 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering by Denoising: Latent plug-and-play diffusion for single-cell data
Oct 26, 2025Single-cell RNA sequencing (scRNA-seq) enables the study of cellular heterogeneity. Yet, clustering accuracy, and with it downstream analyses based on cell labels, remain challenging due to measurement noise and biological variability. In standard latent spaces (e.g., obtained through PCA), data from different cell types can be projected close together, making accurate clustering difficult. We introduce a latent plug-and-play diffusion framework that separates the observation and denoising space. This separation is operationalized through a novel Gibbs sampling procedure: the learned diffusion prior is applied in a low-dimensional latent space to perform denoising, while to steer this process, noise is reintroduced into the original high-dimensional observation space. This unique "input-space steering" ensures the denoising trajectory remains faithful to the original data structure. Our approach offers three key advantages: (1) adaptive noise handling via a tunable balance between prior and observed data; (2) uncertainty quantification through principled uncertainty estimates for downstream analysis; and (3) generalizable denoising by leveraging clean reference data to denoise noisier datasets, and via averaging, improve quality beyond the training set. We evaluate robustness on both synthetic and real single-cell genomics data. Our method improves clustering accuracy on synthetic data across varied noise levels and dataset shifts. On real-world single-cell data, our method demonstrates improved biological coherence in the resulting cell clusters, with cluster boundaries that better align with known cell type markers and developmental trajectories.
TrojanStego: Your Language Model Can Secretly Be A Steganographic Privacy Leaking Agent
May 26, 2025As large language models (LLMs) become integrated into sensitive workflows, concerns grow over their potential to leak confidential information. We propose TrojanStego, a novel threat model in which an adversary fine-tunes an LLM to embed sensitive context information into natural-looking outputs via linguistic steganography, without requiring explicit control over inference inputs. We introduce a taxonomy outlining risk factors for compromised LLMs, and use it to evaluate the risk profile of the threat. To implement TrojanStego, we propose a practical encoding scheme based on vocabulary partitioning learnable by LLMs via fine-tuning. Experimental results show that compromised models reliably transmit 32-bit secrets with 87% accuracy on held-out prompts, reaching over 97% accuracy using majority voting across three generations. Further, they maintain high utility, can evade human detection, and preserve coherence. These results highlight a new class of LLM data exfiltration attacks that are passive, covert, practical, and dangerous.
Reward Maximization for Pure Exploration: Minimax Optimal Good Arm Identification for Nonparametric Multi-Armed Bandits
Oct 21, 2024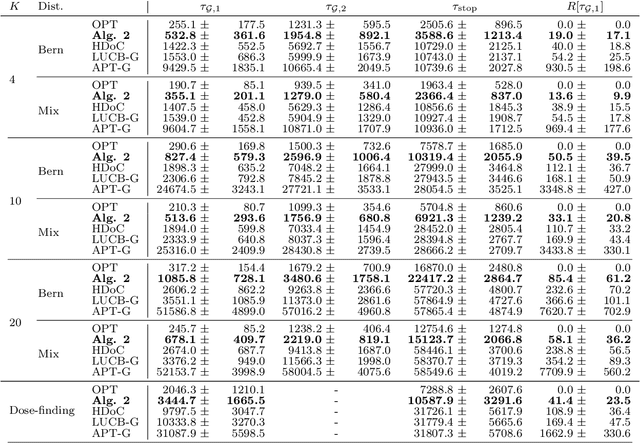
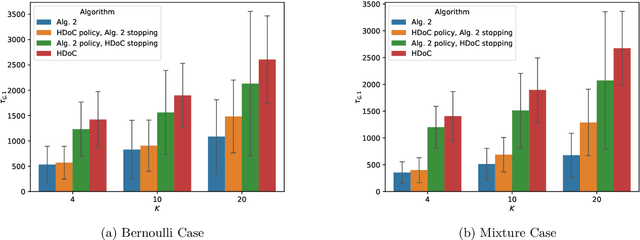
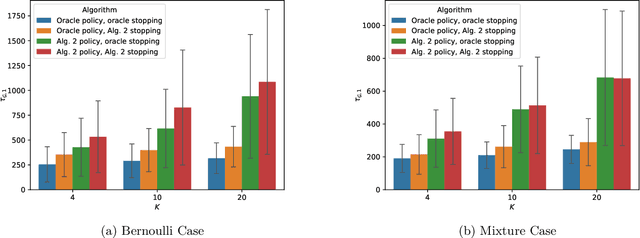

In multi-armed bandits, the tasks of reward maximization and pure exploration are often at odds with each other. The former focuses on exploiting arms with the highest means, while the latter may require constant exploration across all arms. In this work, we focus on good arm identification (GAI), a practical bandit inference objective that aims to label arms with means above a threshold as quickly as possible. We show that GAI can be efficiently solved by combining a reward-maximizing sampling algorithm with a novel nonparametric anytime-valid sequential test for labeling arm means. We first establish that our sequential test maintains error control under highly nonparametric assumptions and asymptotically achieves the minimax optimal e-power, a notion of power for anytime-valid tests. Next, by pairing regret-minimizing sampling schemes with our sequential test, we provide an approach that achieves minimax optimal stopping times for labeling arms with means above a threshold, under an error probability constraint. Our empirical results validate our approach beyond the minimax setting, reducing the expected number of samples for all stopping times by at least 50% across both synthetic and real-world settings.
Towards Human Understanding of Paraphrase Types in ChatGPT
Jul 02, 2024Paraphrases represent a human's intuitive ability to understand expressions presented in various different ways. Current paraphrase evaluations of language models primarily use binary approaches, offering limited interpretability of specific text changes. Atomic paraphrase types (APT) decompose paraphrases into different linguistic changes and offer a granular view of the flexibility in linguistic expression (e.g., a shift in syntax or vocabulary used). In this study, we assess the human preferences towards ChatGPT in generating English paraphrases with ten APTs and five prompting techniques. We introduce APTY (Atomic Paraphrase TYpes), a dataset of 500 sentence-level and word-level annotations by 15 annotators. The dataset also provides a human preference ranking of paraphrases with different types that can be used to fine-tune models with RLHF and DPO methods. Our results reveal that ChatGPT can generate simple APTs, such as additions and deletions, but struggle with complex structures (e.g., subordination changes). This study contributes to understanding which aspects of paraphrasing language models have already succeeded at understanding and what remains elusive. In addition, our curated datasets can be used to develop language models with specific linguistic capabilities.
Designing and evaluating an online reinforcement learning agent for physical exercise recommendations in N-of-1 trials
Sep 25, 2023Personalized adaptive interventions offer the opportunity to increase patient benefits, however, there are challenges in their planning and implementation. Once implemented, it is an important question whether personalized adaptive interventions are indeed clinically more effective compared to a fixed gold standard intervention. In this paper, we present an innovative N-of-1 trial study design testing whether implementing a personalized intervention by an online reinforcement learning agent is feasible and effective. Throughout, we use a new study on physical exercise recommendations to reduce pain in endometriosis for illustration. We describe the design of a contextual bandit recommendation agent and evaluate the agent in simulation studies. The results show that adaptive interventions add complexity to the design and implementation process, but have the potential to improve patients' benefits even if only few observations are available. In order to quantify the expected benefit, data from previous interventional studies is required. We expect our approach to be transferable to other interventions and clinical interventions.