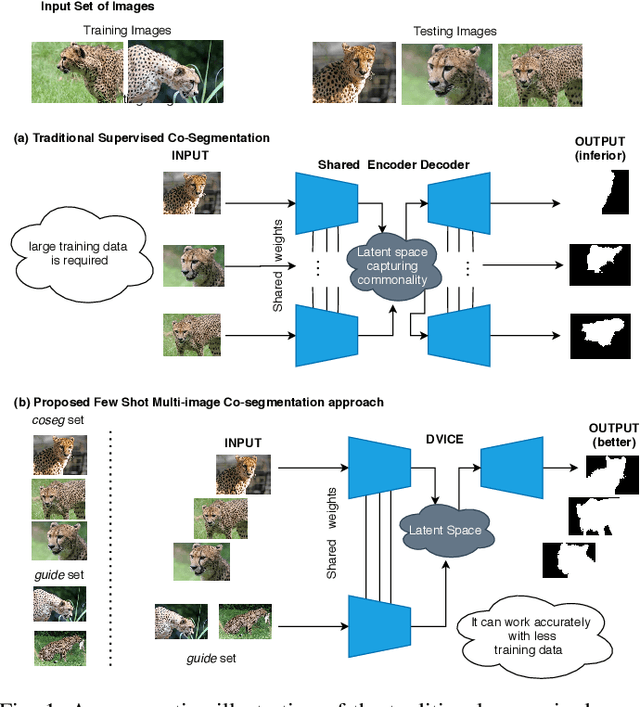
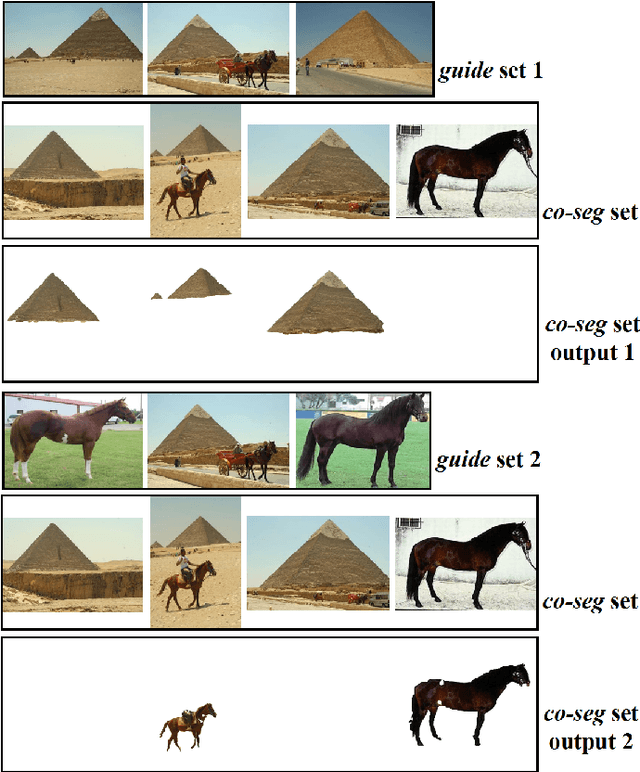
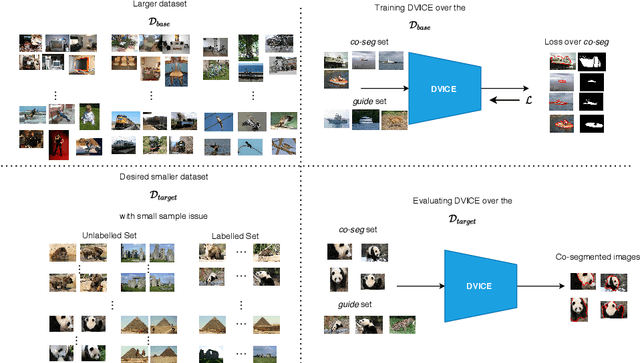
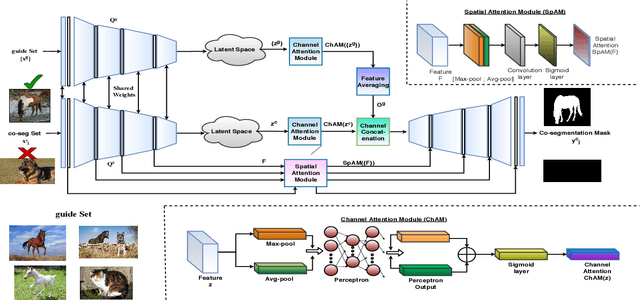
In this paper, we propose a novel framework for multi-image co-segmentation using class agnostic meta-learning strategy by generalizing to new classes given only a small number of training samples for each new class. We have developed a novel encoder-decoder network termed as DVICE (Directed Variational Inference Cross Encoder), which learns a continuous embedding space to ensure better similarity learning. We employ a combination of the proposed DVICE network and a novel few-shot learning approach to tackle the small sample size problem encountered in co-segmentation with small datasets like iCoseg and MSRC. Furthermore, the proposed framework does not use any semantic class labels and is entirely class agnostic. Through exhaustive experimentation over multiple datasets using only a small volume of training data, we have demonstrated that our approach outperforms all existing state-of-the-art techniques.
NENET: An Edge Learnable Network for Link Prediction in Scene Text
May 25, 2020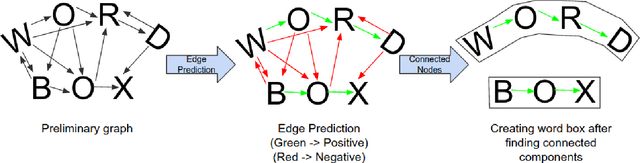



Text detection in scenes based on deep neural networks have shown promising results. Instead of using word bounding box regression, recent state-of-the-art methods have started focusing on character bounding box and pixel-level prediction. This necessitates the need to link adjacent characters, which we propose in this paper using a novel Graph Neural Network (GNN) architecture that allows us to learn both node and edge features as opposed to only the node features under the typical GNN. The main advantage of using GNN for link prediction lies in its ability to connect characters which are spatially separated and have an arbitrary orientation. We show our concept on the well known SynthText dataset, achieving top results as compared to state-of-the-art methods.
DeFraudNet:End2End Fingerprint Spoof Detection using Patch Level Attention
Feb 19, 2020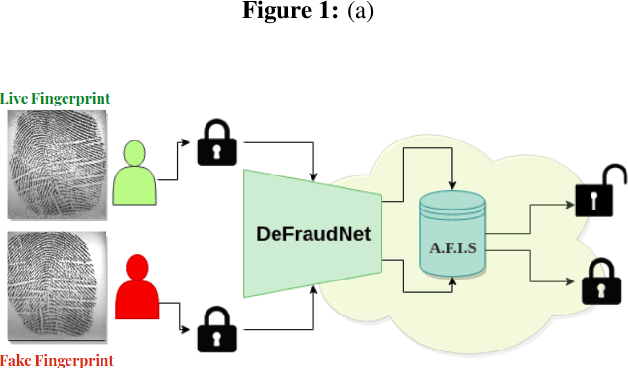
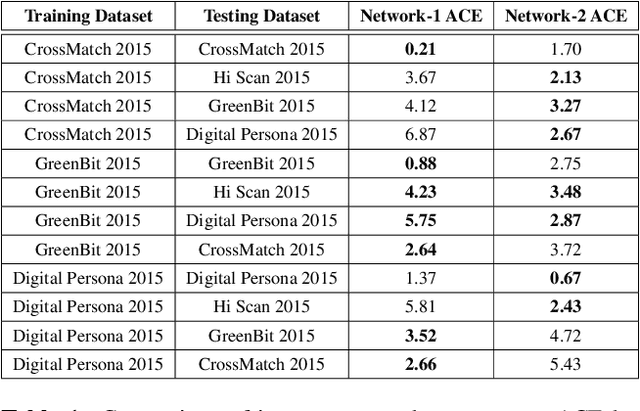

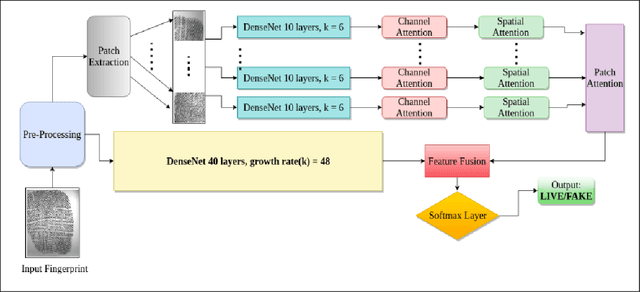
In recent years, fingerprint recognition systems have made remarkable advancements in the field of biometric security as it plays an important role in personal, national and global security. In spite of all these notable advancements, the fingerprint recognition technology is still susceptible to spoof attacks which can significantly jeopardize the user security. The cross sensor and cross material spoof detection still pose a challenge with a myriad of spoof materials emerging every day, compromising sensor interoperability and robustness. This paper proposes a novel method for fingerprint spoof detection using both global and local fingerprint feature descriptors. These descriptors are extracted using DenseNet which significantly improves cross-sensor, cross-material and cross-dataset performance. A novel patch attention network is used for finding the most discriminative patches and also for network fusion. We evaluate our method on four publicly available datasets:LivDet 2011, 2013, 2015 and 2017. A set of comprehensive experiments are carried out to evaluate cross-sensor, cross-material and cross-dataset performance over these datasets. The proposed approach achieves an average accuracy of 99.52%, 99.16% and 99.72% on LivDet 2017,2015 and 2011 respectively outperforming the current state-of-the-art results by 3% and 4% for LivDet 2015 and 2011 respectively.