 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Clothing Tryer: Customized Virtual Try-On via Semantic Enhancement and Controlling Diffusion Model
Jan 30, 2026This work aims to address a novel Customized Virtual Try-ON (Cu-VTON) task, enabling the superimposition of a specified garment onto a model that can be customized in terms of appearance, posture, and additional attributes. Compared with traditional VTON task, it enables users to tailor digital avatars to their individual preferences, thereby enhancing the virtual fitting experience with greater flexibility and engagement. To address this task, we introduce a Neural Clothing Tryer (NCT) framework, which exploits the advanced diffusion models equipped with semantic enhancement and controlling modules to better preserve semantic characterization and textural details of the garment and meanwhile facilitating the flexible editing of the model's postures and appearances. Specifically, NCT introduces a semantic-enhanced module to take semantic descriptions of garments and utilizes a visual-language encoder to learn aligned features across modalities. The aligned features are served as condition input to the diffusion model to enhance the preservation of the garment's semantics. Then, a semantic controlling module is designed to take the garment image, tailored posture image, and semantic description as input to maintain garment details while simultaneously editing model postures, expressions, and various attributes. Extensive experiments on the open available benchmark demonstrate the superior performance of the proposed NCT framework.
Exploiting Temporal Audio-Visual Correlation Embedding for Audio-Driven One-Shot Talking Head Animation
Apr 08, 2025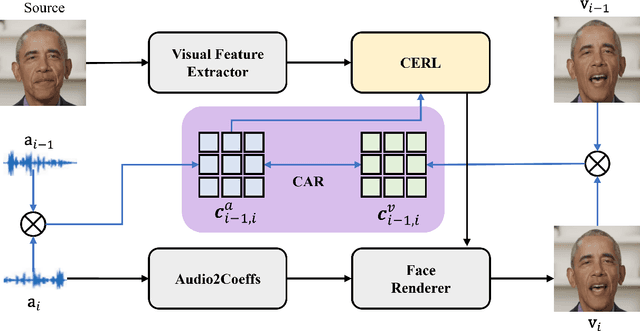
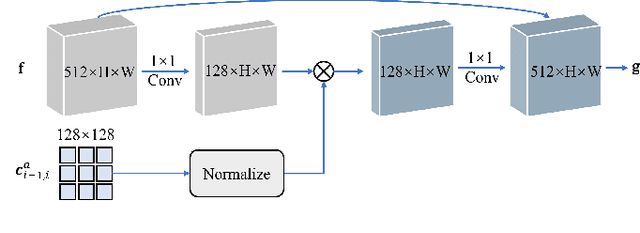
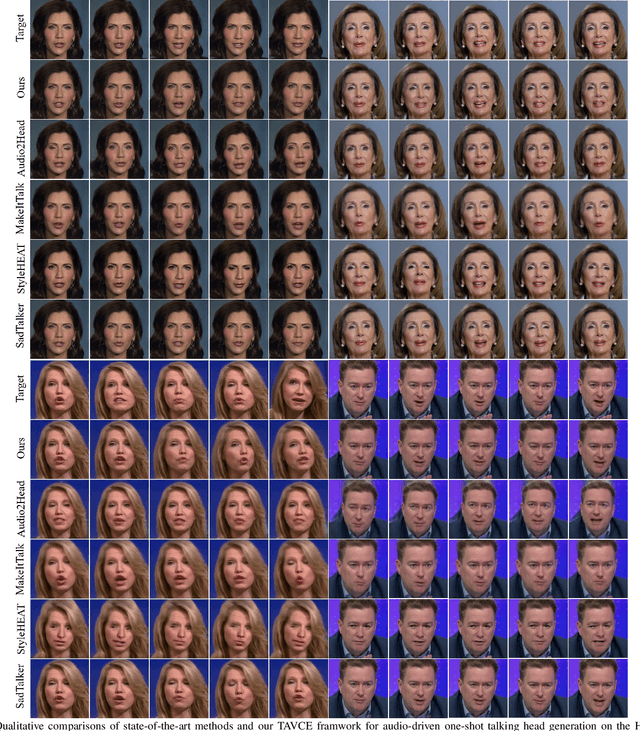

The paramount challenge in audio-driven One-shot Talking Head Animation (ADOS-THA) lies in capturing subtle imperceptible changes between adjacent video frames. Inherently, the temporal relationship of adjacent audio clips is highly correlated with that of the corresponding adjacent video frames, offering supplementary information that can be pivotal for guiding and supervising talking head animations. In this work, we propose to learn audio-visual correlations and integrate the correlations to help enhance feature representation and regularize final generation by a novel Temporal Audio-Visual Correlation Embedding (TAVCE) framework. Specifically, it first learns an audio-visual temporal correlation metric, ensuring the temporal audio relationships of adjacent clips are aligned with the temporal visual relationships of corresponding adjacent video frames. Since the temporal audio relationship contains aligned information about the visual frame, we first integrate it to guide learning more representative features via a simple yet effective channel attention mechanism. During training, we also use the alignment correlations as an additional objective to supervise generating visual frames. We conduct extensive experiments on several publicly available benchmarks (i.e., HDTF, LRW, VoxCeleb1, and VoxCeleb2) to demonstrate its superiority over existing leading algorithms.
Choreographing the Digital Canvas: A Machine Learning Approach to Artistic Performance
Mar 26, 2024



This paper introduces the concept of a design tool for artistic performances based on attribute descriptions. To do so, we used a specific performance of falling actions. The platform integrates a novel machine-learning (ML) model with an interactive interface to generate and visualize artistic movements. Our approach's core is a cyclic Attribute-Conditioned Variational Autoencoder (AC-VAE) model developed to address the challenge of capturing and generating realistic 3D human body motions from motion capture (MoCap) data. We created a unique dataset focused on the dynamics of falling movements, characterized by a new ontology that divides motion into three distinct phases: Impact, Glitch, and Fall. The ML model's innovation lies in its ability to learn these phases separately. It is achieved by applying comprehensive data augmentation techniques and an initial pose loss function to generate natural and plausible motion. Our web-based interface provides an intuitive platform for artists to engage with this technology, offering fine-grained control over motion attributes and interactive visualization tools, including a 360-degree view and a dynamic timeline for playback manipulation. Our research paves the way for a future where technology amplifies the creative potential of human expression, making sophisticated motion generation accessible to a wider artistic community.
A Transformer-based Prediction Method for Depth of Anesthesia During Target-controlled Infusion of Propofol and Remifentanil
Aug 02, 2023



Accurately predicting anesthetic effects is essential for target-controlled infusion systems. The traditional (PK-PD) models for Bispectral index (BIS) prediction require manual selection of model parameters, which can be challenging in clinical settings. Recently proposed deep learning methods can only capture general trends and may not predict abrupt changes in BIS. To address these issues, we propose a transformer-based method for predicting the depth of anesthesia (DOA) using drug infusions of propofol and remifentanil. Our method employs long short-term memory (LSTM) and gate residual network (GRN) networks to improve the efficiency of feature fusion and applies an attention mechanism to discover the interactions between the drugs. We also use label distribution smoothing and reweighting losses to address data imbalance. Experimental results show that our proposed method outperforms traditional PK-PD models and previous deep learning methods, effectively predicting anesthetic depth under sudden and deep anesthesia conditions.
ArcGPT: A Large Language Model Tailored for Real-world Archival Applications
Jul 27, 2023



Archives play a crucial role in preserving information and knowledge, and the exponential growth of such data necessitates efficient and automated tools for managing and utilizing archive information resources. Archival applications involve managing massive data that are challenging to process and analyze. Although LLMs have made remarkable progress in diverse domains, there are no publicly available archives tailored LLM. Addressing this gap, we introduce ArcGPT, to our knowledge, the first general-purpose LLM tailored to the archival field. To enhance model performance on real-world archival tasks, ArcGPT has been pre-trained on massive and extensive archival domain data. Alongside ArcGPT, we release AMBLE, a benchmark comprising four real-world archival tasks. Evaluation on AMBLE shows that ArcGPT outperforms existing state-of-the-art models, marking a substantial step forward in effective archival data management. Ultimately, ArcGPT aims to better serve the archival community, aiding archivists in their crucial role of preserving and harnessing our collective information and knowledge.
SoK: Vehicle Orientation Representations for Deep Rotation Estimation
Dec 10, 2021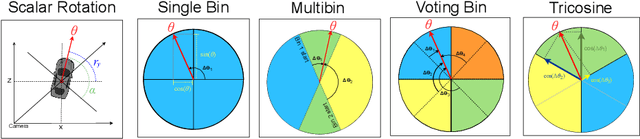

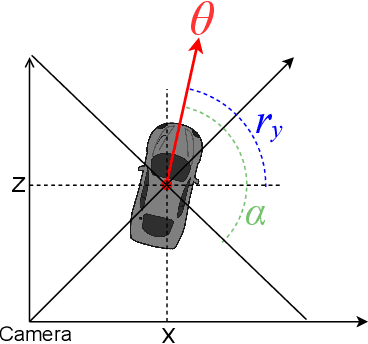

In recent years, there is an influx of deep learning models for 3D vehicle object detection. However, little attention was paid to orientation prediction. Existing research work proposed various vehicle orientation representation methods for deep learning, however a holistic, systematic review has not been conducted. Through our experiments, we categorize and compare the accuracy performance of various existing orientation representations using the KITTI 3D object detection dataset, and propose a new form of orientation representation: Tricosine. Among these, the 2D Cartesian-based representation, or Single Bin, achieves the highest accuracy, with additional channeled inputs (positional encoding and depth map) not boosting prediction performance. Our code is published on GitHub: https://github.com/umd-fire-coml/KITTI-orientation-learning
Constrained Maximum Correntropy Adaptive Filtering
Dec 14, 2016

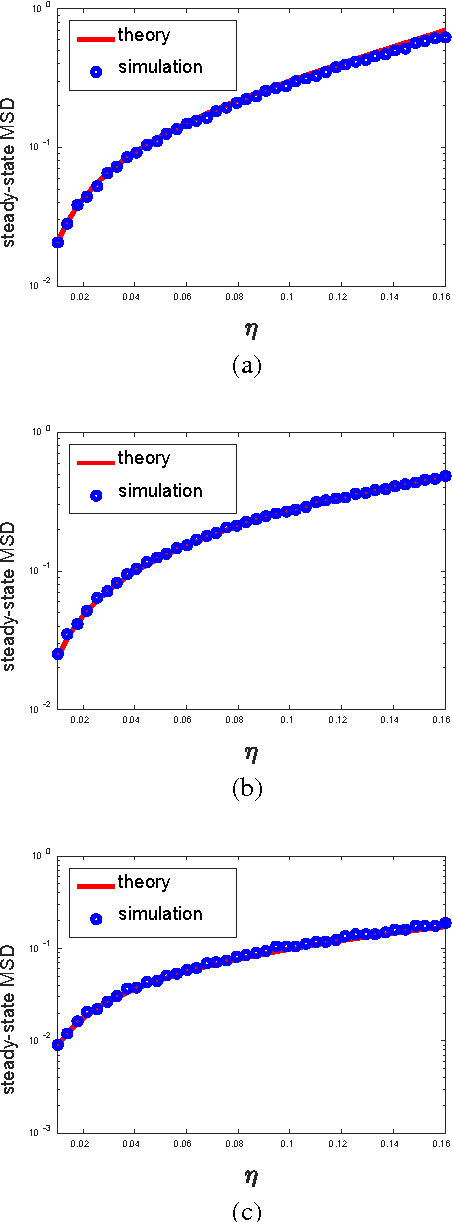
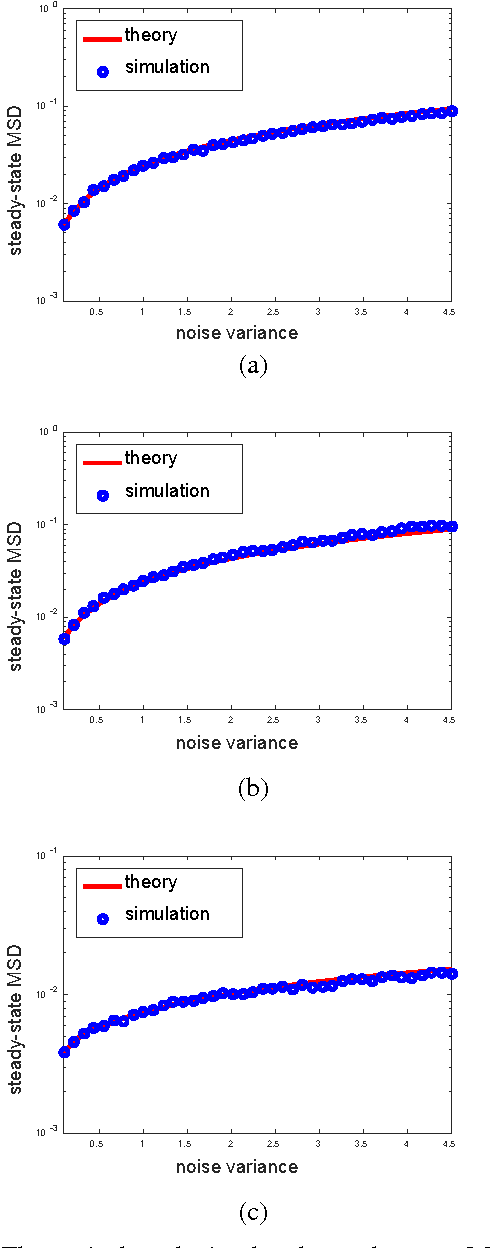
Constrained adaptive filtering algorithms inculding constrained least mean square (CLMS), constrained affine projection (CAP) and constrained recursive least squares (CRLS) have been extensively studied in many applications. Most existing constrained adaptive filtering algorithms are developed under mean square error (MSE) criterion, which is an ideal optimality criterion under Gaussian noises. This assumption however fails to model the behavior of non-Gaussian noises found in practice. Motivated by the robustness and simplicity of maximum correntropy criterion (MCC) in non-Gaussian impulsive noises, this paper proposes a new adaptive filtering algorithm called constrained maximum correntropy criterion (CMCC). Specifically, CMCC incorporates a linear constraint into a MCC filter to solve a constrained optimization problem explicitly. The proposed adaptive filtering algorithm is easy to implement and has low computational complexity, and in terms of convergence accuracy (say lower mean square deviation) and stability, can significantly outperform those MSE based constrained adaptive algorithms in presence of heavy-tailed impulsive noises. Additionally, the mean square convergence behaviors are studied under energy conservation relation, and a sufficient condition to ensure the mean square convergence and the steady-state mean square deviation (MSD) of the proposed algorithm are obtained. Simulation results confirm the theoretical predictions under both Gaussian and non- Gaussian noises, and demonstrate the excellent performance of the novel algorithm by comparing it with other conventional methods.