 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonocular and Generalizable Gaussian Talking Head Animation
Apr 01, 2025



In this work, we introduce Monocular and Generalizable Gaussian Talking Head Animation (MGGTalk), which requires monocular datasets and generalizes to unseen identities without personalized re-training. Compared with previous 3D Gaussian Splatting (3DGS) methods that requires elusive multi-view datasets or tedious personalized learning/inference, MGGtalk enables more practical and broader applications. However, in the absence of multi-view and personalized training data, the incompleteness of geometric and appearance information poses a significant challenge. To address these challenges, MGGTalk explores depth information to enhance geometric and facial symmetry characteristics to supplement both geometric and appearance features. Initially, based on the pixel-wise geometric information obtained from depth estimation, we incorporate symmetry operations and point cloud filtering techniques to ensure a complete and precise position parameter for 3DGS. Subsequently, we adopt a two-stage strategy with symmetric priors for predicting the remaining 3DGS parameters. We begin by predicting Gaussian parameters for the visible facial regions of the source image. These parameters are subsequently utilized to improve the prediction of Gaussian parameters for the non-visible regions. Extensive experiments demonstrate that MGGTalk surpasses previous state-of-the-art methods, achieving superior performance across various metrics.
Unleashing the Potential of Multi-modal Foundation Models and Video Diffusion for 4D Dynamic Physical Scene Simulation
Nov 21, 2024



Realistic simulation of dynamic scenes requires accurately capturing diverse material properties and modeling complex object interactions grounded in physical principles. However, existing methods are constrained to basic material types with limited predictable parameters, making them insufficient to represent the complexity of real-world materials. We introduce a novel approach that leverages multi-modal foundation models and video diffusion to achieve enhanced 4D dynamic scene simulation. Our method utilizes multi-modal models to identify material types and initialize material parameters through image queries, while simultaneously inferring 3D Gaussian splats for detailed scene representation. We further refine these material parameters using video diffusion with a differentiable Material Point Method (MPM) and optical flow guidance rather than render loss or Score Distillation Sampling (SDS) loss. This integrated framework enables accurate prediction and realistic simulation of dynamic interactions in real-world scenarios, advancing both accuracy and flexibility in physics-based simulations.
SIR: Multi-view Inverse Rendering with Decomposable Shadow for Indoor Scenes
Feb 25, 2024



We propose SIR, an efficient method to decompose differentiable shadows for inverse rendering on indoor scenes using multi-view data, addressing the challenges in accurately decomposing the materials and lighting conditions. Unlike previous methods that struggle with shadow fidelity in complex lighting environments, our approach explicitly learns shadows for enhanced realism in material estimation under unknown light positions. Utilizing posed HDR images as input, SIR employs an SDF-based neural radiance field for comprehensive scene representation. Then, SIR integrates a shadow term with a three-stage material estimation approach to improve SVBRDF quality. Specifically, SIR is designed to learn a differentiable shadow, complemented by BRDF regularization, to optimize inverse rendering accuracy. Extensive experiments on both synthetic and real-world indoor scenes demonstrate the superior performance of SIR over existing methods in both quantitative metrics and qualitative analysis. The significant decomposing ability of SIR enables sophisticated editing capabilities like free-view relighting, object insertion, and material replacement. The code and data are available at https://xiaokangwei.github.io/SIR/.
RayDF: Neural Ray-surface Distance Fields with Multi-view Consistency
Oct 30, 2023In this paper, we study the problem of continuous 3D shape representations. The majority of existing successful methods are coordinate-based implicit neural representations. However, they are inefficient to render novel views or recover explicit surface points. A few works start to formulate 3D shapes as ray-based neural functions, but the learned structures are inferior due to the lack of multi-view geometry consistency. To tackle these challenges, we propose a new framework called RayDF. It consists of three major components: 1) the simple ray-surface distance field, 2) the novel dual-ray visibility classifier, and 3) a multi-view consistency optimization module to drive the learned ray-surface distances to be multi-view geometry consistent. We extensively evaluate our method on three public datasets, demonstrating remarkable performance in 3D surface point reconstruction on both synthetic and challenging real-world 3D scenes, clearly surpassing existing coordinate-based and ray-based baselines. Most notably, our method achieves a 1000x faster speed than coordinate-based methods to render an 800x800 depth image, showing the superiority of our method for 3D shape representation. Our code and data are available at https://github.com/vLAR-group/RayDF
Disentangling Writer and Character Styles for Handwriting Generation
Mar 31, 2023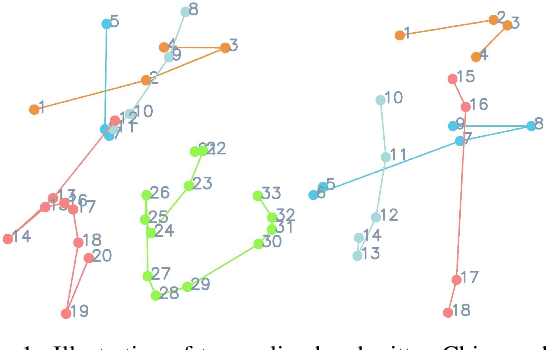



Training machines to synthesize diverse handwritings is an intriguing task. Recently, RNN-based methods have been proposed to generate stylized online Chinese characters. However, these methods mainly focus on capturing a person's overall writing style, neglecting subtle style inconsistencies between characters written by the same person. For example, while a person's handwriting typically exhibits general uniformity (e.g., glyph slant and aspect ratios), there are still small style variations in finer details (e.g., stroke length and curvature) of characters. In light of this, we propose to disentangle the style representations at both writer and character levels from individual handwritings to synthesize realistic stylized online handwritten characters. Specifically, we present the style-disentangled Transformer (SDT), which employs two complementary contrastive objectives to extract the style commonalities of reference samples and capture the detailed style patterns of each sample, respectively. Extensive experiments on various language scripts demonstrate the effectiveness of SDT. Notably, our empirical findings reveal that the two learned style representations provide information at different frequency magnitudes, underscoring the importance of separate style extraction. Our source code is public at: https://github.com/dailenson/SDT.
Deep View Synthesis via Self-Consistent Generative Network
Jan 19, 2021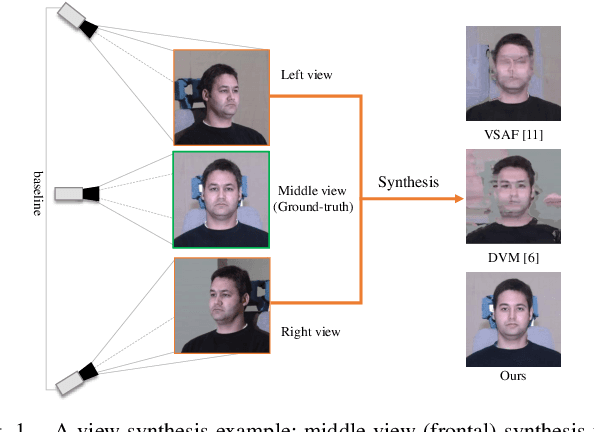



View synthesis aims to produce unseen views from a set of views captured by two or more cameras at different positions. This task is non-trivial since it is hard to conduct pixel-level matching among different views. To address this issue, most existing methods seek to exploit the geometric information to match pixels. However, when the distinct cameras have a large baseline (i.e., far away from each other), severe geometry distortion issues would occur and the geometric information may fail to provide useful guidance, resulting in very blurry synthesized images. To address the above issues, in this paper, we propose a novel deep generative model, called Self-Consistent Generative Network (SCGN), which synthesizes novel views from the given input views without explicitly exploiting the geometric information. The proposed SCGN model consists of two main components, i.e., a View Synthesis Network (VSN) and a View Decomposition Network (VDN), both employing an Encoder-Decoder structure. Here, the VDN seeks to reconstruct input views from the synthesized novel view to preserve the consistency of view synthesis. Thanks to VDN, SCGN is able to synthesize novel views without using any geometric rectification before encoding, making it easier for both training and applications. Finally, adversarial loss is introduced to improve the photo-realism of novel views. Both qualitative and quantitative comparisons against several state-of-the-art methods on two benchmark tasks demonstrated the superiority of our approach.