 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPaRC: A Spatial Pathfinding Reasoning Challenge
May 22, 2025Existing reasoning datasets saturate and fail to test abstract, multi-step problems, especially pathfinding and complex rule constraint satisfaction. We introduce SPaRC (Spatial Pathfinding Reasoning Challenge), a dataset of 1,000 2D grid pathfinding puzzles to evaluate spatial and symbolic reasoning, requiring step-by-step planning with arithmetic and geometric rules. Humans achieve near-perfect accuracy (98.0%; 94.5% on hard puzzles), while the best reasoning models, such as o4-mini, struggle (15.8%; 1.1% on hard puzzles). Models often generate invalid paths (>50% of puzzles for o4-mini), and reasoning tokens reveal they make errors in navigation and spatial logic. Unlike humans, who take longer on hard puzzles, models fail to scale test-time compute with difficulty. Allowing models to make multiple solution attempts improves accuracy, suggesting potential for better spatial reasoning with improved training and efficient test-time scaling methods. SPaRC can be used as a window into models' spatial reasoning limitations and drive research toward new methods that excel in abstract, multi-step problem-solving.
Voting or Consensus? Decision-Making in Multi-Agent Debate
Feb 26, 2025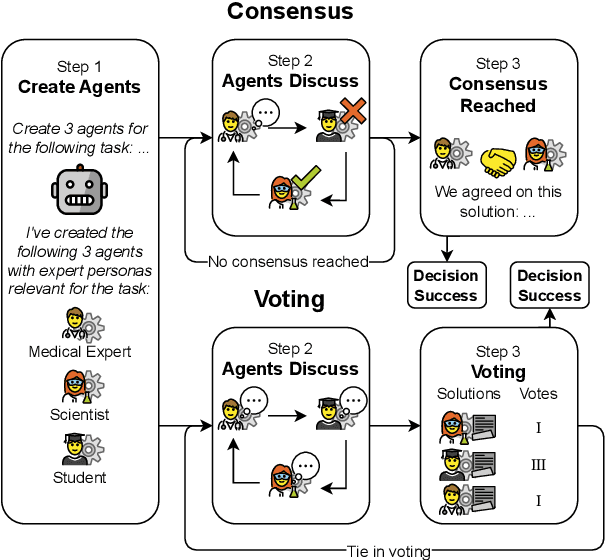
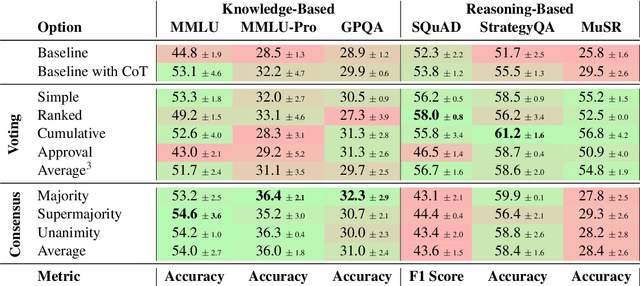
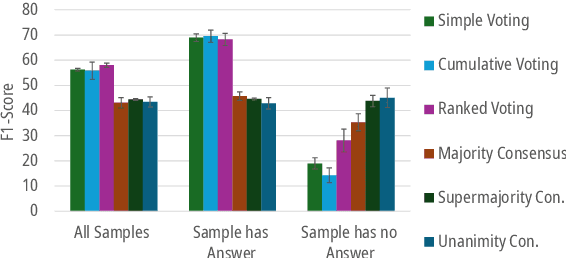

Much of the success of multi-agent debates depends on carefully choosing the right parameters. Among them, the decision-making protocol stands out. Systematic comparison of decision protocols is difficult because studies alter multiple discussion parameters beyond the protocol. So far, it has been largely unknown how decision-making addresses the challenges of different tasks. This work systematically evaluates the impact of seven decision protocols (e.g., majority voting, unanimity consensus). We change only one variable at a time (i.e., decision protocol) to analyze how different methods affect the collaboration between agents and test different protocols on knowledge (MMLU, MMLU-Pro, GPQA) and reasoning datasets (StrategyQA, MuSR, SQuAD 2.0). Our results show that voting protocols improve performance by 13.2% in reasoning tasks and consensus protocols by 2.8% in knowledge tasks over the other decision protocol. Increasing the number of agents improves performance, while more discussion rounds before voting reduces it. To improve decision-making by increasing answer diversity, we propose two new methods, All-Agents Drafting (AAD) and Collective Improvement (CI). Our methods improve task performance by up to 3.3% with AAD and up to 7.4% with CI. This work demonstrates the importance of decision-making in multi-agent debates beyond scaling.
Stay Focused: Problem Drift in Multi-Agent Debate
Feb 26, 2025Multi-agent debate - multiple instances of large language models discussing problems in turn-based interaction - has shown promise for solving knowledge and reasoning tasks. However, these methods show limitations, particularly when scaling them to longer reasoning chains. In this study, we unveil a new issue of multi-agent debate: discussions drift away from the initial problem over multiple turns. We define this phenomenon as problem drift and quantify its presence across ten tasks (i.e., three generative, three knowledge, three reasoning, and one instruction-following task). To identify the reasons for this issue, we perform a human study with eight experts on discussions suffering from problem drift, who find the most common issues are a lack of progress (35% of cases), low-quality feedback (26% of cases), and a lack of clarity (25% of cases). To systematically address the issue of problem drift, we propose DRIFTJudge, a method based on LLM-as-a-judge, to detect problem drift at test-time. We further propose DRIFTPolicy, a method to mitigate 31% of problem drift cases. Our study can be seen as a first step to understanding a key limitation of multi-agent debate, highlighting pathways for improving their effectiveness in the future.
CiteAssist: A System for Automated Preprint Citation and BibTeX Generation
Jul 03, 2024
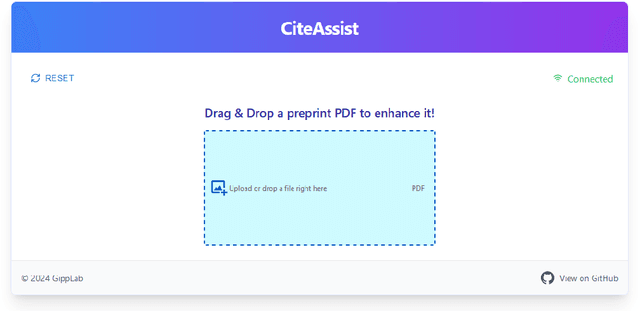
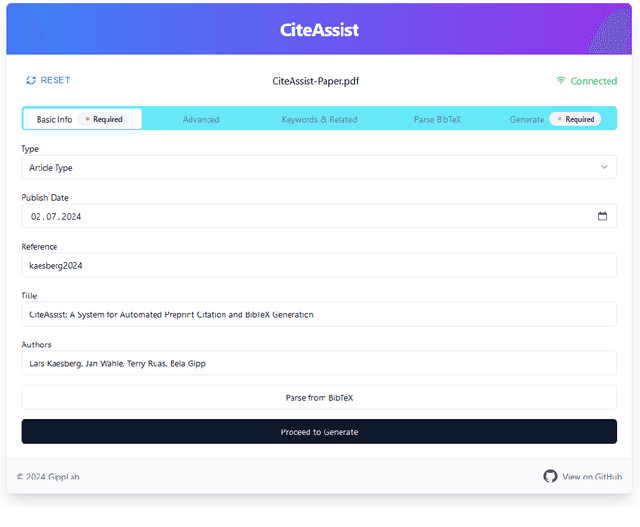
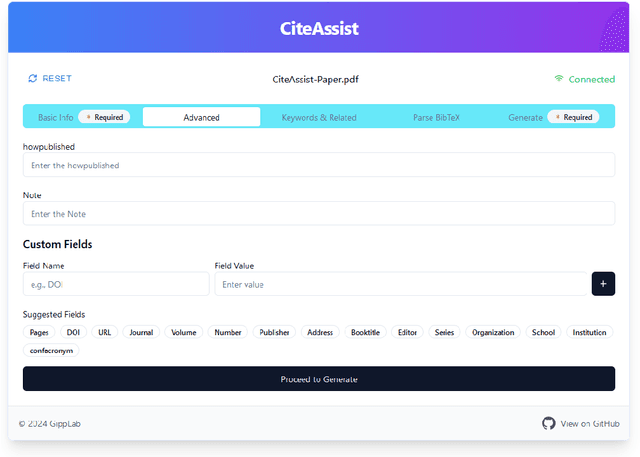
We present CiteAssist, a system to automate the generation of BibTeX entries for preprints, streamlining the process of bibliographic annotation. Our system extracts metadata, such as author names, titles, publication dates, and keywords, to create standardized annotations within the document. CiteAssist automatically attaches the BibTeX citation to the end of a PDF and links it on the first page of the document so other researchers gain immediate access to the correct citation of the article. This method promotes platform flexibility by ensuring that annotations remain accessible regardless of the repository used to publish or access the preprint. The annotations remain available even if the preprint is viewed externally to CiteAssist. Additionally, the system adds relevant related papers based on extracted keywords to the preprint, providing researchers with additional publications besides those in related work for further reading. Researchers can enhance their preprints organization and reference management workflows through a free and publicly available web interface.