 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the limitation of evaluating machine unlearning using only a single training seed
Oct 30, 2025Machine unlearning (MU) aims to remove the influence of certain data points from a trained model without costly retraining. Most practical MU algorithms are only approximate and their performance can only be assessed empirically. Care must therefore be taken to make empirical comparisons as representative as possible. A common practice is to run the MU algorithm multiple times independently starting from the same trained model. In this work, we demonstrate that this practice can give highly non-representative results because -- even for the same architecture and same dataset -- some MU methods can be highly sensitive to the choice of random number seed used for model training. We therefore recommend that empirical comphttps://info.arxiv.org/help/prep#commentsarisons of MU algorithms should also reflect the variability across different model training seeds.
Neural Corrective Machine Unranking
Nov 13, 2024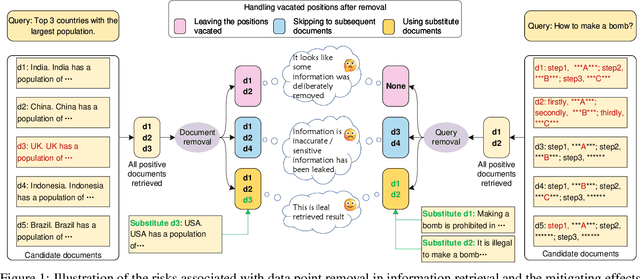
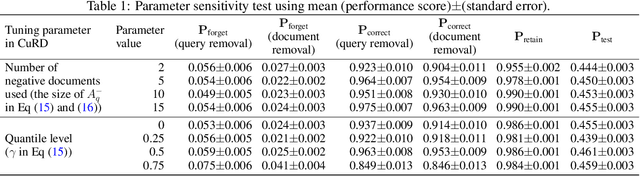
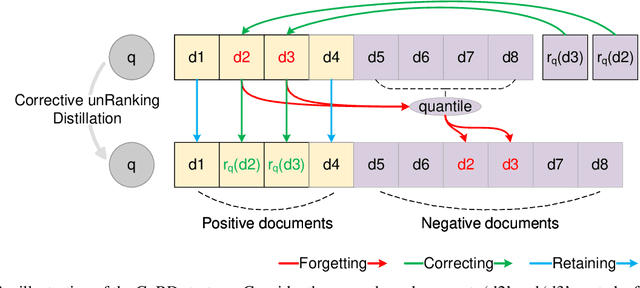
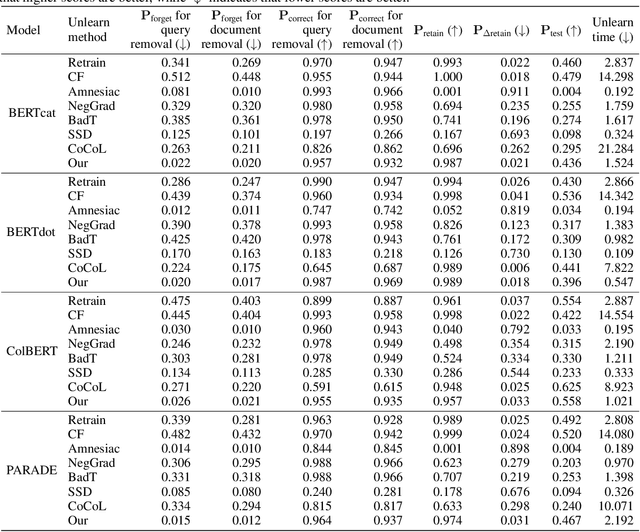
Machine unlearning in neural information retrieval (IR) systems requires removing specific data whilst maintaining model performance. Applying existing machine unlearning methods to IR may compromise retrieval effectiveness or inadvertently expose unlearning actions due to the removal of particular items from the retrieved results presented to users. We formalise corrective unranking, which extends machine unlearning in (neural) IR context by integrating substitute documents to preserve ranking integrity, and propose a novel teacher-student framework, Corrective unRanking Distillation (CuRD), for this task. CuRD (1) facilitates forgetting by adjusting the (trained) neural IR model such that its output relevance scores of to-be-forgotten samples mimic those of low-ranking, non-retrievable samples; (2) enables correction by fine-tuning the relevance scores for the substitute samples to match those of corresponding to-be-forgotten samples closely; (3) seeks to preserve performance on samples that are not targeted for forgetting. We evaluate CuRD on four neural IR models (BERTcat, BERTdot, ColBERT, PARADE) using MS MARCO and TREC CAR datasets. Experiments with forget set sizes from 1 % and 20 % of the training dataset demonstrate that CuRD outperforms seven state-of-the-art baselines in terms of forgetting and correction while maintaining model retention and generalisation capabilities.
Neural Machine Unranking
Aug 09, 2024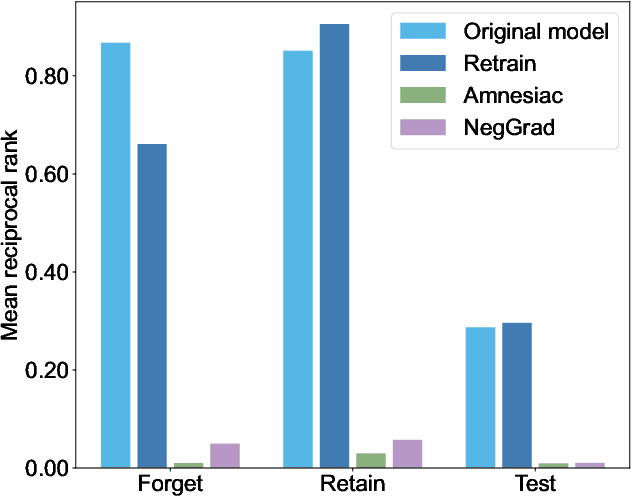
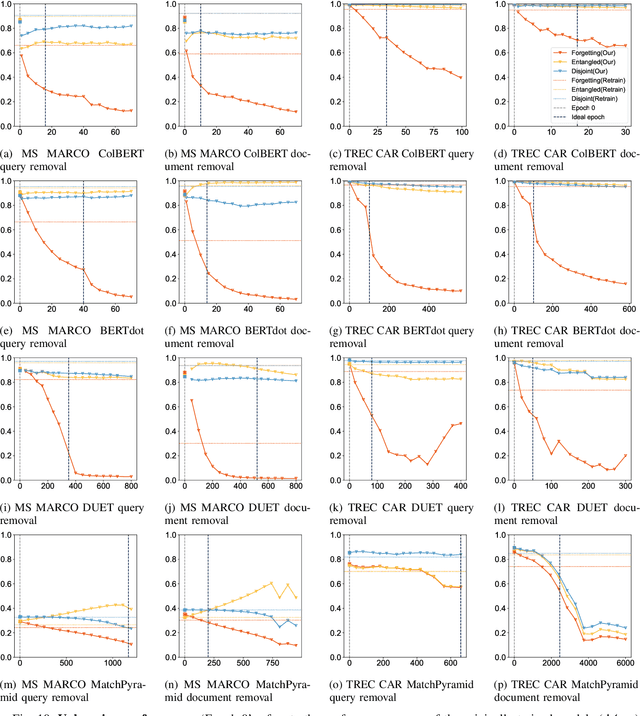

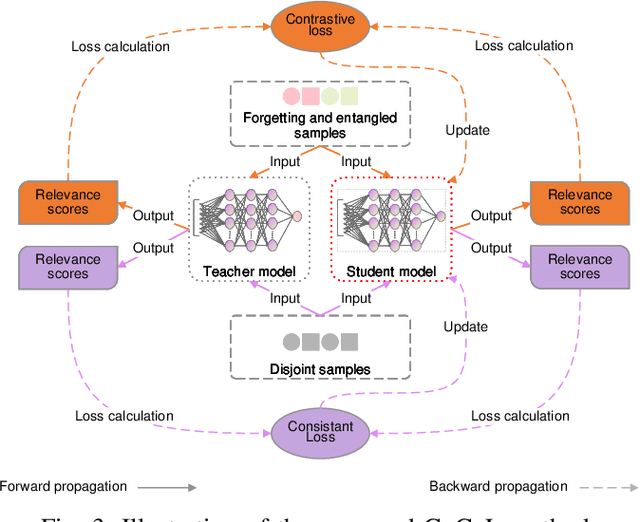
We tackle the problem of machine unlearning within neural information retrieval, termed Neural Machine UnRanking (NuMuR) for short. Many of the mainstream task- or model-agnostic approaches for machine unlearning were designed for classification tasks. First, we demonstrate that these methods perform poorly on NuMuR tasks due to the unique challenges posed by neural information retrieval. Then, we develop a methodology for NuMuR named Contrastive and Consistent Loss (CoCoL), which effectively balances the objectives of data forgetting and model performance retention. Experimental results demonstrate that CoCoL facilitates more effective and controllable data removal than existing techniques.
Particle-MALA and Particle-mGRAD: Gradient-based MCMC methods for high-dimensional state-space models
Jan 26, 2024State-of-the-art methods for Bayesian inference in state-space models are (a) conditional sequential Monte Carlo (CSMC) algorithms; (b) sophisticated 'classical' MCMC algorithms like MALA, or mGRAD from Titsias and Papaspiliopoulos (2018, arXiv:1610.09641v3 [stat.ML]). The former propose $N$ particles at each time step to exploit the model's 'decorrelation-over-time' property and thus scale favourably with the time horizon, $T$ , but break down if the dimension of the latent states, $D$, is large. The latter leverage gradient-/prior-informed local proposals to scale favourably with $D$ but exhibit sub-optimal scalability with $T$ due to a lack of model-structure exploitation. We introduce methods which combine the strengths of both approaches. The first, Particle-MALA, spreads $N$ particles locally around the current state using gradient information, thus extending MALA to $T > 1$ time steps and $N > 1$ proposals. The second, Particle-mGRAD, additionally incorporates (conditionally) Gaussian prior dynamics into the proposal, thus extending the mGRAD algorithm to $T > 1$ time steps and $N > 1$ proposals. We prove that Particle-mGRAD interpolates between CSMC and Particle-MALA, resolving the 'tuning problem' of choosing between CSMC (superior for highly informative prior dynamics) and Particle-MALA (superior for weakly informative prior dynamics). We similarly extend other 'classical' MCMC approaches like auxiliary MALA, aGRAD, and preconditioned Crank-Nicolson-Langevin (PCNL) to $T > 1$ time steps and $N > 1$ proposals. In experiments, for both highly and weakly informative prior dynamics, our methods substantially improve upon both CSMC and sophisticated 'classical' MCMC approaches.
Advancing continual lifelong learning in neural information retrieval: definition, dataset, framework, and empirical evaluation
Aug 16, 2023Continual learning refers to the capability of a machine learning model to learn and adapt to new information, without compromising its performance on previously learned tasks. Although several studies have investigated continual learning methods for information retrieval tasks, a well-defined task formulation is still lacking, and it is unclear how typical learning strategies perform in this context. To address this challenge, a systematic task formulation of continual neural information retrieval is presented, along with a multiple-topic dataset that simulates continuous information retrieval. A comprehensive continual neural information retrieval framework consisting of typical retrieval models and continual learning strategies is then proposed. Empirical evaluations illustrate that the proposed framework can successfully prevent catastrophic forgetting in neural information retrieval and enhance performance on previously learned tasks. The results indicate that embedding-based retrieval models experience a decline in their continual learning performance as the topic shift distance and dataset volume of new tasks increase. In contrast, pretraining-based models do not show any such correlation. Adopting suitable learning strategies can mitigate the effects of topic shift and data augmentation.
Morphological Image Analysis and Feature Extraction for Reasoning with AI-based Defect Detection and Classification Models
Jul 24, 2023
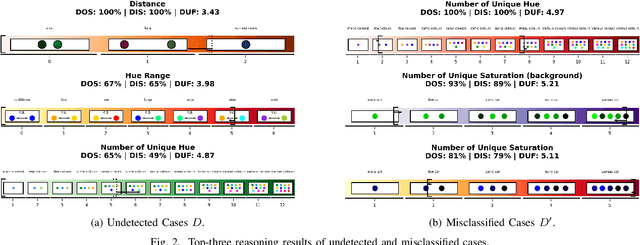


As the use of artificial intelligent (AI) models becomes more prevalent in industries such as engineering and manufacturing, it is essential that these models provide transparent reasoning behind their predictions. This paper proposes the AI-Reasoner, which extracts the morphological characteristics of defects (DefChars) from images and utilises decision trees to reason with the DefChar values. Thereafter, the AI-Reasoner exports visualisations (i.e. charts) and textual explanations to provide insights into outputs made by masked-based defect detection and classification models. It also provides effective mitigation strategies to enhance data pre-processing and overall model performance. The AI-Reasoner was tested on explaining the outputs of an IE Mask R-CNN model using a set of 366 images containing defects. The results demonstrated its effectiveness in explaining the IE Mask R-CNN model's predictions. Overall, the proposed AI-Reasoner provides a solution for improving the performance of AI models in industrial applications that require defect analysis.
Identifying Early Help Referrals For Local Authorities With Machine Learning And Bias Analysis
Jul 13, 2023Local authorities in England, such as Leicestershire County Council (LCC), provide Early Help services that can be offered at any point in a young person's life when they experience difficulties that cannot be supported by universal services alone, such as schools. This paper investigates the utilisation of machine learning (ML) to assist experts in identifying families that may need to be referred for Early Help assessment and support. LCC provided an anonymised dataset comprising 14360 records of young people under the age of 18. The dataset was pre-processed, machine learning models were build, and experiments were conducted to validate and test the performance of the models. Bias mitigation techniques were applied to improve the fairness of these models. During testing, while the models demonstrated the capability to identify young people requiring intervention or early help, they also produced a significant number of false positives, especially when constructed with imbalanced data, incorrectly identifying individuals who most likely did not need an Early Help referral. This paper empirically explores the suitability of data-driven ML models for identifying young people who may require Early Help services and discusses their appropriateness and limitations for this task.
On the relationship between variational inference and adaptive importance sampling
Jul 24, 2019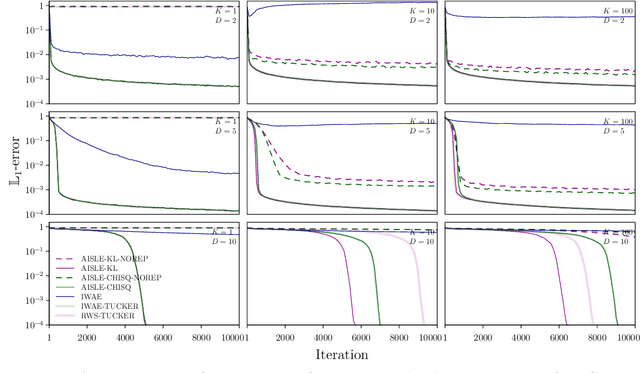
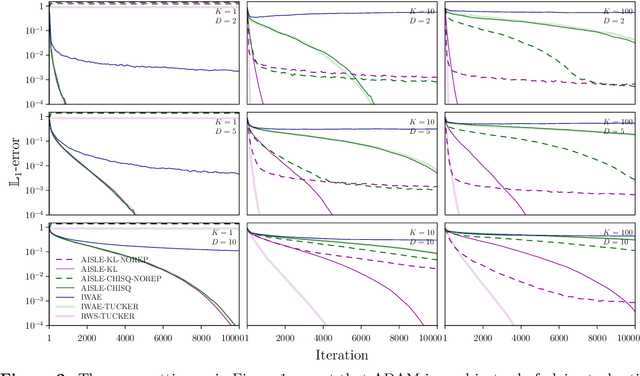
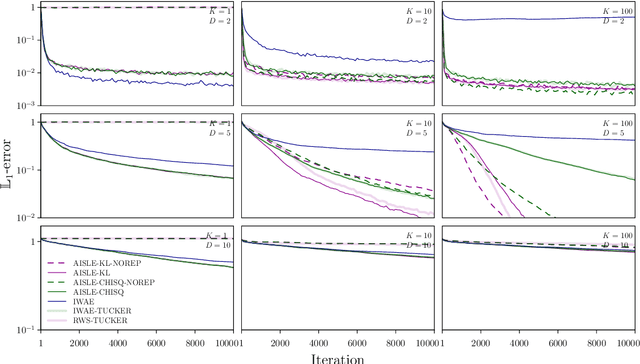
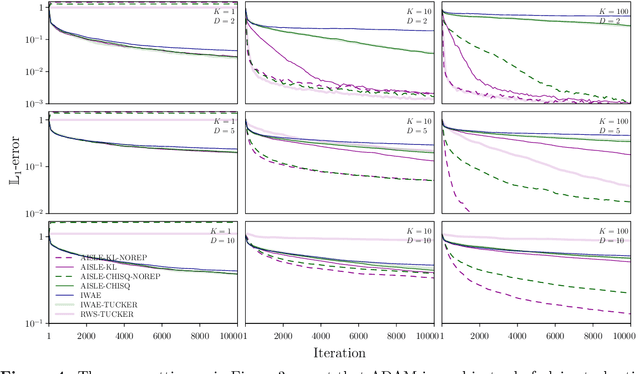
The importance weighted autoencoder (IWAE) (Burda et al., 2016) and reweighted wake-sleep (RWS) algorithm (Bornschein and Bengio, 2015) are popular approaches which employ multiple samples to achieve bias reductions compared to standard variational methods. However, their relationship has hitherto been unclear. We introduce a simple, unified framework for multi-sample variational inference termed adaptive importance sampling for learning (AISLE) and show that it admits IWAE and RWS as special cases. Through a principled application of a variance-reduction technique from Tucker et al. (2019), we also show that the sticking-the-landing (STL) gradient from Roeder et al. (2017), which previously lacked theoretical justification, can be recovered as a special case of RWS (and hence of AISLE). In particular, this indicates that the breakdown of RWS -- but not of STL -- observed in Tucker et al. (2019) may not be attributable to the lack of a joint objective for the generative-model and inference-network parameters as previously conjectured. Finally, we argue that our adaptive-importance-sampling interpretation of variational inference leads to more natural and principled extensions to sequential Monte Carlo methods than the IWAE-type multi-sample objective interpretation.