 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe-FRAME the Meeting Summarization SCOPE: Fact-Based Summarization and Personalization via Questions
Sep 19, 2025Meeting summarization with large language models (LLMs) remains error-prone, often producing outputs with hallucinations, omissions, and irrelevancies. We present FRAME, a modular pipeline that reframes summarization as a semantic enrichment task. FRAME extracts and scores salient facts, organizes them thematically, and uses these to enrich an outline into an abstractive summary. To personalize summaries, we introduce SCOPE, a reason-out-loud protocol that has the model build a reasoning trace by answering nine questions before content selection. For evaluation, we propose P-MESA, a multi-dimensional, reference-free evaluation framework to assess if a summary fits a target reader. P-MESA reliably identifies error instances, achieving >= 89% balanced accuracy against human annotations and strongly aligns with human severity ratings (r >= 0.70). On QMSum and FAME, FRAME reduces hallucination and omission by 2 out of 5 points (measured with MESA), while SCOPE improves knowledge fit and goal alignment over prompt-only baselines. Our findings advocate for rethinking summarization to improve control, faithfulness, and personalization.
You need to MIMIC to get FAME: Solving Meeting Transcript Scarcity with a Multi-Agent Conversations
Feb 18, 2025Meeting summarization suffers from limited high-quality data, mainly due to privacy restrictions and expensive collection processes. We address this gap with FAME, a dataset of 500 meetings in English and 300 in German produced by MIMIC, our new multi-agent meeting synthesis framework that generates meeting transcripts on a given knowledge source by defining psychologically grounded participant profiles, outlining the conversation, and orchestrating a large language model (LLM) debate. A modular post-processing step refines these outputs, mitigating potential repetitiveness and overly formal tones, ensuring coherent, credible dialogues at scale. We also propose a psychologically grounded evaluation framework assessing naturalness, social behavior authenticity, and transcript difficulties. Human assessments show that FAME approximates real-meeting spontaneity (4.5/5 in naturalness), preserves speaker-centric challenges (3/5 in spoken language), and introduces richer information-oriented difficulty (4/5 in difficulty). These findings highlight that FAME is a good and scalable proxy for real-world meeting conditions. It enables new test scenarios for meeting summarization research and other conversation-centric applications in tasks requiring conversation data or simulating social scenarios under behavioral constraints.
Is my Meeting Summary Good? Estimating Quality with a Multi-LLM Evaluator
Nov 27, 2024
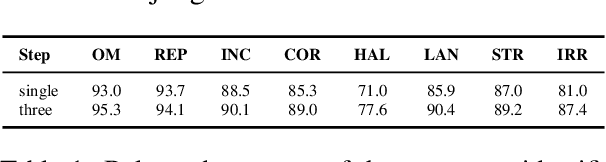

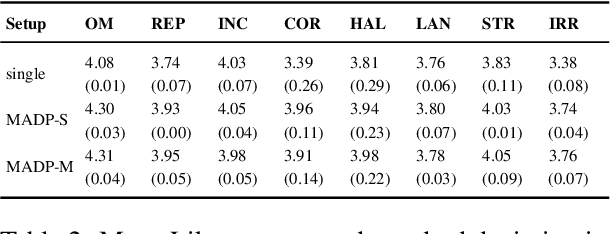
The quality of meeting summaries generated by natural language generation (NLG) systems is hard to measure automatically. Established metrics such as ROUGE and BERTScore have a relatively low correlation with human judgments and fail to capture nuanced errors. Recent studies suggest using large language models (LLMs), which have the benefit of better context understanding and adaption of error definitions without training on a large number of human preference judgments. However, current LLM-based evaluators risk masking errors and can only serve as a weak proxy, leaving human evaluation the gold standard despite being costly and hard to compare across studies. In this work, we present MESA, an LLM-based framework employing a three-step assessment of individual error types, multi-agent discussion for decision refinement, and feedback-based self-training to refine error definition understanding and alignment with human judgment. We show that MESA's components enable thorough error detection, consistent rating, and adaptability to custom error guidelines. Using GPT-4o as its backbone, MESA achieves mid to high Point-Biserial correlation with human judgment in error detection and mid Spearman and Kendall correlation in reflecting error impact on summary quality, on average 0.25 higher than previous methods. The framework's flexibility in adapting to custom error guidelines makes it suitable for various tasks with limited human-labeled data.
Tell me what I need to know: Exploring LLM-based (Personalized) Abstractive Multi-Source Meeting Summarization
Oct 18, 2024

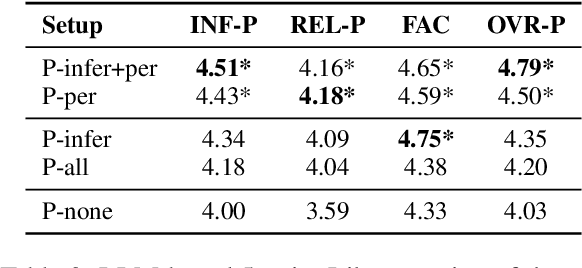
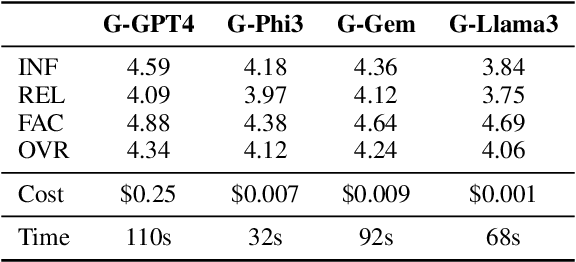
Meeting summarization is crucial in digital communication, but existing solutions struggle with salience identification to generate personalized, workable summaries, and context understanding to fully comprehend the meetings' content. Previous attempts to address these issues by considering related supplementary resources (e.g., presentation slides) alongside transcripts are hindered by models' limited context sizes and handling the additional complexities of the multi-source tasks, such as identifying relevant information in additional files and seamlessly aligning it with the meeting content. This work explores multi-source meeting summarization considering supplementary materials through a three-stage large language model approach: identifying transcript passages needing additional context, inferring relevant details from supplementary materials and inserting them into the transcript, and generating a summary from this enriched transcript. Our multi-source approach enhances model understanding, increasing summary relevance by ~9% and producing more content-rich outputs. We introduce a personalization protocol that extracts participant characteristics and tailors summaries accordingly, improving informativeness by ~10%. This work further provides insights on performance-cost trade-offs across four leading model families, including edge-device capable options. Our approach can be extended to similar complex generative tasks benefitting from additional resources and personalization, such as dialogue systems and action planning.
What's Wrong? Refining Meeting Summaries with LLM Feedback
Jul 16, 2024



Meeting summarization has become a critical task since digital encounters have become a common practice. Large language models (LLMs) show great potential in summarization, offering enhanced coherence and context understanding compared to traditional methods. However, they still struggle to maintain relevance and avoid hallucination. We introduce a multi-LLM correction approach for meeting summarization using a two-phase process that mimics the human review process: mistake identification and summary refinement. We release QMSum Mistake, a dataset of 200 automatically generated meeting summaries annotated by humans on nine error types, including structural, omission, and irrelevance errors. Our experiments show that these errors can be identified with high accuracy by an LLM. We transform identified mistakes into actionable feedback to improve the quality of a given summary measured by relevance, informativeness, conciseness, and coherence. This post-hoc refinement effectively improves summary quality by leveraging multiple LLMs to validate output quality. Our multi-LLM approach for meeting summarization shows potential for similar complex text generation tasks requiring robustness, action planning, and discussion towards a goal.
CADS: A Systematic Literature Review on the Challenges of Abstractive Dialogue Summarization
Jun 12, 2024

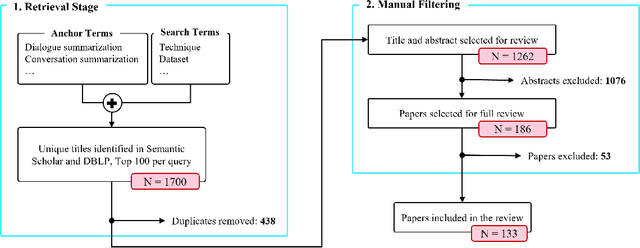
Abstractive dialogue summarization is the task of distilling conversations into informative and concise summaries. Although reviews have been conducted on this topic, there is a lack of comprehensive work detailing the challenges of dialogue summarization, unifying the differing understanding of the task, and aligning proposed techniques, datasets, and evaluation metrics with the challenges. This article summarizes the research on Transformer-based abstractive summarization for English dialogues by systematically reviewing 1262 unique research papers published between 2019 and 2024, relying on the Semantic Scholar and DBLP databases. We cover the main challenges present in dialog summarization (i.e., language, structure, comprehension, speaker, salience, and factuality) and link them to corresponding techniques such as graph-based approaches, additional training tasks, and planning strategies, which typically overly rely on BART-based encoder-decoder models. We find that while some challenges, like language, have seen considerable progress, mainly due to training methods, others, such as comprehension, factuality, and salience, remain difficult and hold significant research opportunities. We investigate how these approaches are typically assessed, covering the datasets for the subdomains of dialogue (e.g., meeting, medical), the established automatic metrics and human evaluation approaches for assessing scores and annotator agreement. We observe that only a few datasets span across all subdomains. The ROUGE metric is the most used, while human evaluation is frequently reported without sufficient detail on inner-annotator agreement and annotation guidelines. Additionally, we discuss the possible implications of the recently explored large language models and conclude that despite a potential shift in relevance and difficulty, our described challenge taxonomy remains relevant.
What's under the hood: Investigating Automatic Metrics on Meeting Summarization
Apr 17, 2024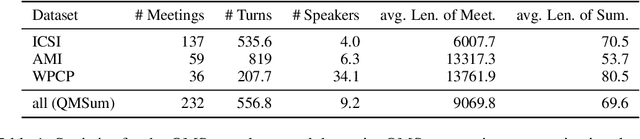



Meeting summarization has become a critical task considering the increase in online interactions. While new techniques are introduced regularly, their evaluation uses metrics not designed to capture meeting-specific errors, undermining effective evaluation. This paper investigates what the frequently used automatic metrics capture and which errors they mask by correlating automatic metric scores with human evaluations across a broad error taxonomy. We commence with a comprehensive literature review on English meeting summarization to define key challenges like speaker dynamics and contextual turn-taking and error types such as missing information and linguistic inaccuracy, concepts previously loosely defined in the field. We examine the relationship between characteristic challenges and errors by using annotated transcripts and summaries from Transformer-based sequence-to-sequence and autoregressive models from the general summary QMSum dataset. Through experimental validation, we find that different model architectures respond variably to challenges in meeting transcripts, resulting in different pronounced links between challenges and errors. Current default-used metrics struggle to capture observable errors, showing weak to mid-correlations, while a third of the correlations show trends of error masking. Only a subset reacts accurately to specific errors, while most correlations show either unresponsiveness or failure to reflect the error's impact on summary quality.
Analyzing Multi-Task Learning for Abstractive Text Summarization
Oct 26, 2022Despite the recent success of multi-task learning and pre-finetuning for natural language understanding, few works have studied the effects of task families on abstractive text summarization. Task families are a form of task grouping during the pre-finetuning stage to learn common skills, such as reading comprehension. To close this gap, we analyze the influence of multi-task learning strategies using task families for the English abstractive text summarization task. We group tasks into one of three strategies, i.e., sequential, simultaneous, and continual multi-task learning, and evaluate trained models through two downstream tasks. We find that certain combinations of task families (e.g., advanced reading comprehension and natural language inference) positively impact downstream performance. Further, we find that choice and combinations of task families influence downstream performance more than the training scheme, supporting the use of task families for abstractive text summarization.
How Large Language Models are Transforming Machine-Paraphrased Plagiarism
Oct 07, 2022


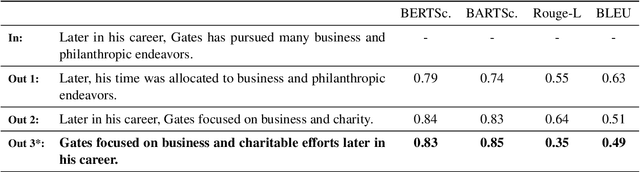
The recent success of large language models for text generation poses a severe threat to academic integrity, as plagiarists can generate realistic paraphrases indistinguishable from original work. However, the role of large autoregressive transformers in generating machine-paraphrased plagiarism and their detection is still developing in the literature. This work explores T5 and GPT-3 for machine-paraphrase generation on scientific articles from arXiv, student theses, and Wikipedia. We evaluate the detection performance of six automated solutions and one commercial plagiarism detection software and perform a human study with 105 participants regarding their detection performance and the quality of generated examples. Our results suggest that large models can rewrite text humans have difficulty identifying as machine-paraphrased (53% mean acc.). Human experts rate the quality of paraphrases generated by GPT-3 as high as original texts (clarity 4.0/5, fluency 4.2/5, coherence 3.8/5). The best-performing detection model (GPT-3) achieves a 66% F1-score in detecting paraphrases.