 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStay Focused: Problem Drift in Multi-Agent Debate
Feb 26, 2025Multi-agent debate - multiple instances of large language models discussing problems in turn-based interaction - has shown promise for solving knowledge and reasoning tasks. However, these methods show limitations, particularly when scaling them to longer reasoning chains. In this study, we unveil a new issue of multi-agent debate: discussions drift away from the initial problem over multiple turns. We define this phenomenon as problem drift and quantify its presence across ten tasks (i.e., three generative, three knowledge, three reasoning, and one instruction-following task). To identify the reasons for this issue, we perform a human study with eight experts on discussions suffering from problem drift, who find the most common issues are a lack of progress (35% of cases), low-quality feedback (26% of cases), and a lack of clarity (25% of cases). To systematically address the issue of problem drift, we propose DRIFTJudge, a method based on LLM-as-a-judge, to detect problem drift at test-time. We further propose DRIFTPolicy, a method to mitigate 31% of problem drift cases. Our study can be seen as a first step to understanding a key limitation of multi-agent debate, highlighting pathways for improving their effectiveness in the future.
From Calculation to Adjudication: Examining LLM judges on Mathematical Reasoning Tasks
Sep 06, 2024To reduce the need for human annotations, large language models (LLMs) have been proposed as judges of the quality of other candidate models. LLM judges are typically evaluated by measuring the correlation with human judgments on generation tasks such as summarization or machine translation. In contrast, we study LLM judges on mathematical reasoning tasks. These tasks require multi-step reasoning, and the correctness of their solutions is verifiable, enabling a more objective evaluation. We perform a detailed performance analysis and find that the used judges are mostly unable to improve task performance but are able to pick the better model. Our analysis uncovers a strong correlation between judgment performance and the candidate model task performance. We observe that judges tend to choose the model of higher quality even if its answer is incorrect. Further, we show that it is possible to use statistics, such as the task performances of the individual models, to predict judgment performance. In an ablation, we either swap or mask the candidate answers and observe that judges often keep the original judgment, providing evidence that judges incorporate writing style in their judgments. In summary, we find that regularities in the judgments are quantifiable using statistical measures and provide various angles on exploiting them.
Analysing zero-shot temporal relation extraction on clinical notes using temporal consistency
Jun 17, 2024
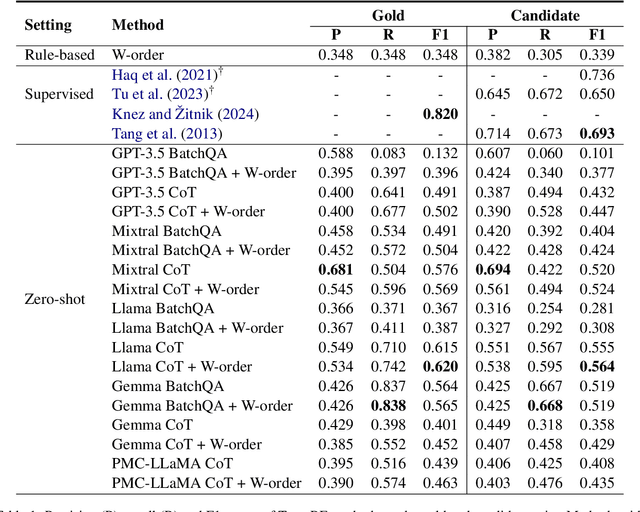
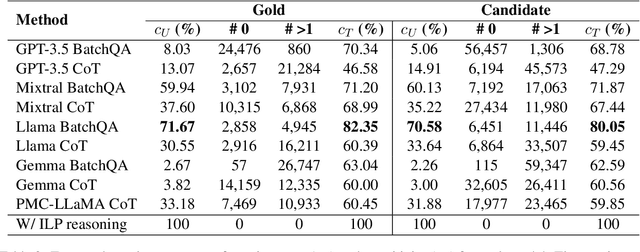
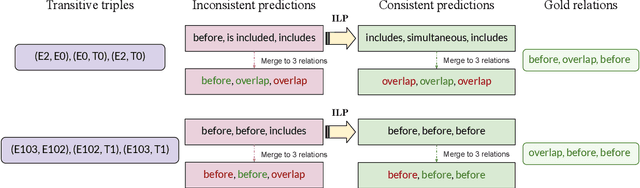
This paper presents the first study for temporal relation extraction in a zero-shot setting focusing on biomedical text. We employ two types of prompts and five LLMs (GPT-3.5, Mixtral, Llama 2, Gemma, and PMC-LLaMA) to obtain responses about the temporal relations between two events. Our experiments demonstrate that LLMs struggle in the zero-shot setting performing worse than fine-tuned specialized models in terms of F1 score, showing that this is a challenging task for LLMs. We further contribute a novel comprehensive temporal analysis by calculating consistency scores for each LLM. Our findings reveal that LLMs face challenges in providing responses consistent to the temporal properties of uniqueness and transitivity. Moreover, we study the relation between the temporal consistency of an LLM and its accuracy and whether the latter can be improved by solving temporal inconsistencies. Our analysis shows that even when temporal consistency is achieved, the predictions can remain inaccurate.
Counterfactual Reasoning with Knowledge Graph Embeddings
Mar 11, 2024Knowledge graph embeddings (KGEs) were originally developed to infer true but missing facts in incomplete knowledge repositories. In this paper, we link knowledge graph completion and counterfactual reasoning via our new task CFKGR. We model the original world state as a knowledge graph, hypothetical scenarios as edges added to the graph, and plausible changes to the graph as inferences from logical rules. We create corresponding benchmark datasets, which contain diverse hypothetical scenarios with plausible changes to the original knowledge graph and facts that should be retained. We develop COULDD, a general method for adapting existing knowledge graph embeddings given a hypothetical premise, and evaluate it on our benchmark. Our results indicate that KGEs learn patterns in the graph without explicit training. We further observe that KGEs adapted with COULDD solidly detect plausible counterfactual changes to the graph that follow these patterns. An evaluation on human-annotated data reveals that KGEs adapted with COULDD are mostly unable to recognize changes to the graph that do not follow learned inference rules. In contrast, ChatGPT mostly outperforms KGEs in detecting plausible changes to the graph but has poor knowledge retention. In summary, CFKGR connects two previously distinct areas, namely KG completion and counterfactual reasoning.
Text-Guided Image Clustering
Feb 05, 2024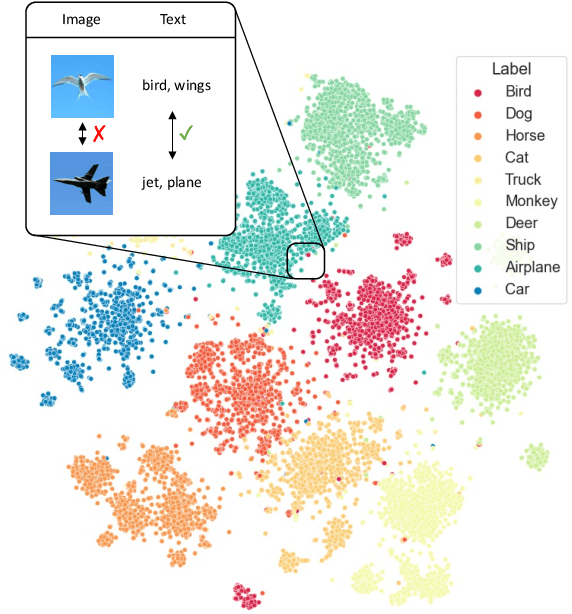

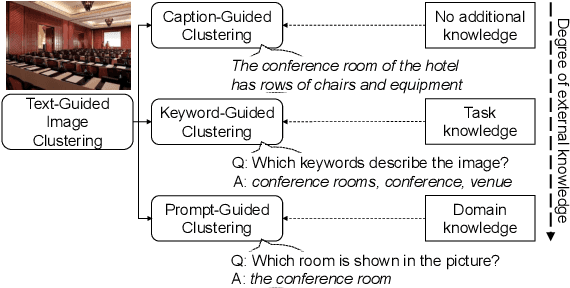
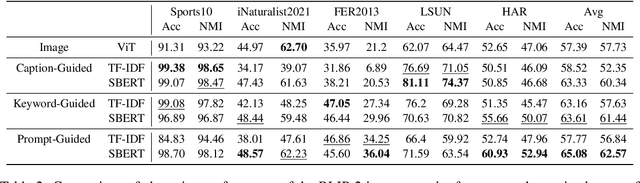
Image clustering divides a collection of images into meaningful groups, typically interpreted post-hoc via human-given annotations. Those are usually in the form of text, begging the question of using text as an abstraction for image clustering. Current image clustering methods, however, neglect the use of generated textual descriptions. We, therefore, propose Text-Guided Image Clustering, i.e., generating text using image captioning and visual question-answering (VQA) models and subsequently clustering the generated text. Further, we introduce a novel approach to inject task- or domain knowledge for clustering by prompting VQA models. Across eight diverse image clustering datasets, our results show that the obtained text representations often outperform image features. Additionally, we propose a counting-based cluster explainability method. Our evaluations show that the derived keyword-based explanations describe clusters better than the respective cluster accuracy suggests. Overall, this research challenges traditional approaches and paves the way for a paradigm shift in image clustering, using generated text.
Weaker Than You Think: A Critical Look atWeakly Supervised Learning
May 27, 2023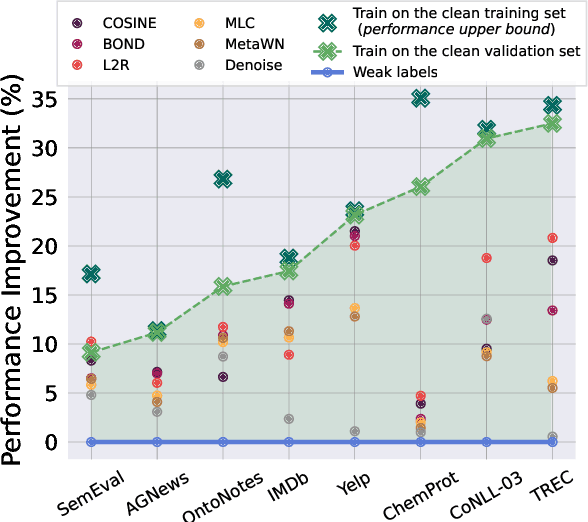



Weakly supervised learning is a popular approach for training machine learning models in low-resource settings. Instead of requesting high-quality yet costly human annotations, it allows training models with noisy annotations obtained from various weak sources. Recently, many sophisticated approaches have been proposed for robust training under label noise, reporting impressive results. In this paper, we revisit the setup of these approaches and find that the benefits brought by these approaches are significantly overestimated. Specifically, we find that the success of existing weakly supervised learning approaches heavily relies on the availability of clean validation samples which, as we show, can be leveraged much more efficiently by simply training on them. After using these clean labels in training, the advantages of using these sophisticated approaches are mostly wiped out. This remains true even when reducing the size of the available clean data to just five samples per class, making these approaches impractical. To understand the true value of weakly supervised learning, we thoroughly analyse diverse NLP datasets and tasks to ascertain when and why weakly supervised approaches work, and provide recommendations for future research.
SepLL: Separating Latent Class Labels from Weak Supervision Noise
Oct 25, 2022In the weakly supervised learning paradigm, labeling functions automatically assign heuristic, often noisy, labels to data samples. In this work, we provide a method for learning from weak labels by separating two types of complementary information associated with the labeling functions: information related to the target label and information specific to one labeling function only. Both types of information are reflected to different degrees by all labeled instances. In contrast to previous works that aimed at correcting or removing wrongly labeled instances, we learn a branched deep model that uses all data as-is, but splits the labeling function information in the latent space. Specifically, we propose the end-to-end model SepLL which extends a transformer classifier by introducing a latent space for labeling function specific and task-specific information. The learning signal is only given by the labeling functions matches, no pre-processing or label model is required for our method. Notably, the task prediction is made from the latent layer without any direct task signal. Experiments on Wrench text classification tasks show that our model is competitive with the state-of-the-art, and yields a new best average performance.
WeaNF: Weak Supervision with Normalizing Flows
May 02, 2022



A popular approach to decrease the need for costly manual annotation of large data sets is weak supervision, which introduces problems of noisy labels, coverage and bias. Methods for overcoming these problems have either relied on discriminative models, trained with cost functions specific to weak supervision, and more recently, generative models, trying to model the output of the automatic annotation process. In this work, we explore a novel direction of generative modeling for weak supervision: Instead of modeling the output of the annotation process (the labeling function matches), we generatively model the input-side data distributions (the feature space) covered by labeling functions. Specifically, we estimate a density for each weak labeling source, or labeling function, by using normalizing flows. An integral part of our method is the flow-based modeling of multiple simultaneously matching labeling functions, and therefore phenomena such as labeling function overlap and correlations are captured. We analyze the effectiveness and modeling capabilities on various commonly used weak supervision data sets, and show that weakly supervised normalizing flows compare favorably to standard weak supervision baselines.
Knodle: Modular Weakly Supervised Learning with PyTorch
May 10, 2021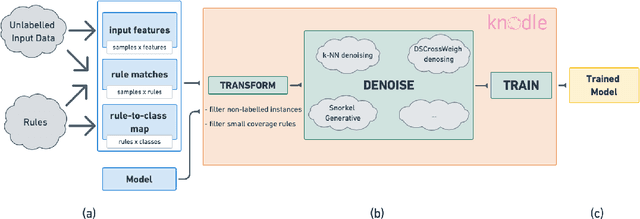

Strategies for improving the training and prediction quality of weakly supervised machine learning models vary in how much they are tailored to a specific task or integrated with a specific model architecture. In this work, we propose a software framework Knodle that treats weak data annotations, deep learning models, and methods for improving weakly supervised training as separate, modular components. The standardized interfaces between these independent parts account for data- and model-agnostic weak supervision method development, but still allow the training process to access fine-grained information such as data set characteristics, matches of heuristic rules, as well as elements of the deep learning model ultimately used for prediction. Hence, our framework can encompass a wide range of training methods for improving weak supervision, ranging from methods that only look at correlations of rules and output classes (independently of the machine learning model trained with the resulting labels), to those that harness the interplay of neural networks and weakly labeled data. We illustrate the benchmarking potential of the framework with a performance comparison of several reference implementations on a selection of datasets that are already available in Knodle.