 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynth$^2$: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
Mar 12, 2024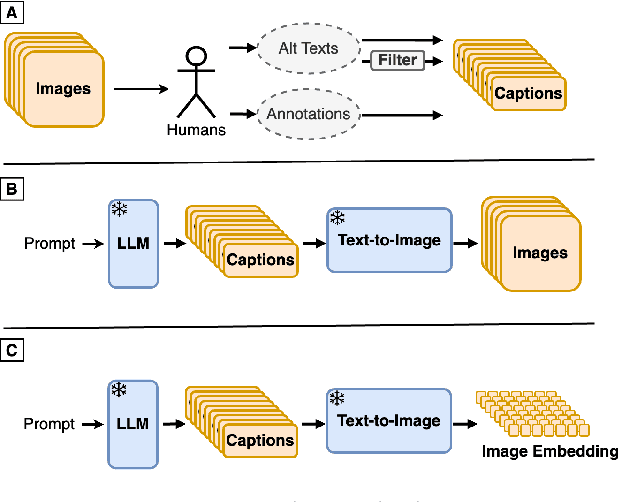
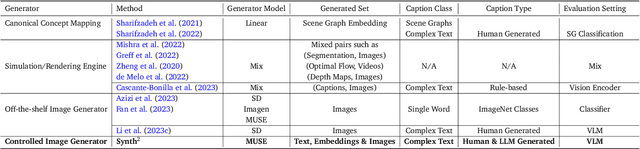


The creation of high-quality human-labeled image-caption datasets presents a significant bottleneck in the development of Visual-Language Models (VLMs). We propose a novel approach that leverages the strengths of Large Language Models (LLMs) and image generation models to create synthetic image-text pairs for efficient and effective VLM training. Our method employs pretraining a text-to-image model to synthesize image embeddings starting from captions generated by an LLM. These synthetic pairs are then used to train a VLM. Extensive experiments demonstrate that the VLM trained with synthetic data exhibits comparable performance on image captioning, while requiring a fraction of the data used by models trained solely on human-annotated data. In particular, we outperform the baseline by 17% through augmentation with a synthetic dataset. Furthermore, we show that synthesizing in the image embedding space is 25% faster than in the pixel space. This research introduces a promising technique for generating large-scale, customizable image datasets, leading to enhanced VLM performance and wider applicability across various domains, all with improved data efficiency and resource utilization.
PQA: Zero-shot Protein Question Answering for Free-form Scientific Enquiry with Large Language Models
Feb 21, 2024



We introduce the novel task of zero-shot Protein Question Answering (PQA) for free-form scientific enquiry. Given a previously unseen protein sequence and a natural language question, the task is to deliver a scientifically accurate answer. This task not only supports future biological research, but could also provide a test bed for assessing the scientific precision of large language models (LLMs). We contribute the first specialized dataset for PQA model training, containing 257K protein sequences annotated with 1.97M scientific question-answer pairs. Additionally, we propose and study several novel biologically relevant benchmarks for scientific PQA. Employing two robust multi-modal architectures, we establish an initial state-of-the-art performance for PQA and reveal key performance factors through ablation studies. Our comprehensive PQA framework, named Pika, including dataset, code, model checkpoints, and a user-friendly demo, is openly accessible on github.com/EMCarrami/Pika, promoting wider research and application in the field.
MemeGraphs: Linking Memes to Knowledge Graphs
May 28, 2023Memes are a popular form of communicating trends and ideas in social media and on the internet in general, combining the modalities of images and text. They can express humor and sarcasm but can also have offensive content. Analyzing and classifying memes automatically is challenging since their interpretation relies on the understanding of visual elements, language, and background knowledge. Thus, it is important to meaningfully represent these sources and the interaction between them in order to classify a meme as a whole. In this work, we propose to use scene graphs, that express images in terms of objects and their visual relations, and knowledge graphs as structured representations for meme classification with a Transformer-based architecture. We compare our approach with ImgBERT, a multimodal model that uses only learned (instead of structured) representations of the meme, and observe consistent improvements. We further provide a dataset with human graph annotations that we compare to automatically generated graphs and entity linking. Analysis shows that automatic methods link more entities than human annotators and that automatically generated graphs are better suited for hatefulness classification in memes.
Prior-RadGraphFormer: A Prior-Knowledge-Enhanced Transformer for Generating Radiology Graphs from X-Rays
Mar 27, 2023



The extraction of structured clinical information from free-text radiology reports in the form of radiology graphs has been demonstrated to be a valuable approach for evaluating the clinical correctness of report-generation methods. However, the direct generation of radiology graphs from chest X-ray (CXR) images has not been attempted. To address this gap, we propose a novel approach called Prior-RadGraphFormer that utilizes a transformer model with prior knowledge in the form of a probabilistic knowledge graph (PKG) to generate radiology graphs directly from CXR images. The PKG models the statistical relationship between radiology entities, including anatomical structures and medical observations. This additional contextual information enhances the accuracy of entity and relation extraction. The generated radiology graphs can be applied to various downstream tasks, such as free-text or structured reports generation and multi-label classification of pathologies. Our approach represents a promising method for generating radiology graphs directly from CXR images, and has significant potential for improving medical image analysis and clinical decision-making.
Ultra-High-Resolution Detector Simulation with Intra-Event Aware GAN and Self-Supervised Relational Reasoning
Mar 07, 2023Simulating high-resolution detector responses is a storage-costly and computationally intensive process that has long been challenging in particle physics. Despite the ability of deep generative models to make this process more cost-efficient, ultra-high-resolution detector simulation still proves to be difficult as it contains correlated and fine-grained mutual information within an event. To overcome these limitations, we propose Intra-Event Aware GAN (IEA-GAN), a novel fusion of Self-Supervised Learning and Generative Adversarial Networks. IEA-GAN presents a Relational Reasoning Module that approximates the concept of an ''event'' in detector simulation, allowing for the generation of correlated layer-dependent contextualized images for high-resolution detector responses with a proper relational inductive bias. IEA-GAN also introduces a new intra-event aware loss and a Uniformity loss, resulting in significant enhancements to image fidelity and diversity. We demonstrate IEA-GAN's application in generating sensor-dependent images for the high-granularity Pixel Vertex Detector (PXD), with more than 7.5M information channels and a non-trivial geometry, at the Belle II Experiment. Applications of this work include controllable simulation-based inference and event generation, high-granularity detector simulation such as at the HL-LHC (High Luminosity LHC), and fine-grained density estimation and sampling. To the best of our knowledge, IEA-GAN is the first algorithm for faithful ultra-high-resolution detector simulation with event-based reasoning.
Do DALL-E and Flamingo Understand Each Other?
Dec 23, 2022



A major goal of multimodal research is to improve machine understanding of images and text. Tasks include image captioning, text-to-image generation, and vision-language representation learning. So far, research has focused on the relationships between images and text. For example, captioning models attempt to understand the semantics of images which are then transformed into text. An important question is: which annotation reflects best a deep understanding of image content? Similarly, given a text, what is the best image that can present the semantics of the text? In this work, we argue that the best text or caption for a given image is the text which would generate the image which is the most similar to that image. Likewise, the best image for a given text is the image that results in the caption which is best aligned with the original text. To this end, we propose a unified framework that includes both a text-to-image generative model and an image-to-text generative model. Extensive experiments validate our approach.
InstanceFormer: An Online Video Instance Segmentation Framework
Aug 22, 2022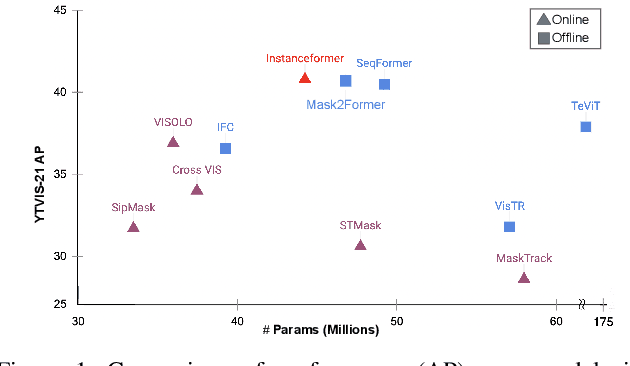
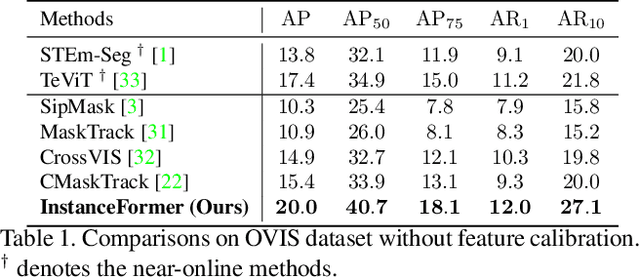
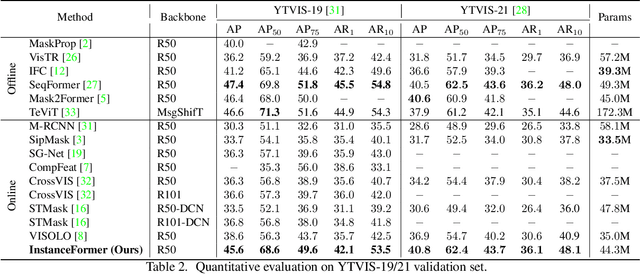
Recent transformer-based offline video instance segmentation (VIS) approaches achieve encouraging results and significantly outperform online approaches. However, their reliance on the whole video and the immense computational complexity caused by full Spatio-temporal attention limit them in real-life applications such as processing lengthy videos. In this paper, we propose a single-stage transformer-based efficient online VIS framework named InstanceFormer, which is especially suitable for long and challenging videos. We propose three novel components to model short-term and long-term dependency and temporal coherence. First, we propagate the representation, location, and semantic information of prior instances to model short-term changes. Second, we propose a novel memory cross-attention in the decoder, which allows the network to look into earlier instances within a certain temporal window. Finally, we employ a temporal contrastive loss to impose coherence in the representation of an instance across all frames. Memory attention and temporal coherence are particularly beneficial to long-range dependency modeling, including challenging scenarios like occlusion. The proposed InstanceFormer outperforms previous online benchmark methods by a large margin across multiple datasets. Most importantly, InstanceFormer surpasses offline approaches for challenging and long datasets such as YouTube-VIS-2021 and OVIS. Code is available at https://github.com/rajatkoner08/InstanceFormer.
Flamingo: a Visual Language Model for Few-Shot Learning
Apr 29, 2022
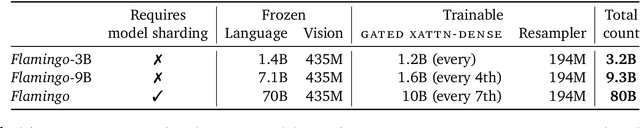
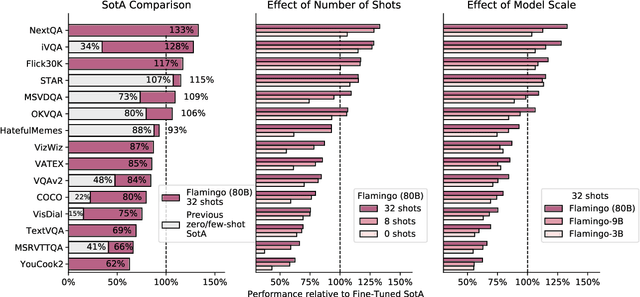
Building models that can be rapidly adapted to numerous tasks using only a handful of annotated examples is an open challenge for multimodal machine learning research. We introduce Flamingo, a family of Visual Language Models (VLM) with this ability. Flamingo models include key architectural innovations to: (i) bridge powerful pretrained vision-only and language-only models, (ii) handle sequences of arbitrarily interleaved visual and textual data, and (iii) seamlessly ingest images or videos as inputs. Thanks to their flexibility, Flamingo models can be trained on large-scale multimodal web corpora containing arbitrarily interleaved text and images, which is key to endow them with in-context few-shot learning capabilities. We perform a thorough evaluation of the proposed Flamingo models, exploring and measuring their ability to rapidly adapt to a variety of image and video understanding benchmarks. These include open-ended tasks such as visual question-answering, where the model is prompted with a question which it has to answer, captioning tasks, which evaluate the ability to describe a scene or an event, and close-ended tasks such as multiple choice visual question-answering. For tasks lying anywhere on this spectrum, we demonstrate that a single Flamingo model can achieve a new state of the art for few-shot learning, simply by prompting the model with task-specific examples. On many of these benchmarks, Flamingo actually surpasses the performance of models that are fine-tuned on thousands of times more task-specific data.
Relationformer: A Unified Framework for Image-to-Graph Generation
Mar 19, 2022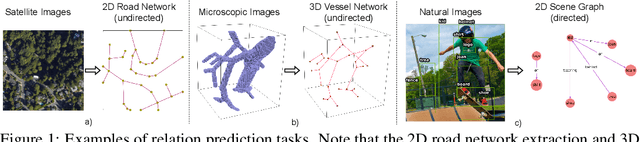

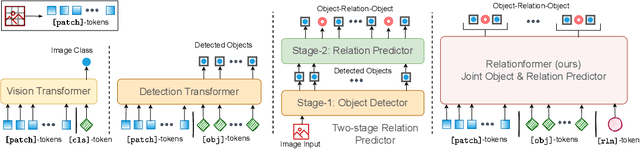
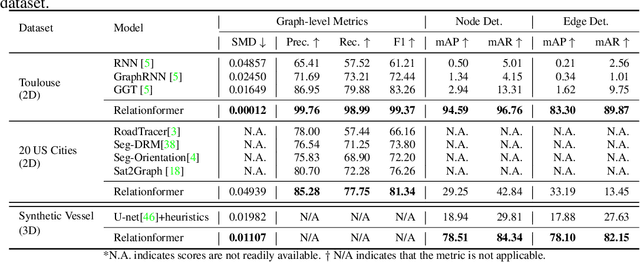
A comprehensive representation of an image requires understanding objects and their mutual relationship, especially in image-to-graph generation, e.g., road network extraction, blood-vessel network extraction, or scene graph generation. Traditionally, image-to-graph generation is addressed with a two-stage approach consisting of object detection followed by a separate relation prediction, which prevents simultaneous object-relation interaction. This work proposes a unified one-stage transformer-based framework, namely Relationformer, that jointly predicts objects and their relations. We leverage direct set-based object prediction and incorporate the interaction among the objects to learn an object-relation representation jointly. In addition to existing [obj]-tokens, we propose a novel learnable token, namely [rln]-token. Together with [obj]-tokens, [rln]-token exploits local and global semantic reasoning in an image through a series of mutual associations. In combination with the pair-wise [obj]-token, the [rln]-token contributes to a computationally efficient relation prediction. We achieve state-of-the-art performance on multiple, diverse and multi-domain datasets that demonstrate our approach's effectiveness and generalizability.
The Tensor Brain: A Unified Theory of Perception, Memory and Semantic Decoding
Oct 06, 2021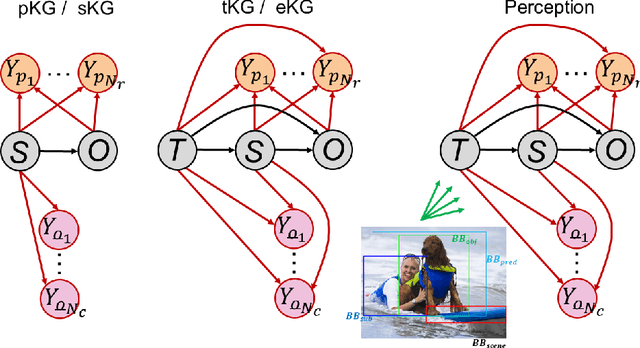

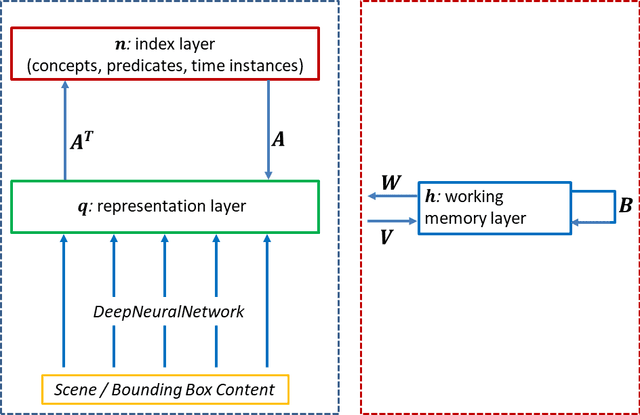
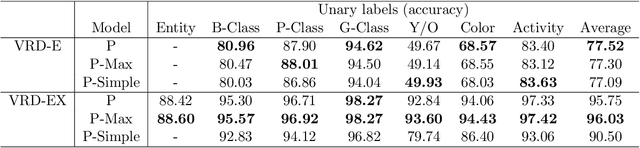
We present a unified computational theory of perception and memory. In our model, perception, episodic memory, and semantic memory are realized by different functional and operational modes of the oscillating interactions between an index layer and a representation layer in a bilayer tensor network (BTN). The memoryless semantic {representation layer} broadcasts information. In cognitive neuroscience, it would be the "mental canvas", or the "global workspace" and reflects the cognitive brain state. The symbolic {index layer} represents concepts and past episodes, whose semantic embeddings are implemented in the connection weights between both layers. In addition, we propose a {working memory layer} as a processing center and information buffer. Episodic and semantic memory realize memory-based reasoning, i.e., the recall of relevant past information to enrich perception, and are personalized to an agent's current state, as well as to an agent's unique memories. Episodic memory stores and retrieves past observations and provides provenance and context. Recent episodic memory enriches perception by the retrieval of perceptual experiences, which provide the agent with a sense about the here and now: to understand its own state, and the world's semantic state in general, the agent needs to know what happened recently, in recent scenes, and on recently perceived entities. Remote episodic memory retrieves relevant past experiences, contributes to our conscious self, and, together with semantic memory, to a large degree defines who we are as individuals.