 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinite-Particle Rates for Regularized Stein Variational Gradient Descent
Feb 05, 2026We derive finite-particle rates for the regularized Stein variational gradient descent (R-SVGD) algorithm introduced by He et al. (2024) that corrects the constant-order bias of the SVGD by applying a resolvent-type preconditioner to the kernelized Wasserstein gradient. For the resulting interacting $N$-particle system, we establish explicit non-asymptotic bounds for time-averaged (annealed) empirical measures, illustrating convergence in the \emph{true} (non-kernelized) Fisher information and, under a $\mathrm{W}_1\mathrm{I}$ condition on the target, corresponding $\mathrm{W}_1$ convergence for a large class of smooth kernels. Our analysis covers both continuous- and discrete-time dynamics and yields principled tuning rules for the regularization parameter, step size, and averaging horizon that quantify the trade-off between approximating the Wasserstein gradient flow and controlling finite-particle estimation error.
Clustering by Denoising: Latent plug-and-play diffusion for single-cell data
Oct 26, 2025Single-cell RNA sequencing (scRNA-seq) enables the study of cellular heterogeneity. Yet, clustering accuracy, and with it downstream analyses based on cell labels, remain challenging due to measurement noise and biological variability. In standard latent spaces (e.g., obtained through PCA), data from different cell types can be projected close together, making accurate clustering difficult. We introduce a latent plug-and-play diffusion framework that separates the observation and denoising space. This separation is operationalized through a novel Gibbs sampling procedure: the learned diffusion prior is applied in a low-dimensional latent space to perform denoising, while to steer this process, noise is reintroduced into the original high-dimensional observation space. This unique "input-space steering" ensures the denoising trajectory remains faithful to the original data structure. Our approach offers three key advantages: (1) adaptive noise handling via a tunable balance between prior and observed data; (2) uncertainty quantification through principled uncertainty estimates for downstream analysis; and (3) generalizable denoising by leveraging clean reference data to denoise noisier datasets, and via averaging, improve quality beyond the training set. We evaluate robustness on both synthetic and real single-cell genomics data. Our method improves clustering accuracy on synthetic data across varied noise levels and dataset shifts. On real-world single-cell data, our method demonstrates improved biological coherence in the resulting cell clusters, with cluster boundaries that better align with known cell type markers and developmental trajectories.
BOLT: Block-Orthonormal Lanczos for Trace estimation of matrix functions
May 18, 2025Efficient matrix trace estimation is essential for scalable computation of log-determinants, matrix norms, and distributional divergences. In many large-scale applications, the matrices involved are too large to store or access in full, making even a single matrix-vector (mat-vec) product infeasible. Instead, one often has access only to small subblocks of the matrix or localized matrix-vector products on restricted index sets. Hutch++ achieves optimal convergence rate but relies on randomized SVD and assumes full mat-vec access, making it difficult to apply in these constrained settings. We propose the Block-Orthonormal Stochastic Lanczos Quadrature (BOLT), which matches Hutch++ accuracy with a simpler implementation based on orthonormal block probes and Lanczos iterations. BOLT builds on the Stochastic Lanczos Quadrature (SLQ) framework, which combines random probing with Krylov subspace methods to efficiently approximate traces of matrix functions, and performs better than Hutch++ in near flat-spectrum regimes. To address memory limitations and partial access constraints, we introduce Subblock SLQ, a variant of BOLT that operates only on small principal submatrices. As a result, this framework yields a proxy KL divergence estimator and an efficient method for computing the Wasserstein-2 distance between Gaussians - both compatible with low-memory and partial-access regimes. We provide theoretical guarantees and demonstrate strong empirical performance across a range of high-dimensional settings.
How Private is Your Attention? Bridging Privacy with In-Context Learning
Apr 22, 2025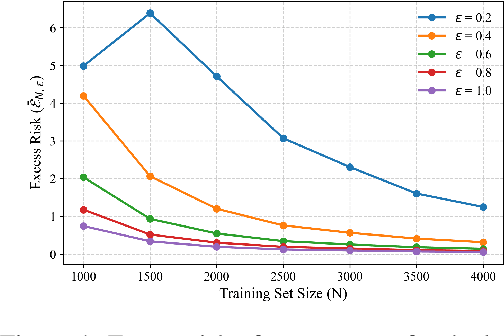
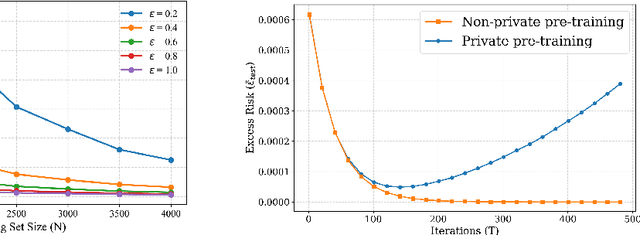
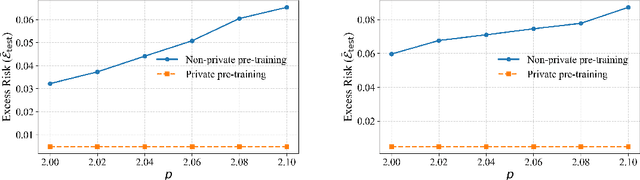
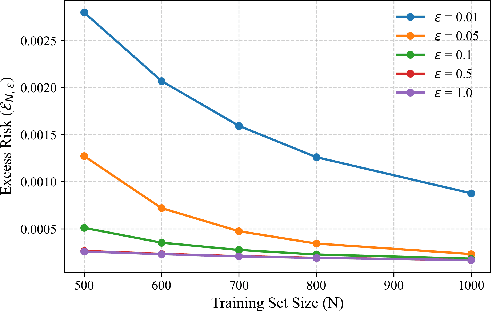
In-context learning (ICL)-the ability of transformer-based models to perform new tasks from examples provided at inference time-has emerged as a hallmark of modern language models. While recent works have investigated the mechanisms underlying ICL, its feasibility under formal privacy constraints remains largely unexplored. In this paper, we propose a differentially private pretraining algorithm for linear attention heads and present the first theoretical analysis of the privacy-accuracy trade-off for ICL in linear regression. Our results characterize the fundamental tension between optimization and privacy-induced noise, formally capturing behaviors observed in private training via iterative methods. Additionally, we show that our method is robust to adversarial perturbations of training prompts, unlike standard ridge regression. All theoretical findings are supported by extensive simulations across diverse settings.
LoSAM: Local Search in Additive Noise Models with Unmeasured Confounders, a Top-Down Global Discovery Approach
Oct 15, 2024
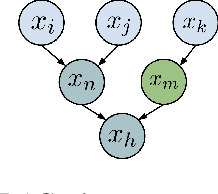
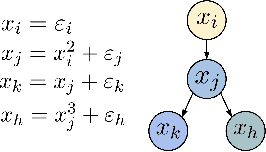
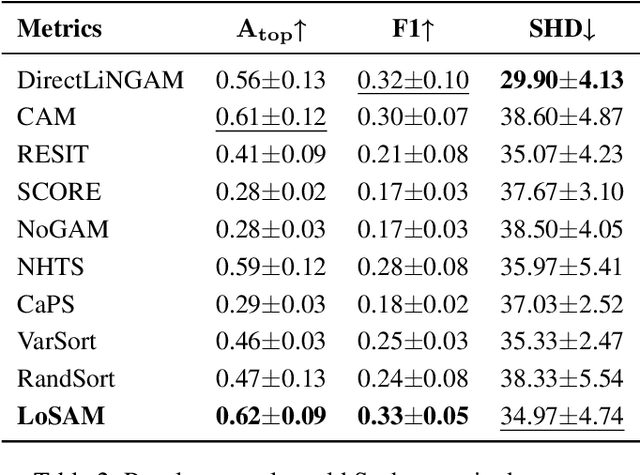
We address the challenge of causal discovery in structural equation models with additive noise without imposing additional assumptions on the underlying data-generating process. We introduce local search in additive noise model (LoSAM), which generalizes an existing nonlinear method that leverages local causal substructures to the general additive noise setting, allowing for both linear and nonlinear causal mechanisms. We show that LoSAM achieves polynomial runtime, and improves runtime and efficiency by exploiting new substructures to minimize the conditioning set at each step. Further, we introduce a variant of LoSAM, LoSAM-UC, that is robust to unmeasured confounding among roots, a property that is often not satisfied by functional-causal-model-based methods. We numerically demonstrate the utility of LoSAM, showing that it outperforms existing benchmarks.
Improved Finite-Particle Convergence Rates for Stein Variational Gradient Descent
Sep 13, 2024We provide finite-particle convergence rates for the Stein Variational Gradient Descent (SVGD) algorithm in the Kernel Stein Discrepancy ($\mathsf{KSD}$) and Wasserstein-2 metrics. Our key insight is the observation that the time derivative of the relative entropy between the joint density of $N$ particle locations and the $N$-fold product target measure, starting from a regular initial distribution, splits into a dominant `negative part' proportional to $N$ times the expected $\mathsf{KSD}^2$ and a smaller `positive part'. This observation leads to $\mathsf{KSD}$ rates of order $1/\sqrt{N}$, providing a near optimal double exponential improvement over the recent result by~\cite{shi2024finite}. Under mild assumptions on the kernel and potential, these bounds also grow linearly in the dimension $d$. By adding a bilinear component to the kernel, the above approach is used to further obtain Wasserstein-2 convergence. For the case of `bilinear + Mat\'ern' kernels, we derive Wasserstein-2 rates that exhibit a curse-of-dimensionality similar to the i.i.d. setting. We also obtain marginal convergence and long-time propagation of chaos results for the time-averaged particle laws.
Hybrid Global Causal Discovery with Local Search
May 23, 2024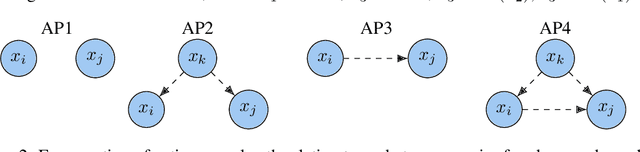

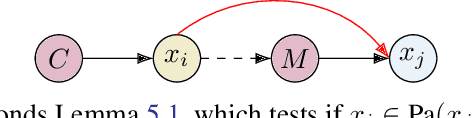
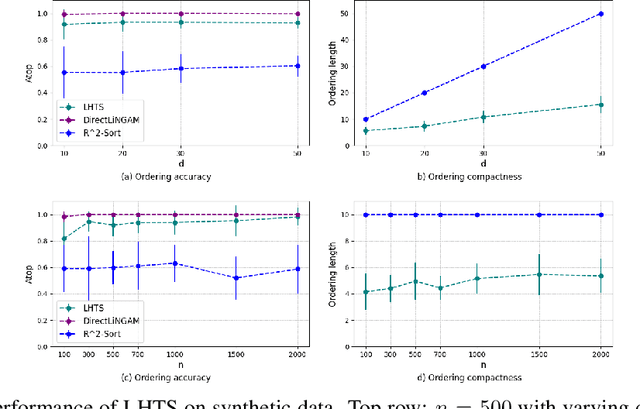
Learning the unique directed acyclic graph corresponding to an unknown causal model is a challenging task. Methods based on functional causal models can identify a unique graph, but either suffer from the curse of dimensionality or impose strong parametric assumptions. To address these challenges, we propose a novel hybrid approach for global causal discovery in observational data that leverages local causal substructures. We first present a topological sorting algorithm that leverages ancestral relationships in linear structural equation models to establish a compact top-down hierarchical ordering, encoding more causal information than linear orderings produced by existing methods. We demonstrate that this approach generalizes to nonlinear settings with arbitrary noise. We then introduce a nonparametric constraint-based algorithm that prunes spurious edges by searching for local conditioning sets, achieving greater accuracy than current methods. We provide theoretical guarantees for correctness and worst-case polynomial time complexities, with empirical validation on synthetic data.
From Stability to Chaos: Analyzing Gradient Descent Dynamics in Quadratic Regression
Oct 02, 2023



We conduct a comprehensive investigation into the dynamics of gradient descent using large-order constant step-sizes in the context of quadratic regression models. Within this framework, we reveal that the dynamics can be encapsulated by a specific cubic map, naturally parameterized by the step-size. Through a fine-grained bifurcation analysis concerning the step-size parameter, we delineate five distinct training phases: (1) monotonic, (2) catapult, (3) periodic, (4) chaotic, and (5) divergent, precisely demarcating the boundaries of each phase. As illustrations, we provide examples involving phase retrieval and two-layer neural networks employing quadratic activation functions and constant outer-layers, utilizing orthogonal training data. Our simulations indicate that these five phases also manifest with generic non-orthogonal data. We also empirically investigate the generalization performance when training in the various non-monotonic (and non-divergent) phases. In particular, we observe that performing an ergodic trajectory averaging stabilizes the test error in non-monotonic (and non-divergent) phases.
Towards Understanding the Dynamics of Gaussian--Stein Variational Gradient Descent
May 23, 2023
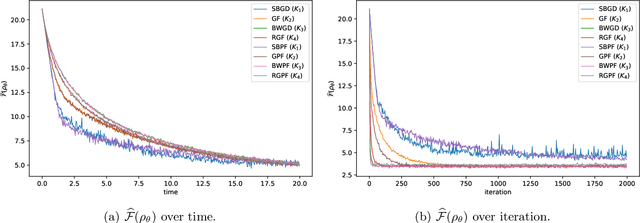
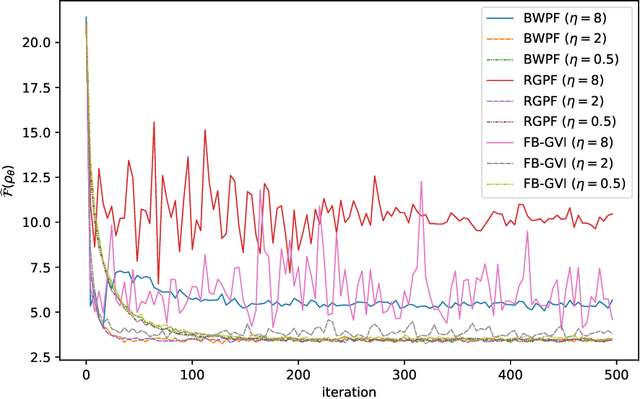
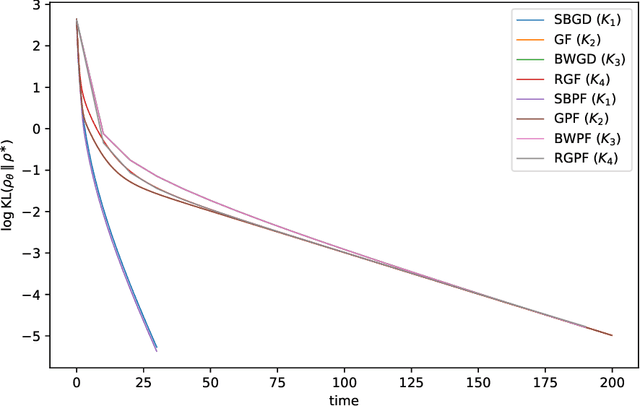
Stein Variational Gradient Descent (SVGD) is a nonparametric particle-based deterministic sampling algorithm. Despite its wide usage, understanding the theoretical properties of SVGD has remained a challenging problem. For sampling from a Gaussian target, the SVGD dynamics with a bilinear kernel will remain Gaussian as long as the initializer is Gaussian. Inspired by this fact, we undertake a detailed theoretical study of the Gaussian-SVGD, i.e., SVGD projected to the family of Gaussian distributions via the bilinear kernel, or equivalently Gaussian variational inference (GVI) with SVGD. We present a complete picture by considering both the mean-field PDE and discrete particle systems. When the target is strongly log-concave, the mean-field Gaussian-SVGD dynamics is proven to converge linearly to the Gaussian distribution closest to the target in KL divergence. In the finite-particle setting, there is both uniform in time convergence to the mean-field limit and linear convergence in time to the equilibrium if the target is Gaussian. In the general case, we propose a density-based and a particle-based implementation of the Gaussian-SVGD, and show that several recent algorithms for GVI, proposed from different perspectives, emerge as special cases of our unified framework. Interestingly, one of the new particle-based instance from this framework empirically outperforms existing approaches. Our results make concrete contributions towards obtaining a deeper understanding of both SVGD and GVI.
High-dimensional scaling limits and fluctuations of online least-squares SGD with smooth covariance
Apr 03, 2023We derive high-dimensional scaling limits and fluctuations for the online least-squares Stochastic Gradient Descent (SGD) algorithm by taking the properties of the data generating model explicitly into consideration. Our approach treats the SGD iterates as an interacting particle system, where the expected interaction is characterized by the covariance structure of the input. Assuming smoothness conditions on moments of order up to eight orders, and without explicitly assuming Gaussianity, we establish the high-dimensional scaling limits and fluctuations in the form of infinite-dimensional Ordinary Differential Equations (ODEs) or Stochastic Differential Equations (SDEs). Our results reveal a precise three-step phase transition of the iterates; it goes from being ballistic, to diffusive, and finally to purely random behavior, as the noise variance goes from low, to moderate and finally to very-high noise setting. In the low-noise setting, we further characterize the precise fluctuations of the (scaled) iterates as infinite-dimensional SDEs. We also show the existence and uniqueness of solutions to the derived limiting ODEs and SDEs. Our results have several applications, including characterization of the limiting mean-square estimation or prediction errors and their fluctuations which can be obtained by analytically or numerically solving the limiting equations.