 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactorPortrait: Controllable Portrait Animation via Disentangled Expression, Pose, and Viewpoint
Dec 12, 2025We introduce FactorPortrait, a video diffusion method for controllable portrait animation that enables lifelike synthesis from disentangled control signals of facial expressions, head movement, and camera viewpoints. Given a single portrait image, a driving video, and camera trajectories, our method animates the portrait by transferring facial expressions and head movements from the driving video while simultaneously enabling novel view synthesis from arbitrary viewpoints. We utilize a pre-trained image encoder to extract facial expression latents from the driving video as control signals for animation generation. Such latents implicitly capture nuanced facial expression dynamics with identity and pose information disentangled, and they are efficiently injected into the video diffusion transformer through our proposed expression controller. For camera and head pose control, we employ Plücker ray maps and normal maps rendered from 3D body mesh tracking. To train our model, we curate a large-scale synthetic dataset containing diverse combinations of camera viewpoints, head poses, and facial expression dynamics. Extensive experiments demonstrate that our method outperforms existing approaches in realism, expressiveness, control accuracy, and view consistency.
SHeaP: Self-Supervised Head Geometry Predictor Learned via 2D Gaussians
Apr 16, 2025Accurate, real-time 3D reconstruction of human heads from monocular images and videos underlies numerous visual applications. As 3D ground truth data is hard to come by at scale, previous methods have sought to learn from abundant 2D videos in a self-supervised manner. Typically, this involves the use of differentiable mesh rendering, which is effective but faces limitations. To improve on this, we propose SHeaP (Self-supervised Head Geometry Predictor Learned via 2D Gaussians). Given a source image, we predict a 3DMM mesh and a set of Gaussians that are rigged to this mesh. We then reanimate this rigged head avatar to match a target frame, and backpropagate photometric losses to both the 3DMM and Gaussian prediction networks. We find that using Gaussians for rendering substantially improves the effectiveness of this self-supervised approach. Training solely on 2D data, our method surpasses existing self-supervised approaches in geometric evaluations on the NoW benchmark for neutral faces and a new benchmark for non-neutral expressions. Our method also produces highly expressive meshes, outperforming state-of-the-art in emotion classification.
Monocular and Generalizable Gaussian Talking Head Animation
Apr 01, 2025



In this work, we introduce Monocular and Generalizable Gaussian Talking Head Animation (MGGTalk), which requires monocular datasets and generalizes to unseen identities without personalized re-training. Compared with previous 3D Gaussian Splatting (3DGS) methods that requires elusive multi-view datasets or tedious personalized learning/inference, MGGtalk enables more practical and broader applications. However, in the absence of multi-view and personalized training data, the incompleteness of geometric and appearance information poses a significant challenge. To address these challenges, MGGTalk explores depth information to enhance geometric and facial symmetry characteristics to supplement both geometric and appearance features. Initially, based on the pixel-wise geometric information obtained from depth estimation, we incorporate symmetry operations and point cloud filtering techniques to ensure a complete and precise position parameter for 3DGS. Subsequently, we adopt a two-stage strategy with symmetric priors for predicting the remaining 3DGS parameters. We begin by predicting Gaussian parameters for the visible facial regions of the source image. These parameters are subsequently utilized to improve the prediction of Gaussian parameters for the non-visible regions. Extensive experiments demonstrate that MGGTalk surpasses previous state-of-the-art methods, achieving superior performance across various metrics.
GAF: Gaussian Avatar Reconstruction from Monocular Videos via Multi-view Diffusion
Dec 13, 2024



We propose a novel approach for reconstructing animatable 3D Gaussian avatars from monocular videos captured by commodity devices like smartphones. Photorealistic 3D head avatar reconstruction from such recordings is challenging due to limited observations, which leaves unobserved regions under-constrained and can lead to artifacts in novel views. To address this problem, we introduce a multi-view head diffusion model, leveraging its priors to fill in missing regions and ensure view consistency in Gaussian splatting renderings. To enable precise viewpoint control, we use normal maps rendered from FLAME-based head reconstruction, which provides pixel-aligned inductive biases. We also condition the diffusion model on VAE features extracted from the input image to preserve details of facial identity and appearance. For Gaussian avatar reconstruction, we distill multi-view diffusion priors by using iteratively denoised images as pseudo-ground truths, effectively mitigating over-saturation issues. To further improve photorealism, we apply latent upsampling to refine the denoised latent before decoding it into an image. We evaluate our method on the NeRSemble dataset, showing that GAF outperforms the previous state-of-the-art methods in novel view synthesis by a 5.34\% higher SSIM score. Furthermore, we demonstrate higher-fidelity avatar reconstructions from monocular videos captured on commodity devices.
KMTalk: Speech-Driven 3D Facial Animation with Key Motion Embedding
Sep 02, 2024We present a novel approach for synthesizing 3D facial motions from audio sequences using key motion embeddings. Despite recent advancements in data-driven techniques, accurately mapping between audio signals and 3D facial meshes remains challenging. Direct regression of the entire sequence often leads to over-smoothed results due to the ill-posed nature of the problem. To this end, we propose a progressive learning mechanism that generates 3D facial animations by introducing key motion capture to decrease cross-modal mapping uncertainty and learning complexity. Concretely, our method integrates linguistic and data-driven priors through two modules: the linguistic-based key motion acquisition and the cross-modal motion completion. The former identifies key motions and learns the associated 3D facial expressions, ensuring accurate lip-speech synchronization. The latter extends key motions into a full sequence of 3D talking faces guided by audio features, improving temporal coherence and audio-visual consistency. Extensive experimental comparisons against existing state-of-the-art methods demonstrate the superiority of our approach in generating more vivid and consistent talking face animations. Consistent enhancements in results through the integration of our proposed learning scheme with existing methods underscore the efficacy of our approach. Our code and weights will be at the project website: \url{https://github.com/ffxzh/KMTalk}.
GGHead: Fast and Generalizable 3D Gaussian Heads
Jun 13, 2024Learning 3D head priors from large 2D image collections is an important step towards high-quality 3D-aware human modeling. A core requirement is an efficient architecture that scales well to large-scale datasets and large image resolutions. Unfortunately, existing 3D GANs struggle to scale to generate samples at high resolutions due to their relatively slow train and render speeds, and typically have to rely on 2D superresolution networks at the expense of global 3D consistency. To address these challenges, we propose Generative Gaussian Heads (GGHead), which adopts the recent 3D Gaussian Splatting representation within a 3D GAN framework. To generate a 3D representation, we employ a powerful 2D CNN generator to predict Gaussian attributes in the UV space of a template head mesh. This way, GGHead exploits the regularity of the template's UV layout, substantially facilitating the challenging task of predicting an unstructured set of 3D Gaussians. We further improve the geometric fidelity of the generated 3D representations with a novel total variation loss on rendered UV coordinates. Intuitively, this regularization encourages that neighboring rendered pixels should stem from neighboring Gaussians in the template's UV space. Taken together, our pipeline can efficiently generate 3D heads trained only from single-view 2D image observations. Our proposed framework matches the quality of existing 3D head GANs on FFHQ while being both substantially faster and fully 3D consistent. As a result, we demonstrate real-time generation and rendering of high-quality 3D-consistent heads at $1024^2$ resolution for the first time.
Motion2VecSets: 4D Latent Vector Set Diffusion for Non-rigid Shape Reconstruction and Tracking
Jan 12, 2024



We introduce Motion2VecSets, a 4D diffusion model for dynamic surface reconstruction from point cloud sequences. While existing state-of-the-art methods have demonstrated success in reconstructing non-rigid objects using neural field representations, conventional feed-forward networks encounter challenges with ambiguous observations from noisy, partial, or sparse point clouds. To address these challenges, we introduce a diffusion model that explicitly learns the shape and motion distribution of non-rigid objects through an iterative denoising process of compressed latent representations. The diffusion-based prior enables more plausible and probabilistic reconstructions when handling ambiguous inputs. We parameterize 4D dynamics with latent vector sets instead of using a global latent. This novel 4D representation allows us to learn local surface shape and deformation patterns, leading to more accurate non-linear motion capture and significantly improving generalizability to unseen motions and identities. For more temporal-coherent object tracking, we synchronously denoise deformation latent sets and exchange information across multiple frames. To avoid the computational overhead, we design an interleaved space and time attention block to alternately aggregate deformation latents along spatial and temporal domains. Extensive comparisons against the state-of-the-art methods demonstrate the superiority of our Motion2VecSets in 4D reconstruction from various imperfect observations, notably achieving a 19% improvement in Intersection over Union (IoU) compared to CaDex for reconstructing unseen individuals from sparse point clouds on the DeformingThings4D-Animals dataset. More detailed information can be found at https://vveicao.github.io/projects/Motion2VecSets/.
Surface Normal Estimation with Transformers
Jan 11, 2024We propose the use of a Transformer to accurately predict normals from point clouds with noise and density variations. Previous learning-based methods utilize PointNet variants to explicitly extract multi-scale features at different input scales, then focus on a surface fitting method by which local point cloud neighborhoods are fitted to a geometric surface approximated by either a polynomial function or a multi-layer perceptron (MLP). However, fitting surfaces to fixed-order polynomial functions can suffer from overfitting or underfitting, and learning MLP-represented hyper-surfaces requires pre-generated per-point weights. To avoid these limitations, we first unify the design choices in previous works and then propose a simplified Transformer-based model to extract richer and more robust geometric features for the surface normal estimation task. Through extensive experiments, we demonstrate that our Transformer-based method achieves state-of-the-art performance on both the synthetic shape dataset PCPNet, and the real-world indoor scene dataset SceneNN, exhibiting more noise-resilient behavior and significantly faster inference. Most importantly, we demonstrate that the sophisticated hand-designed modules in existing works are not necessary to excel at the task of surface normal estimation.
DPHMs: Diffusion Parametric Head Models for Depth-based Tracking
Dec 02, 2023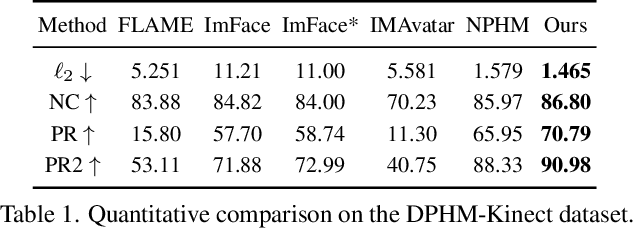
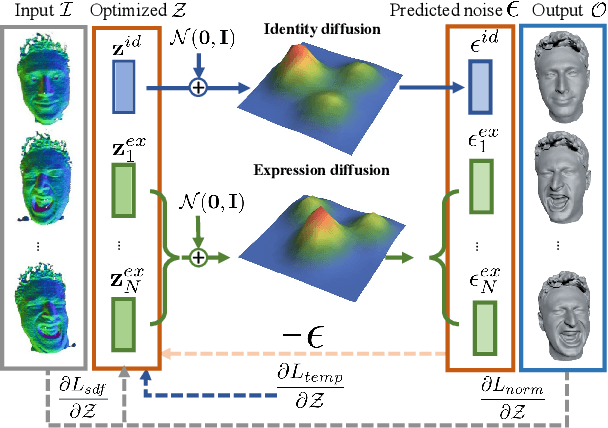
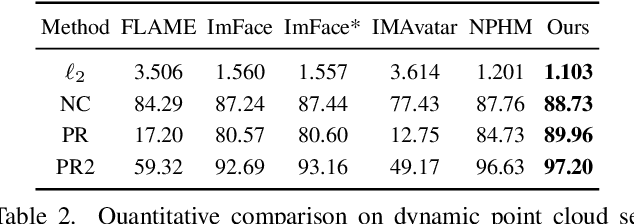

We introduce Diffusion Parametric Head Models (DPHMs), a generative model that enables robust volumetric head reconstruction and tracking from monocular depth sequences. While recent volumetric head models, such as NPHMs, can now excel in representing high-fidelity head geometries, tracking and reconstruction heads from real-world single-view depth sequences remains very challenging, as the fitting to partial and noisy observations is underconstrained. To tackle these challenges, we propose a latent diffusion-based prior to regularize volumetric head reconstruction and tracking. This prior-based regularizer effectively constrains the identity and expression codes to lie on the underlying latent manifold which represents plausible head shapes. To evaluate the effectiveness of the diffusion-based prior, we collect a dataset of monocular Kinect sequences consisting of various complex facial expression motions and rapid transitions. We compare our method to state-of-the-art tracking methods, and demonstrate improved head identity reconstruction as well as robust expression tracking.
DiffuScene: Scene Graph Denoising Diffusion Probabilistic Model for Generative Indoor Scene Synthesis
Mar 24, 2023

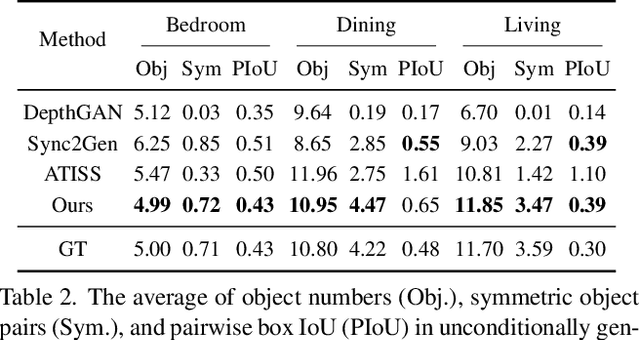

We present DiffuScene for indoor 3D scene synthesis based on a novel scene graph denoising diffusion probabilistic model, which generates 3D instance properties stored in a fully-connected scene graph and then retrieves the most similar object geometry for each graph node i.e. object instance which is characterized as a concatenation of different attributes, including location, size, orientation, semantic, and geometry features. Based on this scene graph, we designed a diffusion model to determine the placements and types of 3D instances. Our method can facilitate many downstream applications, including scene completion, scene arrangement, and text-conditioned scene synthesis. Experiments on the 3D-FRONT dataset show that our method can synthesize more physically plausible and diverse indoor scenes than state-of-the-art methods. Extensive ablation studies verify the effectiveness of our design choice in scene diffusion models.