 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransparent NLP: Using RAG and LLM Alignment for Privacy Q&A
Feb 10, 2025



The transparency principle of the General Data Protection Regulation (GDPR) requires data processing information to be clear, precise, and accessible. While language models show promise in this context, their probabilistic nature complicates truthfulness and comprehensibility. This paper examines state-of-the-art Retrieval Augmented Generation (RAG) systems enhanced with alignment techniques to fulfill GDPR obligations. We evaluate RAG systems incorporating an alignment module like Rewindable Auto-regressive Inference (RAIN) and our proposed multidimensional extension, MultiRAIN, using a Privacy Q&A dataset. Responses are optimized for preciseness and comprehensibility and are assessed through 21 metrics, including deterministic and large language model-based evaluations. Our results show that RAG systems with an alignment module outperform baseline RAG systems on most metrics, though none fully match human answers. Principal component analysis of the results reveals complex interactions between metrics, highlighting the need to refine metrics. This study provides a foundation for integrating advanced natural language processing systems into legal compliance frameworks.
A Comprehensive Survey on Legal Summarization: Challenges and Future Directions
Jan 29, 2025


This article provides a systematic up-to-date survey of automatic summarization techniques, datasets, models, and evaluation methods in the legal domain. Through specific source selection criteria, we thoroughly review over 120 papers spanning the modern `transformer' era of natural language processing (NLP), thus filling a gap in existing systematic surveys on the matter. We present existing research along several axes and discuss trends, challenges, and opportunities for future research.
AlbNews: A Corpus of Headlines for Topic Modeling in Albanian
Feb 06, 2024
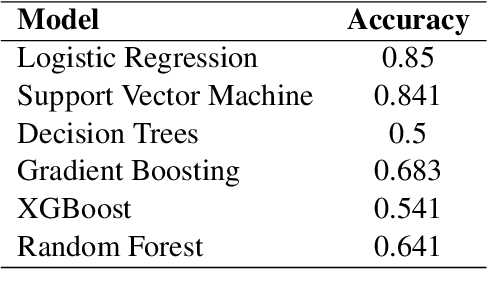
The scarcity of available text corpora for low-resource languages like Albanian is a serious hurdle for research in natural language processing tasks. This paper introduces AlbNews, a collection of 600 topically labeled news headlines and 2600 unlabeled ones in Albanian. The data can be freely used for conducting topic modeling research. We report the initial classification scores of some traditional machine learning classifiers trained with the AlbNews samples. These results show that basic models outrun the ensemble learning ones and can serve as a baseline for future experiments.
AlbNER: A Corpus for Named Entity Recognition in Albanian
Sep 15, 2023Scarcity of resources such as annotated text corpora for under-resourced languages like Albanian is a serious impediment in computational linguistics and natural language processing research. This paper presents AlbNER, a corpus of 900 sentences with labeled named entities, collected from Albanian Wikipedia articles. Preliminary results with BERT and RoBERTa variants fine-tuned and tested with AlbNER data indicate that model size has slight impact on NER performance, whereas language transfer has a significant one. AlbNER corpus and these obtained results should serve as baselines for future experiments.
AlbMoRe: A Corpus of Movie Reviews for Sentiment Analysis in Albanian
Jun 14, 2023


Lack of available resources such as text corpora for low-resource languages seriously hinders research on natural language processing and computational linguistics. This paper presents AlbMoRe, a corpus of 800 sentiment annotated movie reviews in Albanian. Each text is labeled as positive or negative and can be used for sentiment analysis research. Preliminary results based on traditional machine learning classifiers trained with the AlbMoRe samples are also reported. They can serve as comparison baselines for future research experiments.
MemeGraphs: Linking Memes to Knowledge Graphs
May 28, 2023Memes are a popular form of communicating trends and ideas in social media and on the internet in general, combining the modalities of images and text. They can express humor and sarcasm but can also have offensive content. Analyzing and classifying memes automatically is challenging since their interpretation relies on the understanding of visual elements, language, and background knowledge. Thus, it is important to meaningfully represent these sources and the interaction between them in order to classify a meme as a whole. In this work, we propose to use scene graphs, that express images in terms of objects and their visual relations, and knowledge graphs as structured representations for meme classification with a Transformer-based architecture. We compare our approach with ImgBERT, a multimodal model that uses only learned (instead of structured) representations of the meme, and observe consistent improvements. We further provide a dataset with human graph annotations that we compare to automatically generated graphs and entity linking. Analysis shows that automatic methods link more entities than human annotators and that automatically generated graphs are better suited for hatefulness classification in memes.
Batch Layer Normalization, A new normalization layer for CNNs and RNN
Sep 19, 2022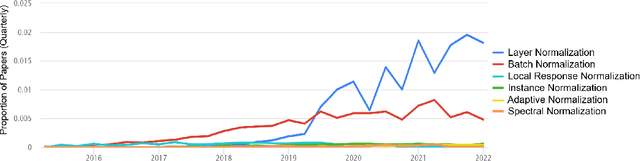
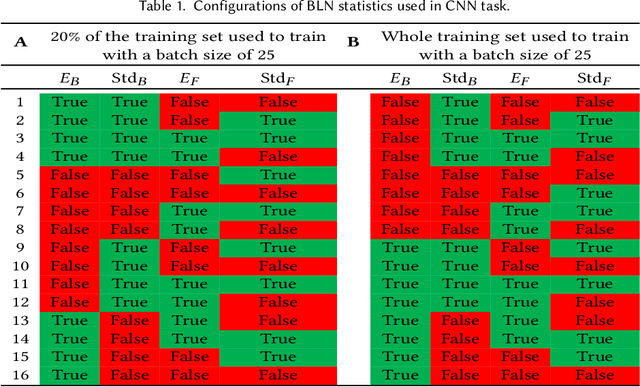
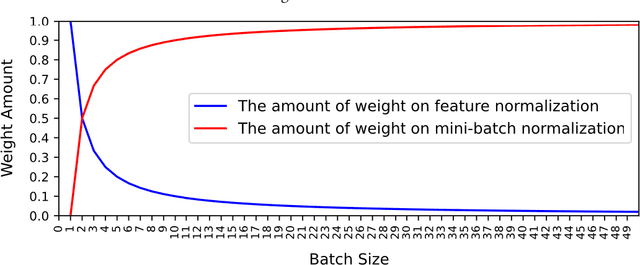
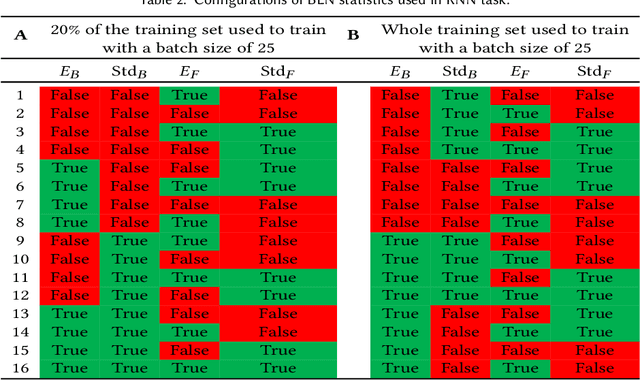
This study introduces a new normalization layer termed Batch Layer Normalization (BLN) to reduce the problem of internal covariate shift in deep neural network layers. As a combined version of batch and layer normalization, BLN adaptively puts appropriate weight on mini-batch and feature normalization based on the inverse size of mini-batches to normalize the input to a layer during the learning process. It also performs the exact computation with a minor change at inference times, using either mini-batch statistics or population statistics. The decision process to either use statistics of mini-batch or population gives BLN the ability to play a comprehensive role in the hyper-parameter optimization process of models. The key advantage of BLN is the support of the theoretical analysis of being independent of the input data, and its statistical configuration heavily depends on the task performed, the amount of training data, and the size of batches. Test results indicate the application potential of BLN and its faster convergence than batch normalization and layer normalization in both Convolutional and Recurrent Neural Networks. The code of the experiments is publicly available online (https://github.com/A2Amir/Batch-Layer-Normalization).
hmBERT: Historical Multilingual Language Models for Named Entity Recognition
May 31, 2022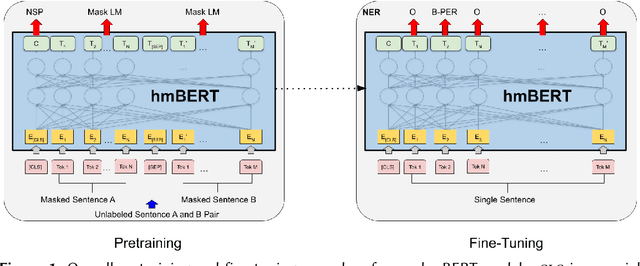



Compared to standard Named Entity Recognition (NER), identifying persons, locations, and organizations in historical texts forms a big challenge. To obtain machine-readable corpora, the historical text is usually scanned and optical character recognition (OCR) needs to be performed. As a result, the historical corpora contain errors. Also, entities like location or organization can change over time, which poses another challenge. Overall historical texts come with several peculiarities that differ greatly from modern texts and large labeled corpora for training a neural tagger are hardly available for this domain. In this work, we tackle NER for historical German, English, French, Swedish, and Finnish by training large historical language models. We circumvent the need for labeled data by using unlabeled data for pretraining a language model. hmBERT, a historical multilingual BERT-based language model is proposed, with different sizes of it being publicly released. Furthermore, we evaluate the capability of hmBERT by solving downstream NER as part of this year's HIPE-2022 shared task and provide detailed analysis and insights. For the Multilingual Classical Commentary coarse-grained NER challenge, our tagger HISTeria outperforms the other teams' models for two out of three languages.
Topic Segmentation of Research Article Collections
May 18, 2022
Collections of research article data harvested from the web have become common recently since they are important resources for experimenting on tasks such as named entity recognition, text summarization, or keyword generation. In fact, certain types of experiments require collections that are both large and topically structured, with records assigned to separate research disciplines. Unfortunately, the current collections of publicly available research articles are either small or heterogeneous and unstructured. In this work, we perform topic segmentation of a paper data collection that we crawled and produce a multitopic dataset of roughly seven million paper data records. We construct a taxonomy of topics extracted from the data records and then annotate each document with its corresponding topic from that taxonomy. As a result, it is possible to use this newly proposed dataset in two modalities: as a heterogeneous collection of documents from various disciplines or as a set of homogeneous collections, each from a single research topic.
Focused Contrastive Training for Test-based Constituency Analysis
Sep 30, 2021

We propose a scheme for self-training of grammaticality models for constituency analysis based on linguistic tests. A pre-trained language model is fine-tuned by contrastive estimation of grammatical sentences from a corpus, and ungrammatical sentences that were perturbed by a syntactic test, a transformation that is motivated by constituency theory. We show that consistent gains can be achieved if only certain positive instances are chosen for training, depending on whether they could be the result of a test transformation. This way, the positives, and negatives exhibit similar characteristics, which makes the objective more challenging for the language model, and also allows for additional markup that indicates the position of the test application within the sentence.