 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRADAR: Benchmarking Vision-Language-Action Generalization via Real-World Dynamics, Spatial-Physical Intelligence, and Autonomous Evaluation
Feb 11, 2026VLA models have achieved remarkable progress in embodied intelligence; however, their evaluation remains largely confined to simulations or highly constrained real-world settings. This mismatch creates a substantial reality gap, where strong benchmark performance often masks poor generalization in diverse physical environments. We identify three systemic shortcomings in current benchmarking practices that hinder fair and reliable model comparison. (1) Existing benchmarks fail to model real-world dynamics, overlooking critical factors such as dynamic object configurations, robot initial states, lighting changes, and sensor noise. (2) Current protocols neglect spatial--physical intelligence, reducing evaluation to rote manipulation tasks that do not probe geometric reasoning. (3) The field lacks scalable fully autonomous evaluation, instead relying on simplistic 2D metrics that miss 3D spatial structure or on human-in-the-loop systems that are costly, biased, and unscalable. To address these limitations, we introduce RADAR (Real-world Autonomous Dynamics And Reasoning), a benchmark designed to systematically evaluate VLA generalization under realistic conditions. RADAR integrates three core components: (1) a principled suite of physical dynamics; (2) dedicated tasks that explicitly test spatial reasoning and physical understanding; and (3) a fully autonomous evaluation pipeline based on 3D metrics, eliminating the need for human supervision. We apply RADAR to audit multiple state-of-the-art VLA models and uncover severe fragility beneath their apparent competence. Performance drops precipitously under modest physical dynamics, with the expectation of 3D IoU declining from 0.261 to 0.068 under sensor noise. Moreover, models exhibit limited spatial reasoning capability. These findings position RADAR as a necessary bench toward reliable and generalizable real-world evaluation of VLA models.
Neural Clothing Tryer: Customized Virtual Try-On via Semantic Enhancement and Controlling Diffusion Model
Jan 30, 2026This work aims to address a novel Customized Virtual Try-ON (Cu-VTON) task, enabling the superimposition of a specified garment onto a model that can be customized in terms of appearance, posture, and additional attributes. Compared with traditional VTON task, it enables users to tailor digital avatars to their individual preferences, thereby enhancing the virtual fitting experience with greater flexibility and engagement. To address this task, we introduce a Neural Clothing Tryer (NCT) framework, which exploits the advanced diffusion models equipped with semantic enhancement and controlling modules to better preserve semantic characterization and textural details of the garment and meanwhile facilitating the flexible editing of the model's postures and appearances. Specifically, NCT introduces a semantic-enhanced module to take semantic descriptions of garments and utilizes a visual-language encoder to learn aligned features across modalities. The aligned features are served as condition input to the diffusion model to enhance the preservation of the garment's semantics. Then, a semantic controlling module is designed to take the garment image, tailored posture image, and semantic description as input to maintain garment details while simultaneously editing model postures, expressions, and various attributes. Extensive experiments on the open available benchmark demonstrate the superior performance of the proposed NCT framework.
Exploring Talking Head Models With Adjacent Frame Prior for Speech-Preserving Facial Expression Manipulation
Jan 19, 2026Speech-Preserving Facial Expression Manipulation (SPFEM) is an innovative technique aimed at altering facial expressions in images and videos while retaining the original mouth movements. Despite advancements, SPFEM still struggles with accurate lip synchronization due to the complex interplay between facial expressions and mouth shapes. Capitalizing on the advanced capabilities of audio-driven talking head generation (AD-THG) models in synthesizing precise lip movements, our research introduces a novel integration of these models with SPFEM. We present a new framework, Talking Head Facial Expression Manipulation (THFEM), which utilizes AD-THG models to generate frames with accurately synchronized lip movements from audio inputs and SPFEM-altered images. However, increasing the number of frames generated by AD-THG models tends to compromise the realism and expression fidelity of the images. To counter this, we develop an adjacent frame learning strategy that finetunes AD-THG models to predict sequences of consecutive frames. This strategy enables the models to incorporate information from neighboring frames, significantly improving image quality during testing. Our extensive experimental evaluations demonstrate that this framework effectively preserves mouth shapes during expression manipulations, highlighting the substantial benefits of integrating AD-THG with SPFEM.
Geometry-Editable and Appearance-Preserving Object Compositon
May 27, 2025General object composition (GOC) aims to seamlessly integrate a target object into a background scene with desired geometric properties, while simultaneously preserving its fine-grained appearance details. Recent approaches derive semantic embeddings and integrate them into advanced diffusion models to enable geometry-editable generation. However, these highly compact embeddings encode only high-level semantic cues and inevitably discard fine-grained appearance details. We introduce a Disentangled Geometry-editable and Appearance-preserving Diffusion (DGAD) model that first leverages semantic embeddings to implicitly capture the desired geometric transformations and then employs a cross-attention retrieval mechanism to align fine-grained appearance features with the geometry-edited representation, facilitating both precise geometry editing and faithful appearance preservation in object composition. Specifically, DGAD builds on CLIP/DINO-derived and reference networks to extract semantic embeddings and appearance-preserving representations, which are then seamlessly integrated into the encoding and decoding pipelines in a disentangled manner. We first integrate the semantic embeddings into pre-trained diffusion models that exhibit strong spatial reasoning capabilities to implicitly capture object geometry, thereby facilitating flexible object manipulation and ensuring effective editability. Then, we design a dense cross-attention mechanism that leverages the implicitly learned object geometry to retrieve and spatially align appearance features with their corresponding regions, ensuring faithful appearance consistency. Extensive experiments on public benchmarks demonstrate the effectiveness of the proposed DGAD framework.
ReplayCAD: Generative Diffusion Replay for Continual Anomaly Detection
May 10, 2025



Continual Anomaly Detection (CAD) enables anomaly detection models in learning new classes while preserving knowledge of historical classes. CAD faces two key challenges: catastrophic forgetting and segmentation of small anomalous regions. Existing CAD methods store image distributions or patch features to mitigate catastrophic forgetting, but they fail to preserve pixel-level detailed features for accurate segmentation. To overcome this limitation, we propose ReplayCAD, a novel diffusion-driven generative replay framework that replay high-quality historical data, thus effectively preserving pixel-level detailed features. Specifically, we compress historical data by searching for a class semantic embedding in the conditional space of the pre-trained diffusion model, which can guide the model to replay data with fine-grained pixel details, thus improving the segmentation performance. However, relying solely on semantic features results in limited spatial diversity. Hence, we further use spatial features to guide data compression, achieving precise control of sample space, thereby generating more diverse data. Our method achieves state-of-the-art performance in both classification and segmentation, with notable improvements in segmentation: 11.5% on VisA and 8.1% on MVTec. Our source code is available at https://github.com/HULEI7/ReplayCAD.
Contrastive Decoupled Representation Learning and Regularization for Speech-Preserving Facial Expression Manipulation
Apr 08, 2025Speech-preserving facial expression manipulation (SPFEM) aims to modify a talking head to display a specific reference emotion while preserving the mouth animation of source spoken contents. Thus, emotion and content information existing in reference and source inputs can provide direct and accurate supervision signals for SPFEM models. However, the intrinsic intertwining of these elements during the talking process poses challenges to their effectiveness as supervisory signals. In this work, we propose to learn content and emotion priors as guidance augmented with contrastive learning to learn decoupled content and emotion representation via an innovative Contrastive Decoupled Representation Learning (CDRL) algorithm. Specifically, a Contrastive Content Representation Learning (CCRL) module is designed to learn audio feature, which primarily contains content information, as content priors to guide learning content representation from the source input. Meanwhile, a Contrastive Emotion Representation Learning (CERL) module is proposed to make use of a pre-trained visual-language model to learn emotion prior, which is then used to guide learning emotion representation from the reference input. We further introduce emotion-aware and emotion-augmented contrastive learning to train CCRL and CERL modules, respectively, ensuring learning emotion-independent content representation and content-independent emotion representation. During SPFEM model training, the decoupled content and emotion representations are used to supervise the generation process, ensuring more accurate emotion manipulation together with audio-lip synchronization. Extensive experiments and evaluations on various benchmarks show the effectiveness of the proposed algorithm.
Exploiting Temporal Audio-Visual Correlation Embedding for Audio-Driven One-Shot Talking Head Animation
Apr 08, 2025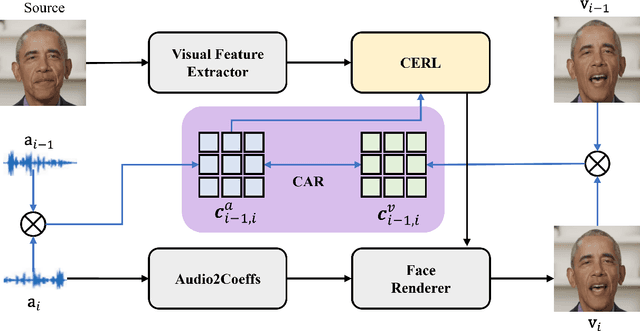
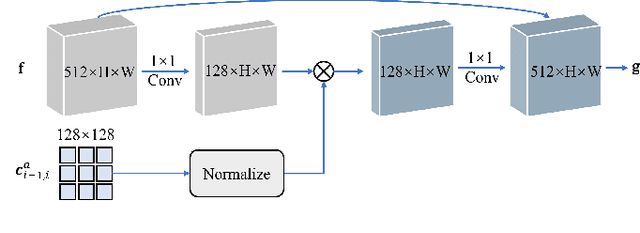
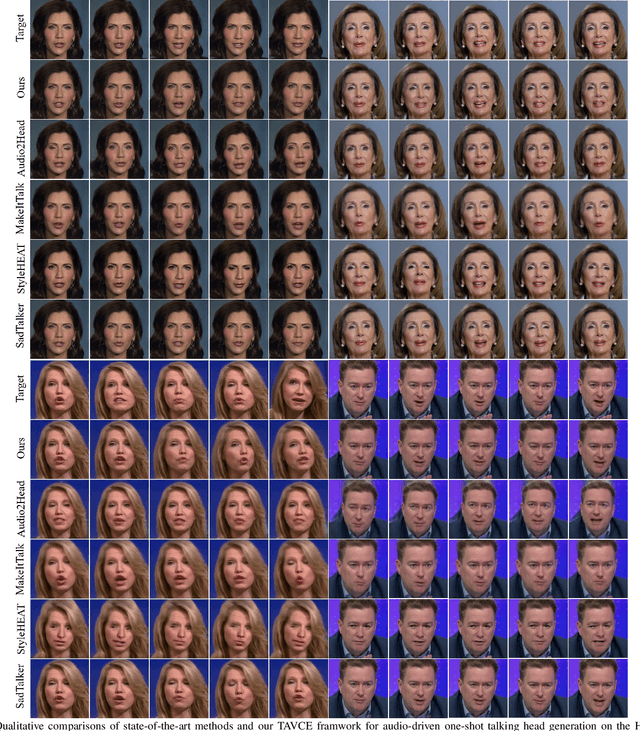

The paramount challenge in audio-driven One-shot Talking Head Animation (ADOS-THA) lies in capturing subtle imperceptible changes between adjacent video frames. Inherently, the temporal relationship of adjacent audio clips is highly correlated with that of the corresponding adjacent video frames, offering supplementary information that can be pivotal for guiding and supervising talking head animations. In this work, we propose to learn audio-visual correlations and integrate the correlations to help enhance feature representation and regularize final generation by a novel Temporal Audio-Visual Correlation Embedding (TAVCE) framework. Specifically, it first learns an audio-visual temporal correlation metric, ensuring the temporal audio relationships of adjacent clips are aligned with the temporal visual relationships of corresponding adjacent video frames. Since the temporal audio relationship contains aligned information about the visual frame, we first integrate it to guide learning more representative features via a simple yet effective channel attention mechanism. During training, we also use the alignment correlations as an additional objective to supervise generating visual frames. We conduct extensive experiments on several publicly available benchmarks (i.e., HDTF, LRW, VoxCeleb1, and VoxCeleb2) to demonstrate its superiority over existing leading algorithms.
Monocular and Generalizable Gaussian Talking Head Animation
Apr 01, 2025



In this work, we introduce Monocular and Generalizable Gaussian Talking Head Animation (MGGTalk), which requires monocular datasets and generalizes to unseen identities without personalized re-training. Compared with previous 3D Gaussian Splatting (3DGS) methods that requires elusive multi-view datasets or tedious personalized learning/inference, MGGtalk enables more practical and broader applications. However, in the absence of multi-view and personalized training data, the incompleteness of geometric and appearance information poses a significant challenge. To address these challenges, MGGTalk explores depth information to enhance geometric and facial symmetry characteristics to supplement both geometric and appearance features. Initially, based on the pixel-wise geometric information obtained from depth estimation, we incorporate symmetry operations and point cloud filtering techniques to ensure a complete and precise position parameter for 3DGS. Subsequently, we adopt a two-stage strategy with symmetric priors for predicting the remaining 3DGS parameters. We begin by predicting Gaussian parameters for the visible facial regions of the source image. These parameters are subsequently utilized to improve the prediction of Gaussian parameters for the non-visible regions. Extensive experiments demonstrate that MGGTalk surpasses previous state-of-the-art methods, achieving superior performance across various metrics.
Learning Semantic-Aware Representation in Visual-Language Models for Multi-Label Recognition with Partial Labels
Dec 14, 2024



Multi-label recognition with partial labels (MLR-PL), in which only some labels are known while others are unknown for each image, is a practical task in computer vision, since collecting large-scale and complete multi-label datasets is difficult in real application scenarios. Recently, vision language models (e.g. CLIP) have demonstrated impressive transferability to downstream tasks in data limited or label limited settings. However, current CLIP-based methods suffer from semantic confusion in MLR task due to the lack of fine-grained information in the single global visual and textual representation for all categories. In this work, we address this problem by introducing a semantic decoupling module and a category-specific prompt optimization method in CLIP-based framework. Specifically, the semantic decoupling module following the visual encoder learns category-specific feature maps by utilizing the semantic-guided spatial attention mechanism. Moreover, the category-specific prompt optimization method is introduced to learn text representations aligned with category semantics. Therefore, the prediction of each category is independent, which alleviate the semantic confusion problem. Extensive experiments on Microsoft COCO 2014 and Pascal VOC 2007 datasets demonstrate that the proposed framework significantly outperforms current state-of-art methods with a simpler model structure. Additionally, visual analysis shows that our method effectively separates information from different categories and achieves better performance compared to CLIP-based baseline method.
Globally Correlation-Aware Hard Negative Generation
Nov 20, 2024Hard negative generation aims to generate informative negative samples that help to determine the decision boundaries and thus facilitate advancing deep metric learning. Current works select pair/triplet samples, learn their correlations, and fuse them to generate hard negatives. However, these works merely consider the local correlations of selected samples, ignoring global sample correlations that would provide more significant information to generate more informative negatives. In this work, we propose a Globally Correlation-Aware Hard Negative Generation (GCA-HNG) framework, which first learns sample correlations from a global perspective and exploits these correlations to guide generating hardness-adaptive and diverse negatives. Specifically, this approach begins by constructing a structured graph to model sample correlations, where each node represents a specific sample and each edge represents the correlations between corresponding samples. Then, we introduce an iterative graph message propagation to propagate the messages of node and edge through the whole graph and thus learn the sample correlations globally. Finally, with the guidance of the learned global correlations, we propose a channel-adaptive manner to combine an anchor and multiple negatives for HNG. Compared to current methods, GCA-HNG allows perceiving sample correlations with numerous negatives from a global and comprehensive perspective and generates the negatives with better hardness and diversity. Extensive experiment results demonstrate that the proposed GCA-HNG is superior to related methods on four image retrieval benchmark datasets. Codes and trained models are available at \url{https://github.com/PWenJay/GCA-HNG}.