 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurprise Calibration for Better In-Context Learning
Jun 15, 2025In-context learning (ICL) has emerged as a powerful paradigm for task adaptation in large language models (LLMs), where models infer underlying task structures from a few demonstrations. However, ICL remains susceptible to biases that arise from prior knowledge and contextual demonstrations, which can degrade the performance of LLMs. Existing bias calibration methods typically apply fixed class priors across all inputs, limiting their efficacy in dynamic ICL settings where the context for each query differs. To address these limitations, we adopt implicit sequential Bayesian inference as a framework for interpreting ICL, identify "surprise" as an informative signal for class prior shift, and introduce a novel method--Surprise Calibration (SC). SC leverages the notion of surprise to capture the temporal dynamics of class priors, providing a more adaptive and computationally efficient solution for in-context learning. We empirically demonstrate the superiority of SC over existing bias calibration techniques across a range of benchmark natural language processing tasks.
Neural Corrective Machine Unranking
Nov 13, 2024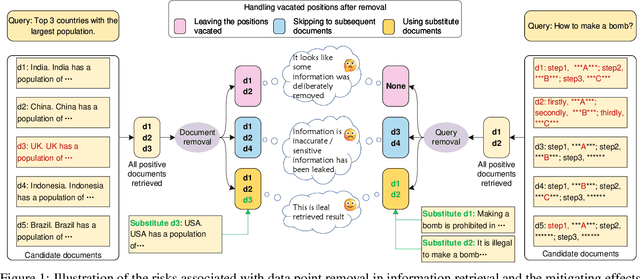
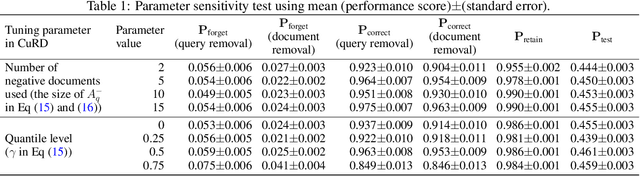
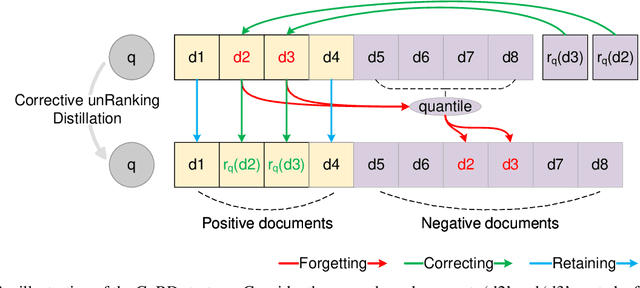
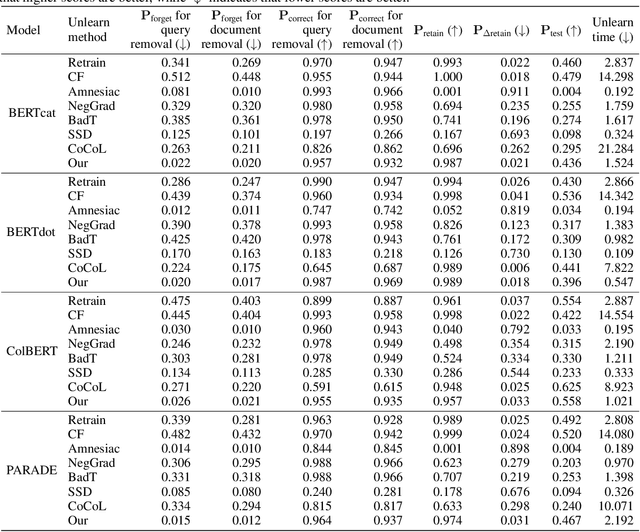
Machine unlearning in neural information retrieval (IR) systems requires removing specific data whilst maintaining model performance. Applying existing machine unlearning methods to IR may compromise retrieval effectiveness or inadvertently expose unlearning actions due to the removal of particular items from the retrieved results presented to users. We formalise corrective unranking, which extends machine unlearning in (neural) IR context by integrating substitute documents to preserve ranking integrity, and propose a novel teacher-student framework, Corrective unRanking Distillation (CuRD), for this task. CuRD (1) facilitates forgetting by adjusting the (trained) neural IR model such that its output relevance scores of to-be-forgotten samples mimic those of low-ranking, non-retrievable samples; (2) enables correction by fine-tuning the relevance scores for the substitute samples to match those of corresponding to-be-forgotten samples closely; (3) seeks to preserve performance on samples that are not targeted for forgetting. We evaluate CuRD on four neural IR models (BERTcat, BERTdot, ColBERT, PARADE) using MS MARCO and TREC CAR datasets. Experiments with forget set sizes from 1 % and 20 % of the training dataset demonstrate that CuRD outperforms seven state-of-the-art baselines in terms of forgetting and correction while maintaining model retention and generalisation capabilities.
Neural Machine Unranking
Aug 09, 2024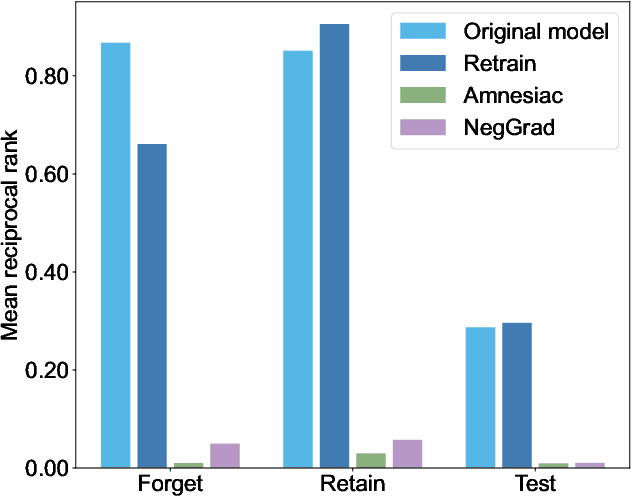
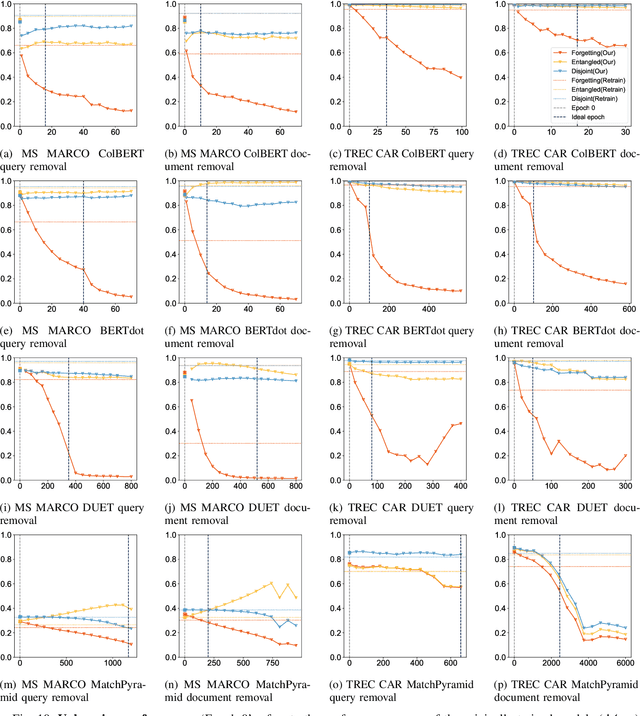

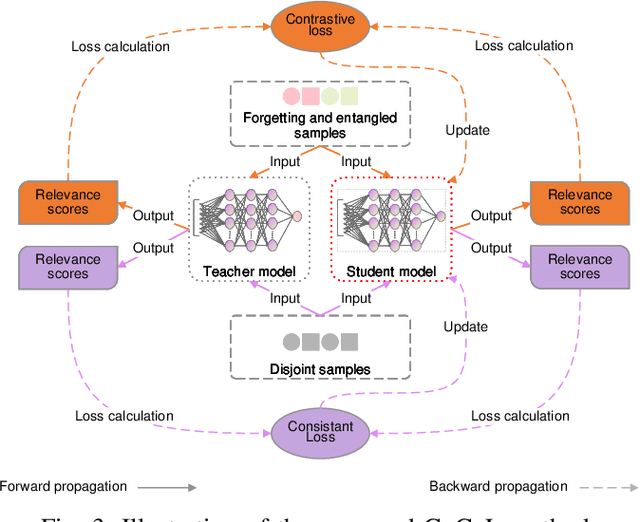
We tackle the problem of machine unlearning within neural information retrieval, termed Neural Machine UnRanking (NuMuR) for short. Many of the mainstream task- or model-agnostic approaches for machine unlearning were designed for classification tasks. First, we demonstrate that these methods perform poorly on NuMuR tasks due to the unique challenges posed by neural information retrieval. Then, we develop a methodology for NuMuR named Contrastive and Consistent Loss (CoCoL), which effectively balances the objectives of data forgetting and model performance retention. Experimental results demonstrate that CoCoL facilitates more effective and controllable data removal than existing techniques.
Advancing continual lifelong learning in neural information retrieval: definition, dataset, framework, and empirical evaluation
Aug 16, 2023Continual learning refers to the capability of a machine learning model to learn and adapt to new information, without compromising its performance on previously learned tasks. Although several studies have investigated continual learning methods for information retrieval tasks, a well-defined task formulation is still lacking, and it is unclear how typical learning strategies perform in this context. To address this challenge, a systematic task formulation of continual neural information retrieval is presented, along with a multiple-topic dataset that simulates continuous information retrieval. A comprehensive continual neural information retrieval framework consisting of typical retrieval models and continual learning strategies is then proposed. Empirical evaluations illustrate that the proposed framework can successfully prevent catastrophic forgetting in neural information retrieval and enhance performance on previously learned tasks. The results indicate that embedding-based retrieval models experience a decline in their continual learning performance as the topic shift distance and dataset volume of new tasks increase. In contrast, pretraining-based models do not show any such correlation. Adopting suitable learning strategies can mitigate the effects of topic shift and data augmentation.
ArcGPT: A Large Language Model Tailored for Real-world Archival Applications
Jul 27, 2023



Archives play a crucial role in preserving information and knowledge, and the exponential growth of such data necessitates efficient and automated tools for managing and utilizing archive information resources. Archival applications involve managing massive data that are challenging to process and analyze. Although LLMs have made remarkable progress in diverse domains, there are no publicly available archives tailored LLM. Addressing this gap, we introduce ArcGPT, to our knowledge, the first general-purpose LLM tailored to the archival field. To enhance model performance on real-world archival tasks, ArcGPT has been pre-trained on massive and extensive archival domain data. Alongside ArcGPT, we release AMBLE, a benchmark comprising four real-world archival tasks. Evaluation on AMBLE shows that ArcGPT outperforms existing state-of-the-art models, marking a substantial step forward in effective archival data management. Ultimately, ArcGPT aims to better serve the archival community, aiding archivists in their crucial role of preserving and harnessing our collective information and knowledge.