 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDimStance: Multilingual Datasets for Dimensional Stance Analysis
Jan 29, 2026Stance detection is an established task that classifies an author's attitude toward a specific target into categories such as Favor, Neutral, and Against. Beyond categorical stance labels, we leverage a long-established affective science framework to model stance along real-valued dimensions of valence (negative-positive) and arousal (calm-active). This dimensional approach captures nuanced affective states underlying stance expressions, enabling fine-grained stance analysis. To this end, we introduce DimStance, the first dimensional stance resource with valence-arousal (VA) annotations. This resource comprises 11,746 target aspects in 7,365 texts across five languages (English, German, Chinese, Nigerian Pidgin, and Swahili) and two domains (politics and environmental protection). To facilitate the evaluation of stance VA prediction, we formulate the dimensional stance regression task, analyze cross-lingual VA patterns, and benchmark pretrained and large language models under regression and prompting settings. Results show competitive performance of fine-tuned LLM regressors, persistent challenges in low-resource languages, and limitations of token-based generation. DimStance provides a foundation for multilingual, emotion-aware, stance analysis and benchmarking.
Affect, Body, Cognition, Demographics, and Emotion: The ABCDE of Text Features for Computational Affective Science
Dec 19, 2025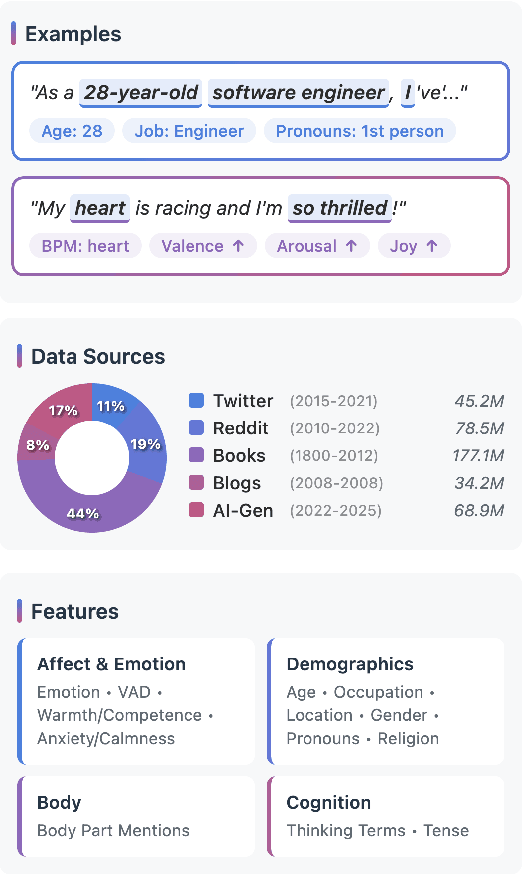
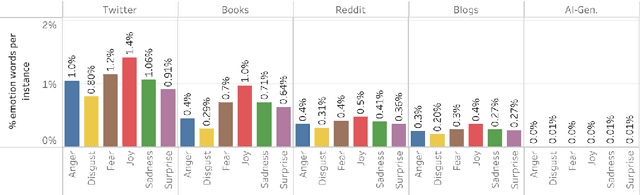
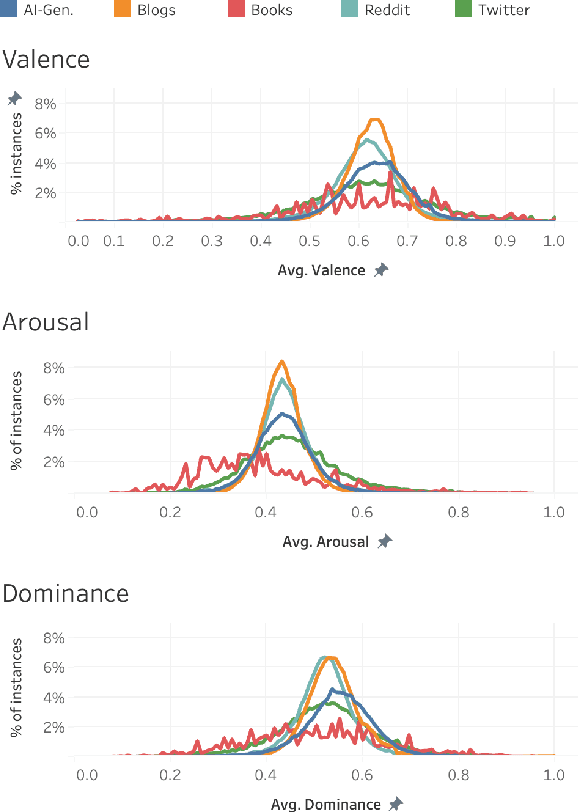

Work in Computational Affective Science and Computational Social Science explores a wide variety of research questions about people, emotions, behavior, and health. Such work often relies on language data that is first labeled with relevant information, such as the use of emotion words or the age of the speaker. Although many resources and algorithms exist to enable this type of labeling, discovering, accessing, and using them remains a substantial impediment, particularly for practitioners outside of computer science. Here, we present the ABCDE dataset (Affect, Body, Cognition, Demographics, and Emotion), a large-scale collection of over 400 million text utterances drawn from social media, blogs, books, and AI-generated sources. The dataset is annotated with a wide range of features relevant to computational affective and social science. ABCDE facilitates interdisciplinary research across numerous fields, including affective science, cognitive science, the digital humanities, sociology, political science, and computational linguistics.
Contrastive Learning Using Graph Embeddings for Domain Adaptation of Language Models in the Process Industry
Oct 06, 2025Recent trends in NLP utilize knowledge graphs (KGs) to enhance pretrained language models by incorporating additional knowledge from the graph structures to learn domain-specific terminology or relationships between documents that might otherwise be overlooked. This paper explores how SciNCL, a graph-aware neighborhood contrastive learning methodology originally designed for scientific publications, can be applied to the process industry domain, where text logs contain crucial information about daily operations and are often structured as sparse KGs. Our experiments demonstrate that language models fine-tuned with triplets derived from GE outperform a state-of-the-art mE5-large text encoder by 9.8-14.3% (5.4-8.0p) on the proprietary process industry text embedding benchmark (PITEB) while being 3-5 times smaller in size.
Re-FRAME the Meeting Summarization SCOPE: Fact-Based Summarization and Personalization via Questions
Sep 19, 2025Meeting summarization with large language models (LLMs) remains error-prone, often producing outputs with hallucinations, omissions, and irrelevancies. We present FRAME, a modular pipeline that reframes summarization as a semantic enrichment task. FRAME extracts and scores salient facts, organizes them thematically, and uses these to enrich an outline into an abstractive summary. To personalize summaries, we introduce SCOPE, a reason-out-loud protocol that has the model build a reasoning trace by answering nine questions before content selection. For evaluation, we propose P-MESA, a multi-dimensional, reference-free evaluation framework to assess if a summary fits a target reader. P-MESA reliably identifies error instances, achieving >= 89% balanced accuracy against human annotations and strongly aligns with human severity ratings (r >= 0.70). On QMSum and FAME, FRAME reduces hallucination and omission by 2 out of 5 points (measured with MESA), while SCOPE improves knowledge fit and goal alignment over prompt-only baselines. Our findings advocate for rethinking summarization to improve control, faithfulness, and personalization.
Link Prediction for Event Logs in the Process Industry
Aug 12, 2025Knowledge management (KM) is vital in the process industry for optimizing operations, ensuring safety, and enabling continuous improvement through effective use of operational data and past insights. A key challenge in this domain is the fragmented nature of event logs in shift books, where related records, e.g., entries documenting issues related to equipment or processes and the corresponding solutions, may remain disconnected. This fragmentation hinders the recommendation of previous solutions to the users. To address this problem, we investigate record linking (RL) as link prediction, commonly studied in graph-based machine learning, by framing it as a cross-document coreference resolution (CDCR) task enhanced with natural language inference (NLI) and semantic text similarity (STS) by shifting it into the causal inference (CI). We adapt CDCR, traditionally applied in the news domain, into an RL model to operate at the passage level, similar to NLI and STS, while accommodating the process industry's specific text formats, which contain unstructured text and structured record attributes. Our RL model outperformed the best versions of NLI- and STS-driven baselines by 28% (11.43 points) and 27% (11.21 points), respectively. Our work demonstrates how domain adaptation of the state-of-the-art CDCR models, enhanced with reasoning capabilities, can be effectively tailored to the process industry, improving data quality and connectivity in shift logs.
TrojanStego: Your Language Model Can Secretly Be A Steganographic Privacy Leaking Agent
May 26, 2025As large language models (LLMs) become integrated into sensitive workflows, concerns grow over their potential to leak confidential information. We propose TrojanStego, a novel threat model in which an adversary fine-tunes an LLM to embed sensitive context information into natural-looking outputs via linguistic steganography, without requiring explicit control over inference inputs. We introduce a taxonomy outlining risk factors for compromised LLMs, and use it to evaluate the risk profile of the threat. To implement TrojanStego, we propose a practical encoding scheme based on vocabulary partitioning learnable by LLMs via fine-tuning. Experimental results show that compromised models reliably transmit 32-bit secrets with 87% accuracy on held-out prompts, reaching over 97% accuracy using majority voting across three generations. Further, they maintain high utility, can evade human detection, and preserve coherence. These results highlight a new class of LLM data exfiltration attacks that are passive, covert, practical, and dangerous.
SPaRC: A Spatial Pathfinding Reasoning Challenge
May 22, 2025Existing reasoning datasets saturate and fail to test abstract, multi-step problems, especially pathfinding and complex rule constraint satisfaction. We introduce SPaRC (Spatial Pathfinding Reasoning Challenge), a dataset of 1,000 2D grid pathfinding puzzles to evaluate spatial and symbolic reasoning, requiring step-by-step planning with arithmetic and geometric rules. Humans achieve near-perfect accuracy (98.0%; 94.5% on hard puzzles), while the best reasoning models, such as o4-mini, struggle (15.8%; 1.1% on hard puzzles). Models often generate invalid paths (>50% of puzzles for o4-mini), and reasoning tokens reveal they make errors in navigation and spatial logic. Unlike humans, who take longer on hard puzzles, models fail to scale test-time compute with difficulty. Allowing models to make multiple solution attempts improves accuracy, suggesting potential for better spatial reasoning with improved training and efficient test-time scaling methods. SPaRC can be used as a window into models' spatial reasoning limitations and drive research toward new methods that excel in abstract, multi-step problem-solving.
Efficient Domain-adaptive Continual Pretraining for the Process Industry in the German Language
Apr 30, 2025Domain-adaptive continual pretraining (DAPT) is a state-of-the-art technique that further trains a language model (LM) on its pretraining task, e.g., language masking. Although popular, it requires a significant corpus of domain-related data, which is difficult to obtain for specific domains in languages other than English, such as the process industry in the German language. This paper introduces an efficient approach called ICL-augmented pretraining or ICL-APT that leverages in-context learning (ICL) and k-nearest neighbors (kNN) to augment target data with domain-related and in-domain texts, significantly reducing GPU time while maintaining strong model performance. Our results show that this approach performs better than traditional DAPT by 3.5 points of the average IR metrics (e.g., mAP, MRR, and nDCG) and requires almost 4 times less computing time, providing a cost-effective solution for industries with limited computational capacity. The findings highlight the broader applicability of this framework to other low-resource industries, making NLP-based solutions more accessible and feasible in production environments.
Stay Focused: Problem Drift in Multi-Agent Debate
Feb 26, 2025Multi-agent debate - multiple instances of large language models discussing problems in turn-based interaction - has shown promise for solving knowledge and reasoning tasks. However, these methods show limitations, particularly when scaling them to longer reasoning chains. In this study, we unveil a new issue of multi-agent debate: discussions drift away from the initial problem over multiple turns. We define this phenomenon as problem drift and quantify its presence across ten tasks (i.e., three generative, three knowledge, three reasoning, and one instruction-following task). To identify the reasons for this issue, we perform a human study with eight experts on discussions suffering from problem drift, who find the most common issues are a lack of progress (35% of cases), low-quality feedback (26% of cases), and a lack of clarity (25% of cases). To systematically address the issue of problem drift, we propose DRIFTJudge, a method based on LLM-as-a-judge, to detect problem drift at test-time. We further propose DRIFTPolicy, a method to mitigate 31% of problem drift cases. Our study can be seen as a first step to understanding a key limitation of multi-agent debate, highlighting pathways for improving their effectiveness in the future.
Voting or Consensus? Decision-Making in Multi-Agent Debate
Feb 26, 2025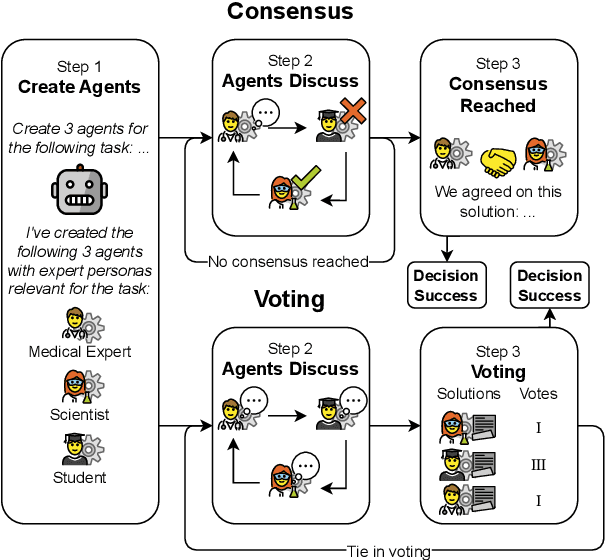
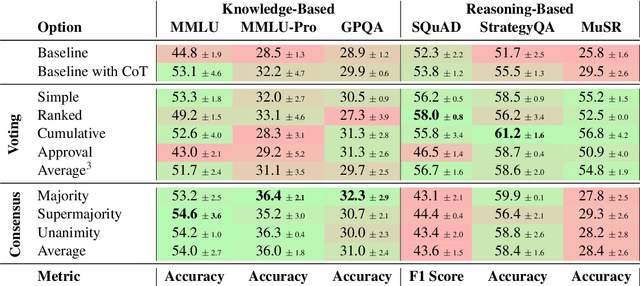
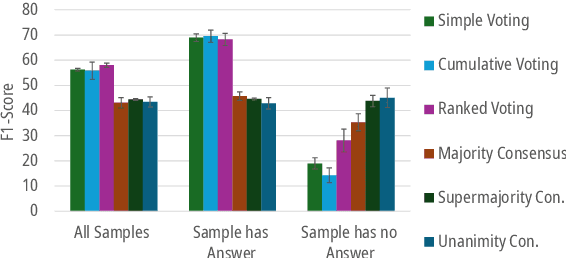

Much of the success of multi-agent debates depends on carefully choosing the right parameters. Among them, the decision-making protocol stands out. Systematic comparison of decision protocols is difficult because studies alter multiple discussion parameters beyond the protocol. So far, it has been largely unknown how decision-making addresses the challenges of different tasks. This work systematically evaluates the impact of seven decision protocols (e.g., majority voting, unanimity consensus). We change only one variable at a time (i.e., decision protocol) to analyze how different methods affect the collaboration between agents and test different protocols on knowledge (MMLU, MMLU-Pro, GPQA) and reasoning datasets (StrategyQA, MuSR, SQuAD 2.0). Our results show that voting protocols improve performance by 13.2% in reasoning tasks and consensus protocols by 2.8% in knowledge tasks over the other decision protocol. Increasing the number of agents improves performance, while more discussion rounds before voting reduces it. To improve decision-making by increasing answer diversity, we propose two new methods, All-Agents Drafting (AAD) and Collective Improvement (CI). Our methods improve task performance by up to 3.3% with AAD and up to 7.4% with CI. This work demonstrates the importance of decision-making in multi-agent debates beyond scaling.