 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysing zero-shot temporal relation extraction on clinical notes using temporal consistency
Jun 17, 2024
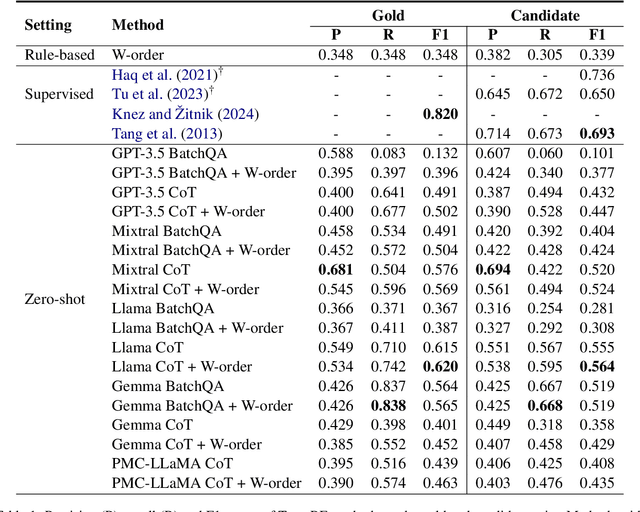
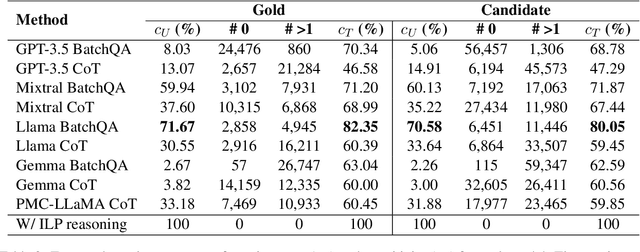
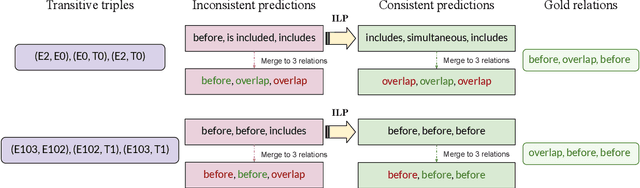
This paper presents the first study for temporal relation extraction in a zero-shot setting focusing on biomedical text. We employ two types of prompts and five LLMs (GPT-3.5, Mixtral, Llama 2, Gemma, and PMC-LLaMA) to obtain responses about the temporal relations between two events. Our experiments demonstrate that LLMs struggle in the zero-shot setting performing worse than fine-tuned specialized models in terms of F1 score, showing that this is a challenging task for LLMs. We further contribute a novel comprehensive temporal analysis by calculating consistency scores for each LLM. Our findings reveal that LLMs face challenges in providing responses consistent to the temporal properties of uniqueness and transitivity. Moreover, we study the relation between the temporal consistency of an LLM and its accuracy and whether the latter can be improved by solving temporal inconsistencies. Our analysis shows that even when temporal consistency is achieved, the predictions can remain inaccurate.
Exploring prompts to elicit memorization in masked language model-based named entity recognition
May 05, 2024



Training data memorization in language models impacts model capability (generalization) and safety (privacy risk). This paper focuses on analyzing prompts' impact on detecting the memorization of 6 masked language model-based named entity recognition models. Specifically, we employ a diverse set of 400 automatically generated prompts, and a pairwise dataset where each pair consists of one person's name from the training set and another name out of the set. A prompt completed with a person's name serves as input for getting the model's confidence in predicting this name. Finally, the prompt performance of detecting model memorization is quantified by the percentage of name pairs for which the model has higher confidence for the name from the training set. We show that the performance of different prompts varies by as much as 16 percentage points on the same model, and prompt engineering further increases the gap. Moreover, our experiments demonstrate that prompt performance is model-dependent but does generalize across different name sets. A comprehensive analysis indicates how prompt performance is influenced by prompt properties, contained tokens, and the model's self-attention weights on the prompt.
MemeGraphs: Linking Memes to Knowledge Graphs
May 28, 2023Memes are a popular form of communicating trends and ideas in social media and on the internet in general, combining the modalities of images and text. They can express humor and sarcasm but can also have offensive content. Analyzing and classifying memes automatically is challenging since their interpretation relies on the understanding of visual elements, language, and background knowledge. Thus, it is important to meaningfully represent these sources and the interaction between them in order to classify a meme as a whole. In this work, we propose to use scene graphs, that express images in terms of objects and their visual relations, and knowledge graphs as structured representations for meme classification with a Transformer-based architecture. We compare our approach with ImgBERT, a multimodal model that uses only learned (instead of structured) representations of the meme, and observe consistent improvements. We further provide a dataset with human graph annotations that we compare to automatically generated graphs and entity linking. Analysis shows that automatic methods link more entities than human annotators and that automatically generated graphs are better suited for hatefulness classification in memes.
SepLL: Separating Latent Class Labels from Weak Supervision Noise
Oct 25, 2022In the weakly supervised learning paradigm, labeling functions automatically assign heuristic, often noisy, labels to data samples. In this work, we provide a method for learning from weak labels by separating two types of complementary information associated with the labeling functions: information related to the target label and information specific to one labeling function only. Both types of information are reflected to different degrees by all labeled instances. In contrast to previous works that aimed at correcting or removing wrongly labeled instances, we learn a branched deep model that uses all data as-is, but splits the labeling function information in the latent space. Specifically, we propose the end-to-end model SepLL which extends a transformer classifier by introducing a latent space for labeling function specific and task-specific information. The learning signal is only given by the labeling functions matches, no pre-processing or label model is required for our method. Notably, the task prediction is made from the latent layer without any direct task signal. Experiments on Wrench text classification tasks show that our model is competitive with the state-of-the-art, and yields a new best average performance.
Diagnostic Captioning: A Survey
Jan 18, 2021



Diagnostic Captioning (DC) concerns the automatic generation of a diagnostic text from a set of medical images of a patient collected during an examination. DC can assist inexperienced physicians, reducing clinical errors. It can also help experienced physicians produce diagnostic reports faster. Following the advances of deep learning, especially in generic image captioning, DC has recently attracted more attention, leading to several systems and datasets. This article is an extensive overview of DC. It presents relevant datasets, evaluation measures, and up to date systems. It also highlights shortcomings that hinder DC's progress and proposes future directions.
RTEX: A novel methodology for Ranking, Tagging, and Explanatory diagnostic captioning of radiography exams
Jun 11, 2020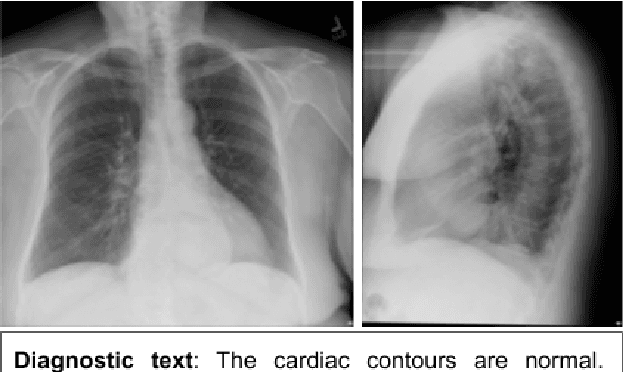
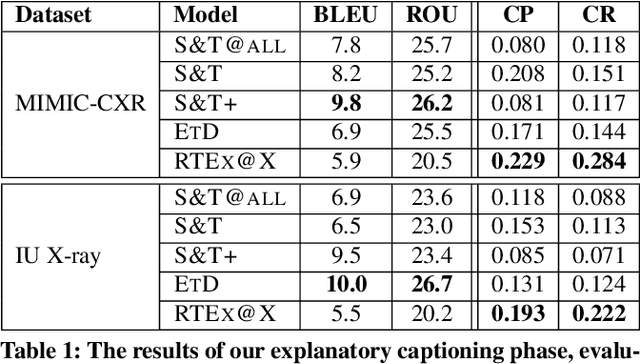

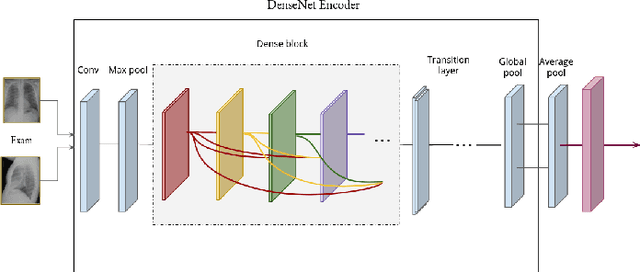
This paper introduces RTEx, a novel methodology for a) ranking radiography exams based on their probability to contain an abnormality, b) generating abnormality tags for abnormal exams, and c) providing a diagnostic explanation in natural language for each abnormal exam. The task of ranking radiography exams is an important first step for practitioners who want to identify and prioritize those radiography exams that are more likely to contain abnormalities, for example, to avoid mistakes due to tiredness or to manage heavy workload (e.g., during a pandemic). We used two publicly available datasets to assess our methodology and demonstrate that for the task of ranking it outperforms its competitors in terms of NDCG@k. For each abnormal radiography exam RTEx generates a set of abnormality tags alongside an explanatory diagnostic text to explain the tags and guide the medical expert. Our tagging component outperforms two strong competitor methods in terms of F1. Moreover, the diagnostic captioning component of RTEx, which exploits the already extracted tags to constrain the captioning process, outperforms all competitors with respect to clinical precision and recall.
A Survey on Biomedical Image Captioning
May 26, 2019
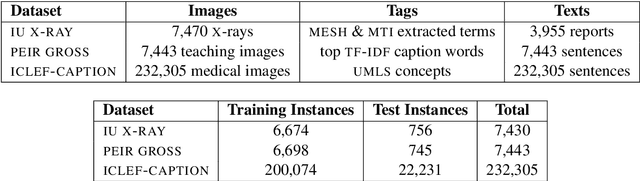
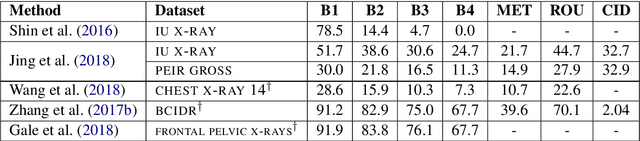
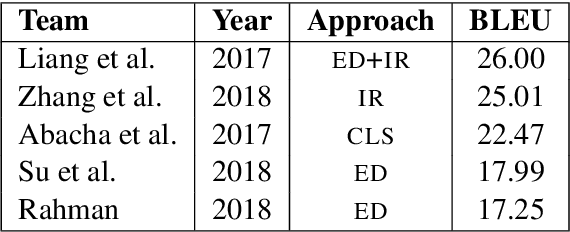
Image captioning applied to biomedical images can assist and accelerate the diagnosis process followed by clinicians. This article is the first survey of biomedical image captioning, discussing datasets, evaluation measures, and state of the art methods. Additionally, we suggest two baselines, a weak and a stronger one; the latter outperforms all current state of the art systems on one of the datasets.