 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRule-based Key-Point Extraction for MR-Guided Biomechanical Digital Twins of the Spine
Aug 20, 2025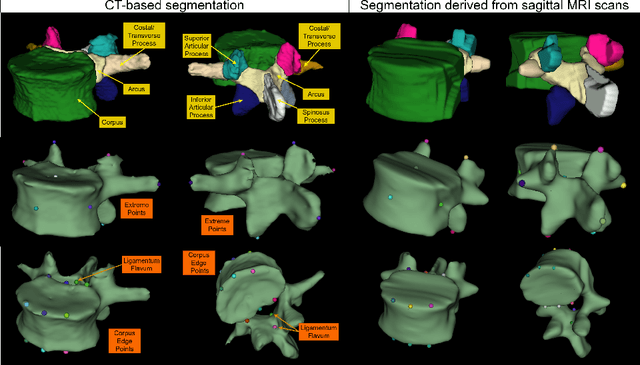

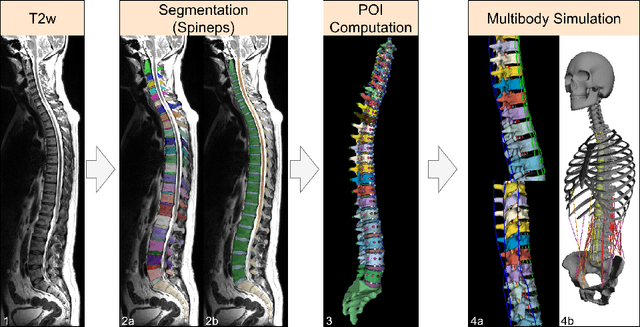

Digital twins offer a powerful framework for subject-specific simulation and clinical decision support, yet their development often hinges on accurate, individualized anatomical modeling. In this work, we present a rule-based approach for subpixel-accurate key-point extraction from MRI, adapted from prior CT-based methods. Our approach incorporates robust image alignment and vertebra-specific orientation estimation to generate anatomically meaningful landmarks that serve as boundary conditions and force application points, like muscle and ligament insertions in biomechanical models. These models enable the simulation of spinal mechanics considering the subject's individual anatomy, and thus support the development of tailored approaches in clinical diagnostics and treatment planning. By leveraging MR imaging, our method is radiation-free and well-suited for large-scale studies and use in underrepresented populations. This work contributes to the digital twin ecosystem by bridging the gap between precise medical image analysis with biomechanical simulation, and aligns with key themes in personalized modeling for healthcare.
Automated Thoracolumbar Stump Rib Detection and Analysis in a Large CT Cohort
May 08, 2025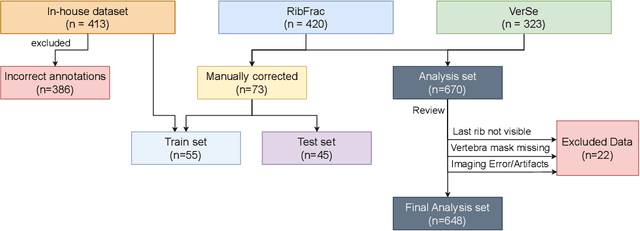

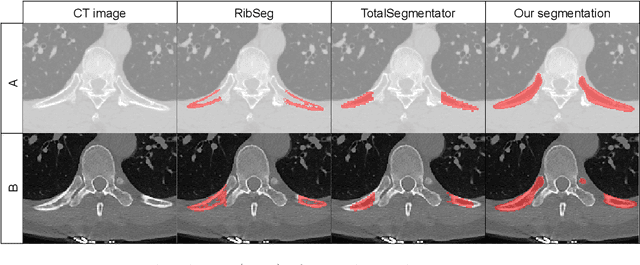

Thoracolumbar stump ribs are one of the essential indicators of thoracolumbar transitional vertebrae or enumeration anomalies. While some studies manually assess these anomalies and describe the ribs qualitatively, this study aims to automate thoracolumbar stump rib detection and analyze their morphology quantitatively. To this end, we train a high-resolution deep-learning model for rib segmentation and show significant improvements compared to existing models (Dice score 0.997 vs. 0.779, p-value < 0.01). In addition, we use an iterative algorithm and piece-wise linear interpolation to assess the length of the ribs, showing a success rate of 98.2%. When analyzing morphological features, we show that stump ribs articulate more posteriorly at the vertebrae (-19.2 +- 3.8 vs -13.8 +- 2.5, p-value < 0.01), are thinner (260.6 +- 103.4 vs. 563.6 +- 127.1, p-value < 0.01), and are oriented more downwards and sideways within the first centimeters in contrast to full-length ribs. We show that with partially visible ribs, these features can achieve an F1-score of 0.84 in differentiating stump ribs from regular ones. We publish the model weights and masks for public use.
MAGO-SP: Detection and Correction of Water-Fat Swaps in Magnitude-Only VIBE MRI
Feb 20, 2025
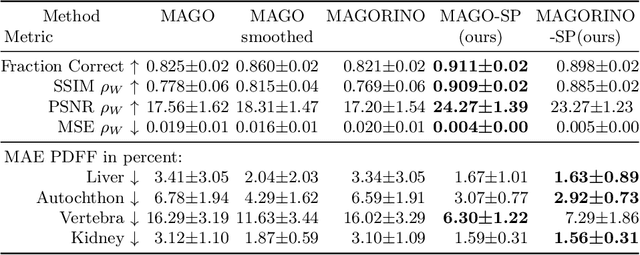
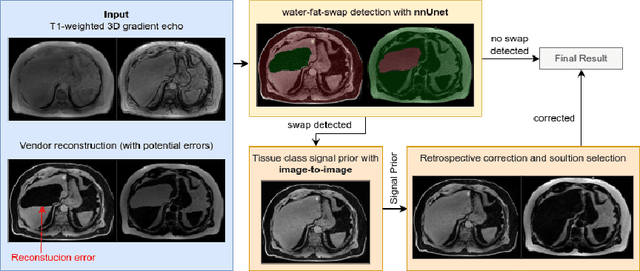

Volume Interpolated Breath-Hold Examination (VIBE) MRI generates images suitable for water and fat signal composition estimation. While the two-point VIBE provides water-fat-separated images, the six-point VIBE allows estimation of the effective transversal relaxation rate R2* and the proton density fat fraction (PDFF), which are imaging markers for health and disease. Ambiguity during signal reconstruction can lead to water-fat swaps. This shortcoming challenges the application of VIBE-MRI for automated PDFF analyses of large-scale clinical data and of population studies. This study develops an automated pipeline to detect and correct water-fat swaps in non-contrast-enhanced VIBE images. Our three-step pipeline begins with training a segmentation network to classify volumes as "fat-like" or "water-like," using synthetic water-fat swaps generated by merging fat and water volumes with Perlin noise. Next, a denoising diffusion image-to-image network predicts water volumes as signal priors for correction. Finally, we integrate this prior into a physics-constrained model to recover accurate water and fat signals. Our approach achieves a < 1% error rate in water-fat swap detection for a 6-point VIBE. Notably, swaps disproportionately affect individuals in the Underweight and Class 3 Obesity BMI categories. Our correction algorithm ensures accurate solution selection in chemical phase MRIs, enabling reliable PDFF estimation. This forms a solid technical foundation for automated large-scale population imaging analysis.
Surface Normal Estimation with Transformers
Jan 11, 2024We propose the use of a Transformer to accurately predict normals from point clouds with noise and density variations. Previous learning-based methods utilize PointNet variants to explicitly extract multi-scale features at different input scales, then focus on a surface fitting method by which local point cloud neighborhoods are fitted to a geometric surface approximated by either a polynomial function or a multi-layer perceptron (MLP). However, fitting surfaces to fixed-order polynomial functions can suffer from overfitting or underfitting, and learning MLP-represented hyper-surfaces requires pre-generated per-point weights. To avoid these limitations, we first unify the design choices in previous works and then propose a simplified Transformer-based model to extract richer and more robust geometric features for the surface normal estimation task. Through extensive experiments, we demonstrate that our Transformer-based method achieves state-of-the-art performance on both the synthetic shape dataset PCPNet, and the real-world indoor scene dataset SceneNN, exhibiting more noise-resilient behavior and significantly faster inference. Most importantly, we demonstrate that the sophisticated hand-designed modules in existing works are not necessary to excel at the task of surface normal estimation.
A Domain-specific Perceptual Metric via Contrastive Self-supervised Representation: Applications on Natural and Medical Images
Dec 03, 2022



Quantifying the perceptual similarity of two images is a long-standing problem in low-level computer vision. The natural image domain commonly relies on supervised learning, e.g., a pre-trained VGG, to obtain a latent representation. However, due to domain shift, pre-trained models from the natural image domain might not apply to other image domains, such as medical imaging. Notably, in medical imaging, evaluating the perceptual similarity is exclusively performed by specialists trained extensively in diverse medical fields. Thus, medical imaging remains devoid of task-specific, objective perceptual measures. This work answers the question: Is it necessary to rely on supervised learning to obtain an effective representation that could measure perceptual similarity, or is self-supervision sufficient? To understand whether recent contrastive self-supervised representation (CSR) may come to the rescue, we start with natural images and systematically evaluate CSR as a metric across numerous contemporary architectures and tasks and compare them with existing methods. We find that in the natural image domain, CSR behaves on par with the supervised one on several perceptual tests as a metric, and in the medical domain, CSR better quantifies perceptual similarity concerning the experts' ratings. We also demonstrate that CSR can significantly improve image quality in two image synthesis tasks. Finally, our extensive results suggest that perceptuality is an emergent property of CSR, which can be adapted to many image domains without requiring annotations.
Unsupervised Anomaly Localization with Structural Feature-Autoencoders
Aug 23, 2022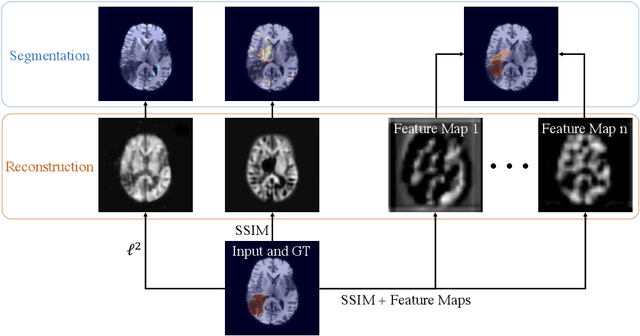
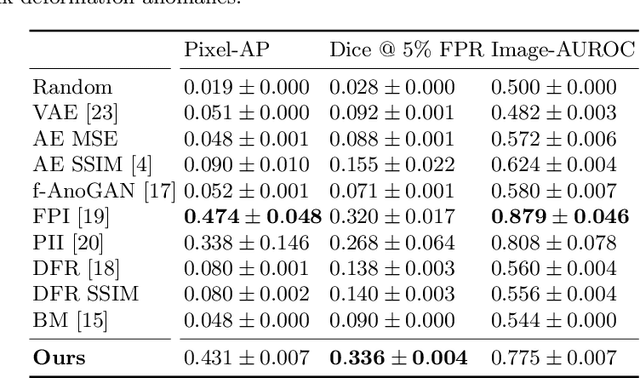
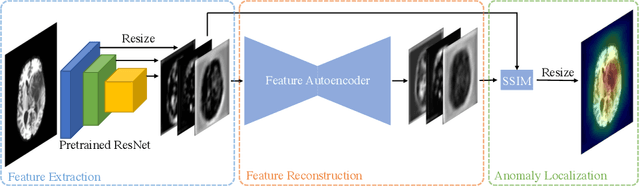
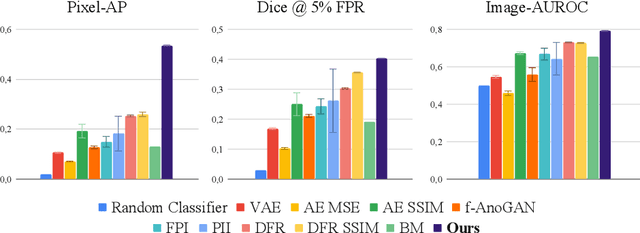
Unsupervised Anomaly Detection has become a popular method to detect pathologies in medical images as it does not require supervision or labels for training. Most commonly, the anomaly detection model generates a "normal" version of an input image, and the pixel-wise $l^p$-difference of the two is used to localize anomalies. However, large residuals often occur due to imperfect reconstruction of the complex anatomical structures present in most medical images. This method also fails to detect anomalies that are not characterized by large intensity differences to the surrounding tissue. We propose to tackle this problem using a feature-mapping function that transforms the input intensity images into a space with multiple channels where anomalies can be detected along different discriminative feature maps extracted from the original image. We then train an Autoencoder model in this space using structural similarity loss that does not only consider differences in intensity but also in contrast and structure. Our method significantly increases performance on two medical data sets for brain MRI. Code and experiments are available at https://github.com/FeliMe/feature-autoencoder
Deep Quality Estimation: Creating Surrogate Models for Human Quality Ratings
May 17, 2022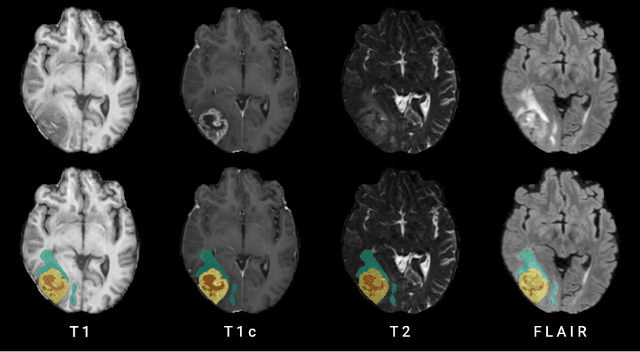
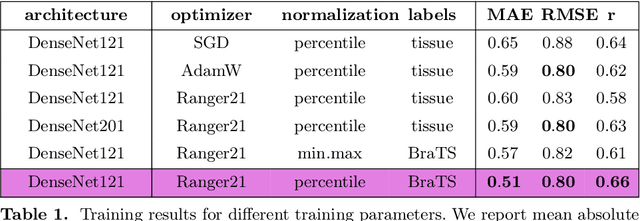
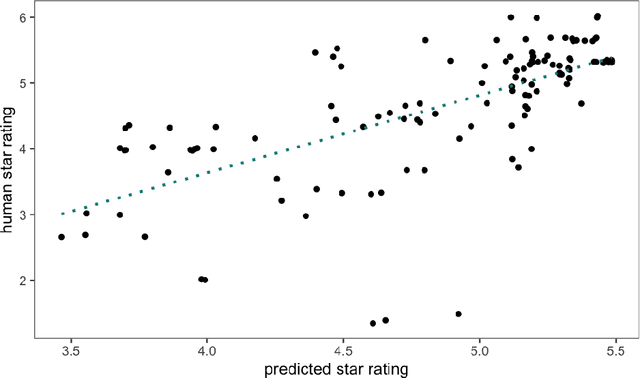
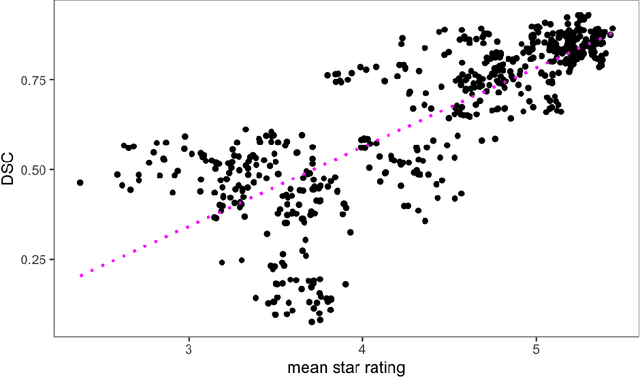
Human ratings are abstract representations of segmentation quality. To approximate human quality ratings on scarce expert data, we train surrogate quality estimation models. We evaluate on a complex multi-class segmentation problem, specifically glioma segmentation following the BraTS annotation protocol. The training data features quality ratings from 15 expert neuroradiologists on a scale ranging from 1 to 6 stars for various computer-generated and manual 3D annotations. Even though the networks operate on 2D images and with scarce training data, we can approximate segmentation quality within a margin of error comparable to human intra-rater reliability. Segmentation quality prediction has broad applications. While an understanding of segmentation quality is imperative for successful clinical translation of automatic segmentation quality algorithms, it can play an essential role in training new segmentation models. Due to the split-second inference times, it can be directly applied within a loss function or as a fully-automatic dataset curation mechanism in a federated learning setting.
Relationformer: A Unified Framework for Image-to-Graph Generation
Mar 19, 2022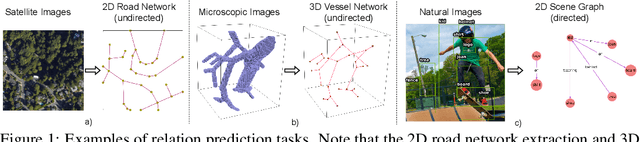

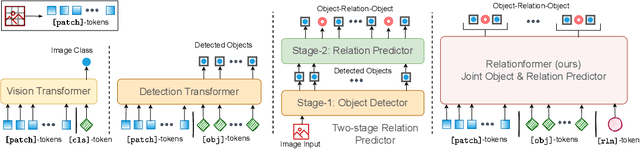
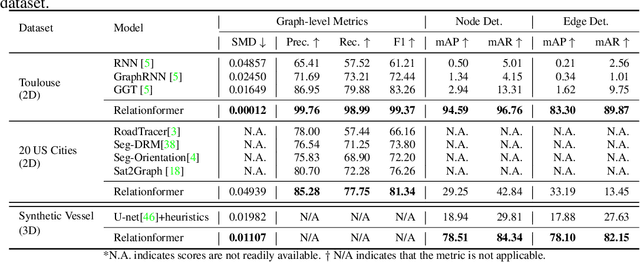
A comprehensive representation of an image requires understanding objects and their mutual relationship, especially in image-to-graph generation, e.g., road network extraction, blood-vessel network extraction, or scene graph generation. Traditionally, image-to-graph generation is addressed with a two-stage approach consisting of object detection followed by a separate relation prediction, which prevents simultaneous object-relation interaction. This work proposes a unified one-stage transformer-based framework, namely Relationformer, that jointly predicts objects and their relations. We leverage direct set-based object prediction and incorporate the interaction among the objects to learn an object-relation representation jointly. In addition to existing [obj]-tokens, we propose a novel learnable token, namely [rln]-token. Together with [obj]-tokens, [rln]-token exploits local and global semantic reasoning in an image through a series of mutual associations. In combination with the pair-wise [obj]-token, the [rln]-token contributes to a computationally efficient relation prediction. We achieve state-of-the-art performance on multiple, diverse and multi-domain datasets that demonstrate our approach's effectiveness and generalizability.
Learn-Morph-Infer: a new way of solving the inverse problem for brain tumor modeling
Nov 07, 2021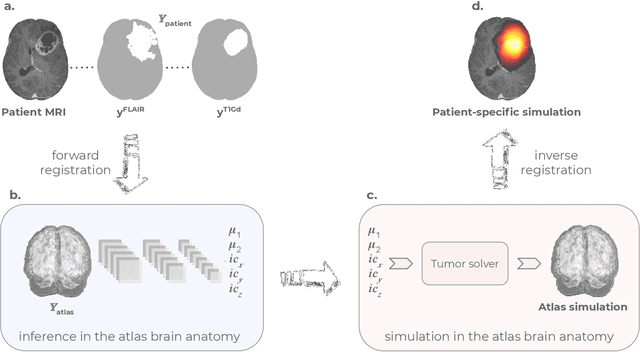
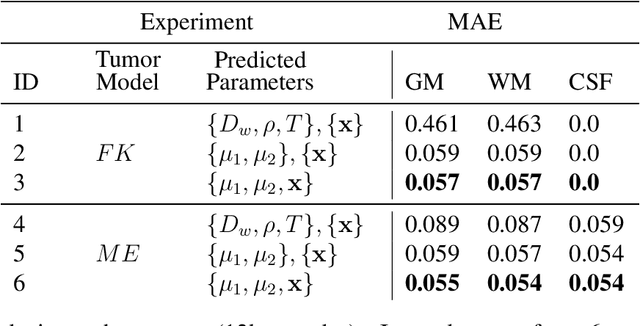
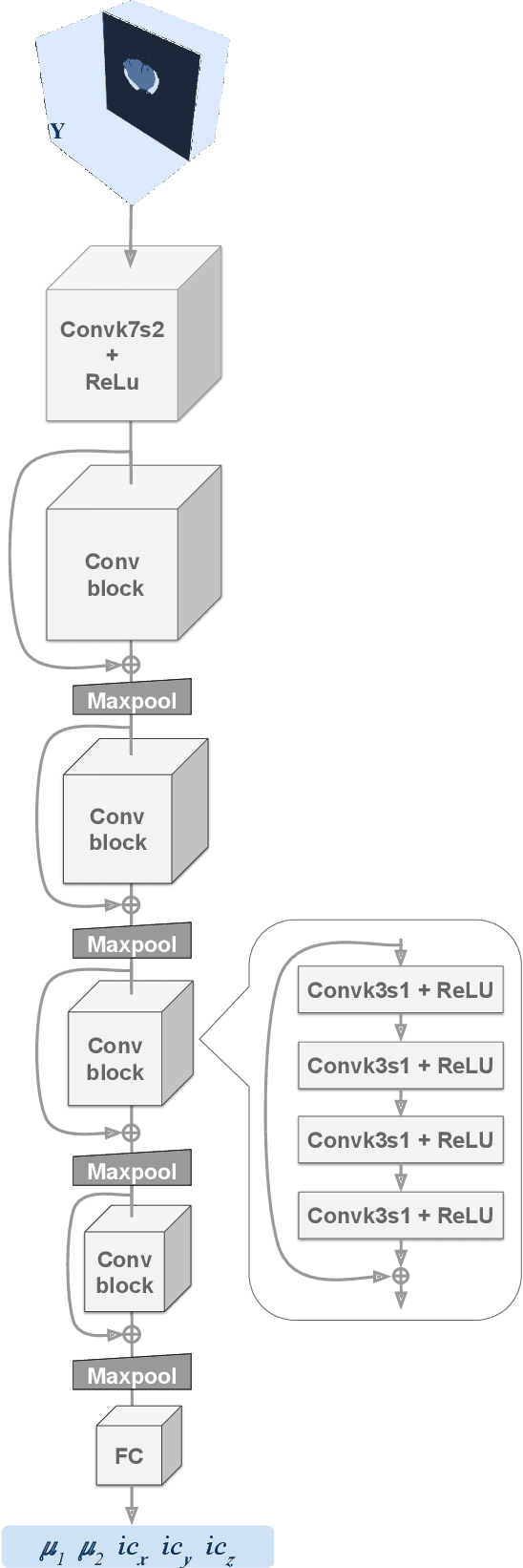

Current treatment planning of patients diagnosed with brain tumor could significantly benefit by accessing the spatial distribution of tumor cell concentration. Existing diagnostic modalities, such as magnetic-resonance imaging (MRI), contrast sufficiently well areas of high cell density. However, they do not portray areas of low concentration, which can often serve as a source for the secondary appearance of the tumor after treatment. Numerical simulations of tumor growth could complement imaging information by providing estimates of full spatial distributions of tumor cells. Over recent years a corpus of literature on medical image-based tumor modeling was published. It includes different mathematical formalisms describing the forward tumor growth model. Alongside, various parametric inference schemes were developed to perform an efficient tumor model personalization, i.e. solving the inverse problem. However, the unifying drawback of all existing approaches is the time complexity of the model personalization that prohibits a potential integration of the modeling into clinical settings. In this work, we introduce a methodology for inferring patient-specific spatial distribution of brain tumor from T1Gd and FLAIR MRI medical scans. Coined as \textit{Learn-Morph-Infer} the method achieves real-time performance in the order of minutes on widely available hardware and the compute time is stable across tumor models of different complexity, such as reaction-diffusion and reaction-advection-diffusion models. We believe the proposed inverse solution approach not only bridges the way for clinical translation of brain tumor personalization but can also be adopted to other scientific and engineering domains.
A Deep Learning Approach to Predicting Collateral Flow in Stroke Patients Using Radiomic Features from Perfusion Images
Oct 24, 2021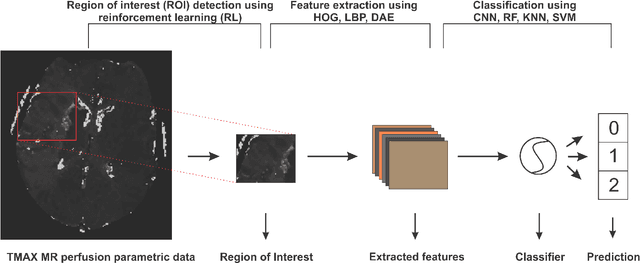
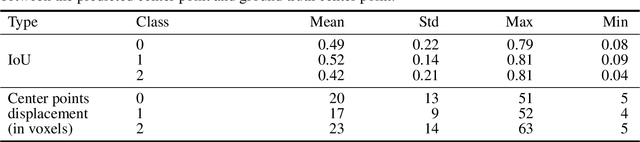
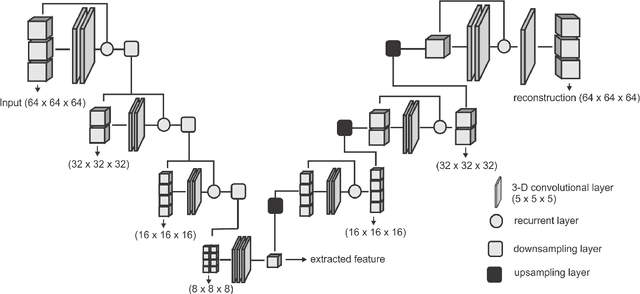
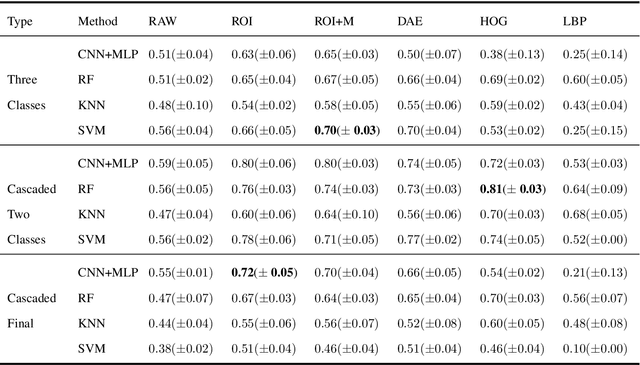
Collateral circulation results from specialized anastomotic channels which are capable of providing oxygenated blood to regions with compromised blood flow caused by ischemic injuries. The quality of collateral circulation has been established as a key factor in determining the likelihood of a favorable clinical outcome and goes a long way to determine the choice of stroke care model - that is the decision to transport or treat eligible patients immediately. Though there exist several imaging methods and grading criteria for quantifying collateral blood flow, the actual grading is mostly done through manual inspection of the acquired images. This approach is associated with a number of challenges. First, it is time-consuming - the clinician needs to scan through several slices of images to ascertain the region of interest before deciding on what severity grade to assign to a patient. Second, there is a high tendency for bias and inconsistency in the final grade assigned to a patient depending on the experience level of the clinician. We present a deep learning approach to predicting collateral flow grading in stroke patients based on radiomic features extracted from MR perfusion data. First, we formulate a region of interest detection task as a reinforcement learning problem and train a deep learning network to automatically detect the occluded region within the 3D MR perfusion volumes. Second, we extract radiomic features from the obtained region of interest through local image descriptors and denoising auto-encoders. Finally, we apply a convolutional neural network and other machine learning classifiers to the extracted radiomic features to automatically predict the collateral flow grading of the given patient volume as one of three severity classes - no flow (0), moderate flow (1), and good flow (2)...