 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Corrective Machine Unranking
Paper and Code
Nov 13, 2024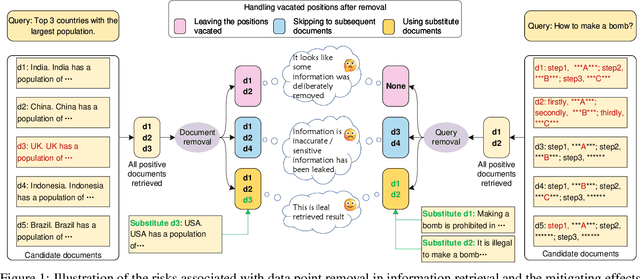
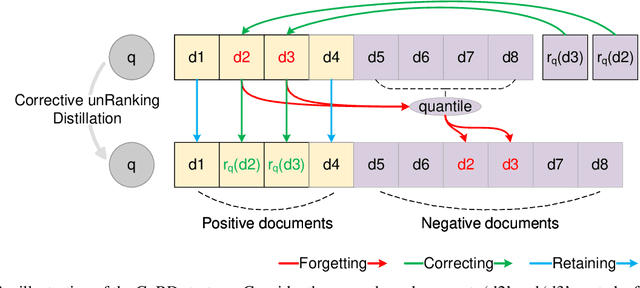
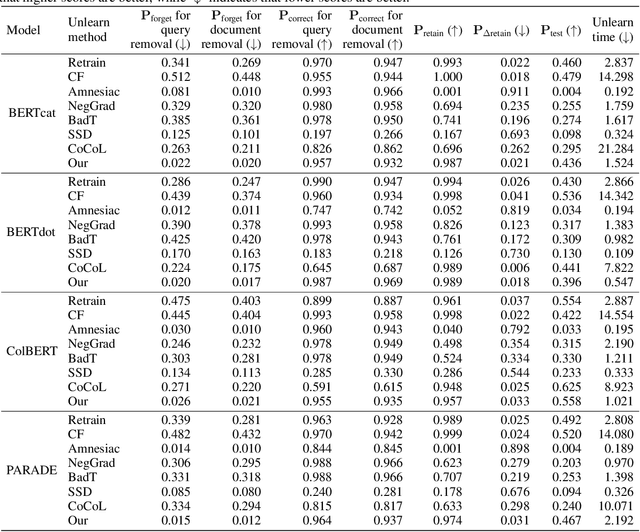
Machine unlearning in neural information retrieval (IR) systems requires removing specific data whilst maintaining model performance. Applying existing machine unlearning methods to IR may compromise retrieval effectiveness or inadvertently expose unlearning actions due to the removal of particular items from the retrieved results presented to users. We formalise corrective unranking, which extends machine unlearning in (neural) IR context by integrating substitute documents to preserve ranking integrity, and propose a novel teacher-student framework, Corrective unRanking Distillation (CuRD), for this task. CuRD (1) facilitates forgetting by adjusting the (trained) neural IR model such that its output relevance scores of to-be-forgotten samples mimic those of low-ranking, non-retrievable samples; (2) enables correction by fine-tuning the relevance scores for the substitute samples to match those of corresponding to-be-forgotten samples closely; (3) seeks to preserve performance on samples that are not targeted for forgetting. We evaluate CuRD on four neural IR models (BERTcat, BERTdot, ColBERT, PARADE) using MS MARCO and TREC CAR datasets. Experiments with forget set sizes from 1 % and 20 % of the training dataset demonstrate that CuRD outperforms seven state-of-the-art baselines in terms of forgetting and correction while maintaining model retention and generalisation capabilities.