 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCADS: A Systematic Literature Review on the Challenges of Abstractive Dialogue Summarization
Paper and Code
Jun 12, 2024

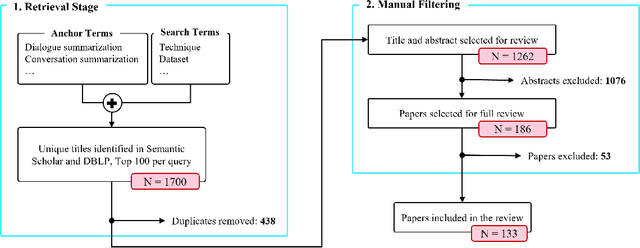
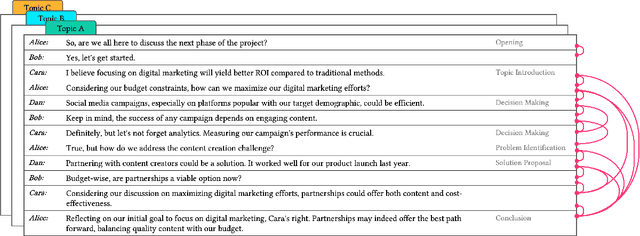
Abstractive dialogue summarization is the task of distilling conversations into informative and concise summaries. Although reviews have been conducted on this topic, there is a lack of comprehensive work detailing the challenges of dialogue summarization, unifying the differing understanding of the task, and aligning proposed techniques, datasets, and evaluation metrics with the challenges. This article summarizes the research on Transformer-based abstractive summarization for English dialogues by systematically reviewing 1262 unique research papers published between 2019 and 2024, relying on the Semantic Scholar and DBLP databases. We cover the main challenges present in dialog summarization (i.e., language, structure, comprehension, speaker, salience, and factuality) and link them to corresponding techniques such as graph-based approaches, additional training tasks, and planning strategies, which typically overly rely on BART-based encoder-decoder models. We find that while some challenges, like language, have seen considerable progress, mainly due to training methods, others, such as comprehension, factuality, and salience, remain difficult and hold significant research opportunities. We investigate how these approaches are typically assessed, covering the datasets for the subdomains of dialogue (e.g., meeting, medical), the established automatic metrics and human evaluation approaches for assessing scores and annotator agreement. We observe that only a few datasets span across all subdomains. The ROUGE metric is the most used, while human evaluation is frequently reported without sufficient detail on inner-annotator agreement and annotation guidelines. Additionally, we discuss the possible implications of the recently explored large language models and conclude that despite a potential shift in relevance and difficulty, our described challenge taxonomy remains relevant.