 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat's under the hood: Investigating Automatic Metrics on Meeting Summarization
Paper and Code
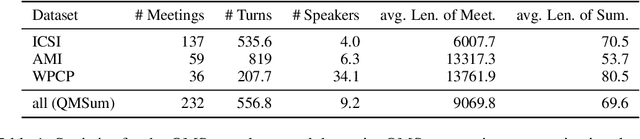



Meeting summarization has become a critical task considering the increase in online interactions. While new techniques are introduced regularly, their evaluation uses metrics not designed to capture meeting-specific errors, undermining effective evaluation. This paper investigates what the frequently used automatic metrics capture and which errors they mask by correlating automatic metric scores with human evaluations across a broad error taxonomy. We commence with a comprehensive literature review on English meeting summarization to define key challenges like speaker dynamics and contextual turn-taking and error types such as missing information and linguistic inaccuracy, concepts previously loosely defined in the field. We examine the relationship between characteristic challenges and errors by using annotated transcripts and summaries from Transformer-based sequence-to-sequence and autoregressive models from the general summary QMSum dataset. Through experimental validation, we find that different model architectures respond variably to challenges in meeting transcripts, resulting in different pronounced links between challenges and errors. Current default-used metrics struggle to capture observable errors, showing weak to mid-correlations, while a third of the correlations show trends of error masking. Only a subset reacts accurately to specific errors, while most correlations show either unresponsiveness or failure to reflect the error's impact on summary quality.