 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSUPREME: A Multi-GPU Framework for Reproducible Image Unlearning Method Evaluation
May 29, 2026Machine unlearning removes the influence of specific training data from a trained model without retraining it from scratch. Evaluating an unlearning method requires repeating training, unlearning, and evaluation across multiple seeds, which is computationally expensive. To our knowledge, existing image classification unlearning frameworks run on a single GPU, which limits how many seeds can be evaluated in reasonable time. We introduce SUPREME, an open-source framework that distributes these stages across multiple GPUs. SUPREME makes three contributions: a registry-based design for adding new methods, metrics, models, and scenarios; a multi-GPU architecture supporting multiple accelerators and precision modes; and a demonstration on Pins Face Recognition using ResNet18 and ViT under full-class and random-sample unlearning across ten seeds. The framework is available at https://github.com/pedroandreou/supreme-unlearning.
RULER: Representation-Level Verification of Machine Unlearning
May 26, 2026Machine unlearning aims to remove the influence of specific training records from a deployed model without retraining from scratch. Current protocols verify this at the output level through membership inference, retain accuracy, and forget-set accuracy, but a model can satisfy all three whilst still encoding forgotten records in its intermediate representations. We introduce RULER, a set of representation-level verification metrics. The oracle-comparative metric M2 measures whether forget-set records occupy the same representational position as in a model retrained without them. The oracle-free metric M4 detects residuals from the unlearned model's internal similarity structure alone, without retraining. Four approximate unlearning methods all pass output-level evaluation, yet under a linear mixed-effects model M2 detects significant residuals in 10 of 12 conditions (p<0.05), with effect sizes growing as the forget fraction increases. A fifth method, Bad Teacher, shows the same residuals despite a different forgetting mechanism. M4 acts as a pre-unlearning diagnostic across tabular, image, clinical text, and face-identity settings: it detects identity-level memorisation in face recognition models where no tested method fully erases the signal.
A Framework for Evaluating Faithfulness in Explainable AI for Machine Anomalous Sound Detection Using Frequency-Band Perturbation
Jan 26, 2026Explainable AI (XAI) is commonly applied to anomalous sound detection (ASD) models to identify which time-frequency regions of an audio signal contribute to an anomaly decision. However, most audio explanations rely on qualitative inspection of saliency maps, leaving open the question of whether these attributions accurately reflect the spectral cues the model uses. In this work, we introduce a new quantitative framework for evaluating XAI faithfulness in machine-sound analysis by directly linking attribution relevance to model behaviour through systematic frequency-band removal. This approach provides an objective measure of whether an XAI method for machine ASD correctly identifies frequency regions that influence an ASD model's predictions. By using four widely adopted methods, namely Integrated Gradients, Occlusion, Grad-CAM and SmoothGrad, we show that XAI techniques differ in reliability, with Occlusion demonstrating the strongest alignment with true model sensitivity and gradient-+based methods often failing to accurately capture spectral dependencies. The proposed framework offers a reproducible way to benchmark audio explanations and enables more trustworthy interpretation of spectrogram-based ASD systems.
Image Complexity-Aware Adaptive Retrieval for Efficient Vision-Language Models
Dec 17, 2025Vision transformers in vision-language models apply uniform computational effort across all images, expending 175.33 GFLOPs (ViT-L/14) whether analysing a straightforward product photograph or a complex street scene. We propose ICAR (Image Complexity-Aware Retrieval), which enables vision transformers to use less compute for simple images whilst processing complex images through their full network depth. The key challenge is maintaining cross-modal alignment: embeddings from different processing depths must remain compatible for text matching. ICAR solves this through dual-path training that produces compatible embeddings from both reduced-compute and full-compute processing. This maintains compatibility between image representations and text embeddings in the same semantic space, whether an image exits early or processes fully. Unlike existing two-stage approaches that require expensive reranking, ICAR enables direct image-text matching without additional overhead. To determine how much compute to use, we develop ConvNeXt-IC, which treats image complexity assessment as a classification task. By applying modern classifier backbones rather than specialised architectures, ConvNeXt-IC achieves state-of-the-art performance with 0.959 correlation with human judgement (Pearson) and 4.4x speedup. Evaluated on standard benchmarks augmented with real-world web data, ICAR achieves 20% practical speedup while maintaining category-level performance and 95% of instance-level performance, enabling sustainable scaling of vision-language systems.
On the limitation of evaluating machine unlearning using only a single training seed
Oct 30, 2025Machine unlearning (MU) aims to remove the influence of certain data points from a trained model without costly retraining. Most practical MU algorithms are only approximate and their performance can only be assessed empirically. Care must therefore be taken to make empirical comparisons as representative as possible. A common practice is to run the MU algorithm multiple times independently starting from the same trained model. In this work, we demonstrate that this practice can give highly non-representative results because -- even for the same architecture and same dataset -- some MU methods can be highly sensitive to the choice of random number seed used for model training. We therefore recommend that empirical comphttps://info.arxiv.org/help/prep#commentsarisons of MU algorithms should also reflect the variability across different model training seeds.
Neural Corrective Machine Unranking
Nov 13, 2024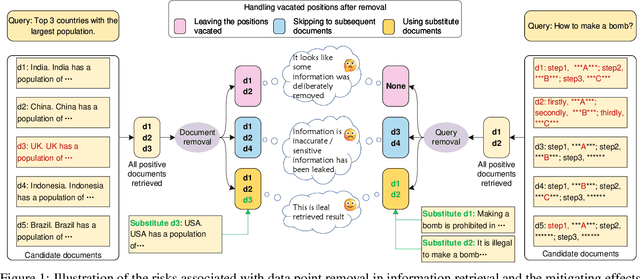
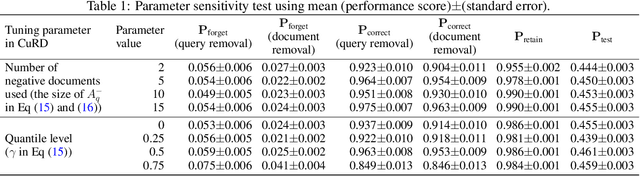
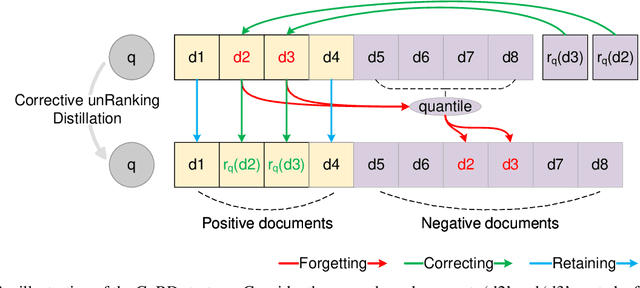
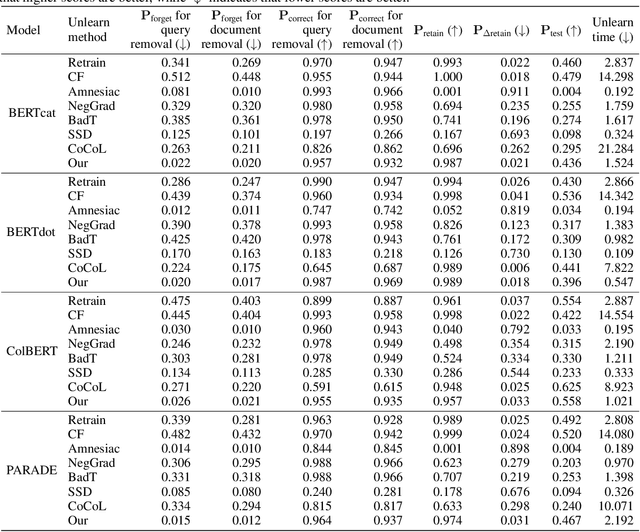
Machine unlearning in neural information retrieval (IR) systems requires removing specific data whilst maintaining model performance. Applying existing machine unlearning methods to IR may compromise retrieval effectiveness or inadvertently expose unlearning actions due to the removal of particular items from the retrieved results presented to users. We formalise corrective unranking, which extends machine unlearning in (neural) IR context by integrating substitute documents to preserve ranking integrity, and propose a novel teacher-student framework, Corrective unRanking Distillation (CuRD), for this task. CuRD (1) facilitates forgetting by adjusting the (trained) neural IR model such that its output relevance scores of to-be-forgotten samples mimic those of low-ranking, non-retrievable samples; (2) enables correction by fine-tuning the relevance scores for the substitute samples to match those of corresponding to-be-forgotten samples closely; (3) seeks to preserve performance on samples that are not targeted for forgetting. We evaluate CuRD on four neural IR models (BERTcat, BERTdot, ColBERT, PARADE) using MS MARCO and TREC CAR datasets. Experiments with forget set sizes from 1 % and 20 % of the training dataset demonstrate that CuRD outperforms seven state-of-the-art baselines in terms of forgetting and correction while maintaining model retention and generalisation capabilities.
Neural Machine Unranking
Aug 09, 2024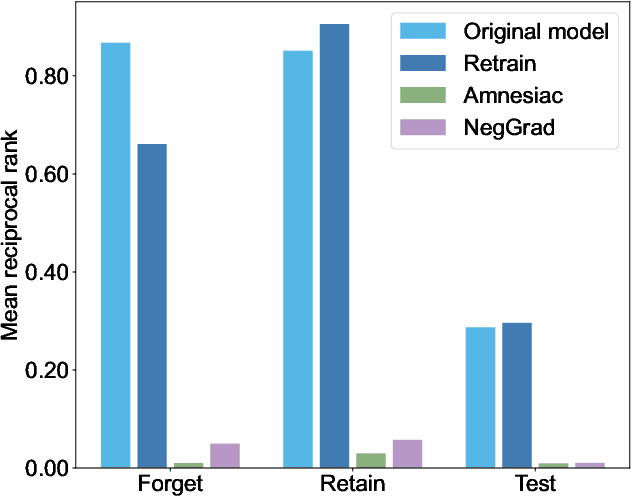
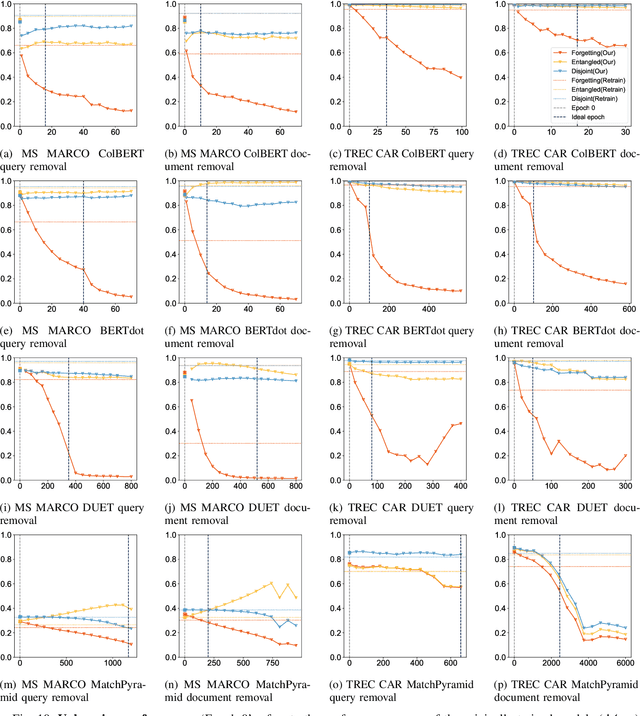

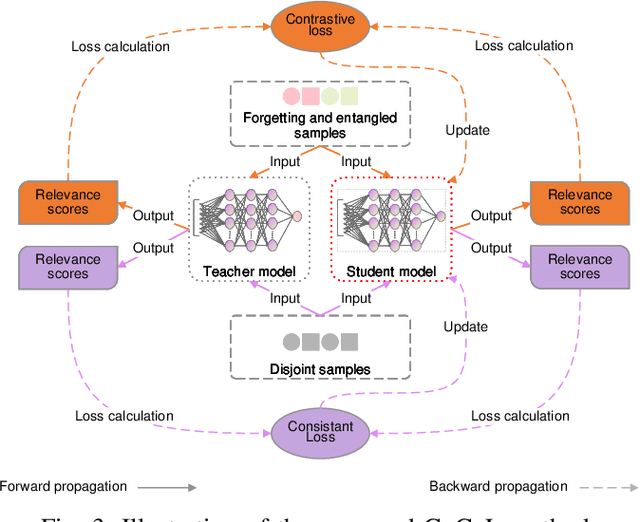
We tackle the problem of machine unlearning within neural information retrieval, termed Neural Machine UnRanking (NuMuR) for short. Many of the mainstream task- or model-agnostic approaches for machine unlearning were designed for classification tasks. First, we demonstrate that these methods perform poorly on NuMuR tasks due to the unique challenges posed by neural information retrieval. Then, we develop a methodology for NuMuR named Contrastive and Consistent Loss (CoCoL), which effectively balances the objectives of data forgetting and model performance retention. Experimental results demonstrate that CoCoL facilitates more effective and controllable data removal than existing techniques.
FiCo-ITR: bridging fine-grained and coarse-grained image-text retrieval for comparative performance analysis
Jul 29, 2024



In the field of Image-Text Retrieval (ITR), recent advancements have leveraged large-scale Vision-Language Pretraining (VLP) for Fine-Grained (FG) instance-level retrieval, achieving high accuracy at the cost of increased computational complexity. For Coarse-Grained (CG) category-level retrieval, prominent approaches employ Cross-Modal Hashing (CMH) to prioritise efficiency, albeit at the cost of retrieval performance. Due to differences in methodologies, FG and CG models are rarely compared directly within evaluations in the literature, resulting in a lack of empirical data quantifying the retrieval performance-efficiency tradeoffs between the two. This paper addresses this gap by introducing the \texttt{FiCo-ITR} library, which standardises evaluation methodologies for both FG and CG models, facilitating direct comparisons. We conduct empirical evaluations of representative models from both subfields, analysing precision, recall, and computational complexity across varying data scales. Our findings offer new insights into the performance-efficiency trade-offs between recent representative FG and CG models, highlighting their respective strengths and limitations. These findings provide the foundation necessary to make more informed decisions regarding model selection for specific retrieval tasks and highlight avenues for future research into hybrid systems that leverage the strengths of both FG and CG approaches.
Intelligent Multi-Document Summarisation for Extracting Insights on Racial Inequalities from Maternity Incident Investigation Reports
Jul 11, 2024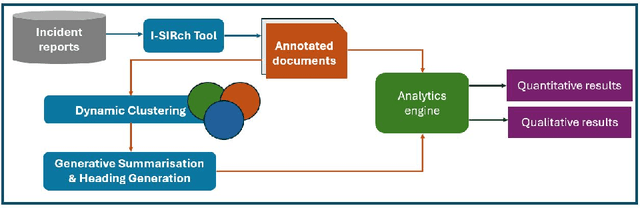
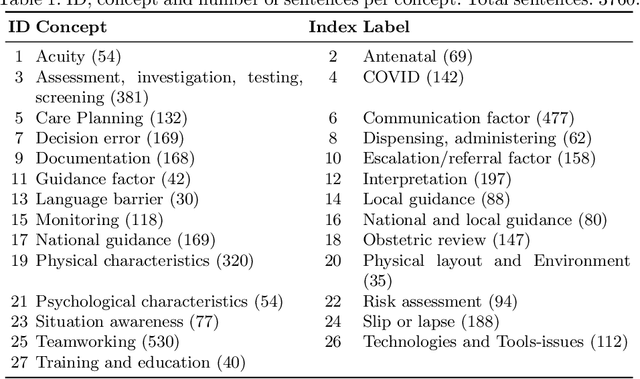
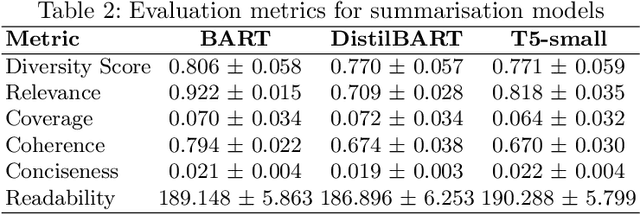
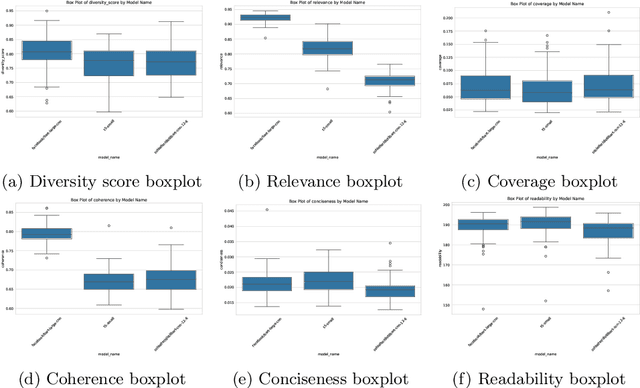
In healthcare, thousands of safety incidents occur every year, but learning from these incidents is not effectively aggregated. Analysing incident reports using AI could uncover critical insights to prevent harm by identifying recurring patterns and contributing factors. To aggregate and extract valuable information, natural language processing (NLP) and machine learning techniques can be employed to summarise and mine unstructured data, potentially surfacing systemic issues and priority areas for improvement. This paper presents I-SIRch:CS, a framework designed to facilitate the aggregation and analysis of safety incident reports while ensuring traceability throughout the process. The framework integrates concept annotation using the Safety Intelligence Research (SIRch) taxonomy with clustering, summarisation, and analysis capabilities. Utilising a dataset of 188 anonymised maternity investigation reports annotated with 27 SIRch human factors concepts, I-SIRch:CS groups the annotated sentences into clusters using sentence embeddings and k-means clustering, maintaining traceability via file and sentence IDs. Summaries are generated for each cluster using offline state-of-the-art abstractive summarisation models (BART, DistilBART, T5), which are evaluated and compared using metrics assessing summary quality attributes. The generated summaries are linked back to the original file and sentence IDs, ensuring traceability and allowing for verification of the summarised information. Results demonstrate BART's strengths in creating informative and concise summaries.
Unveiling Disparities in Maternity Care: A Topic Modelling Approach to Analysing Maternity Incident Investigation Reports
Jul 11, 2024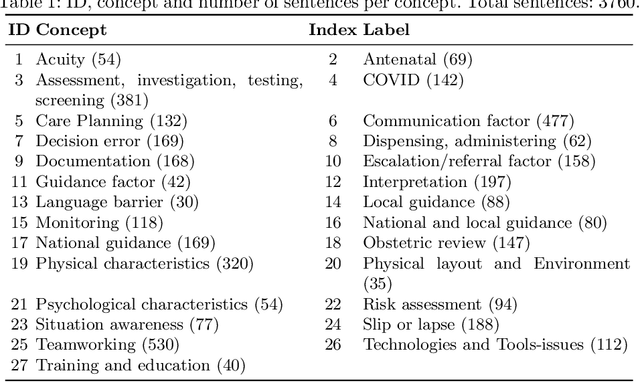
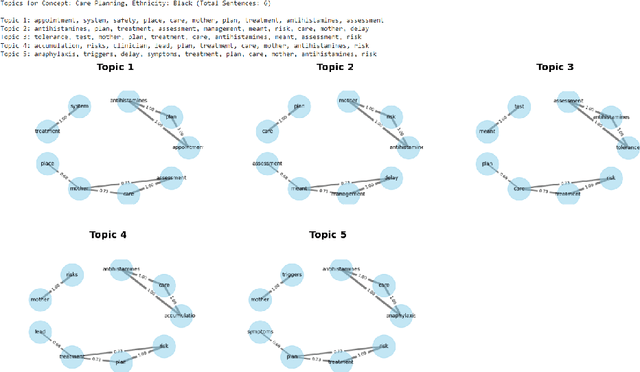
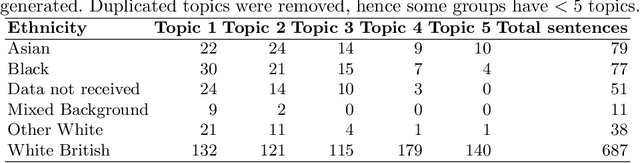
This study applies Natural Language Processing techniques, including Latent Dirichlet Allocation, to analyse anonymised maternity incident investigation reports from the Healthcare Safety Investigation Branch. The reports underwent preprocessing, annotation using the Safety Intelligence Research taxonomy, and topic modelling to uncover prevalent topics and detect differences in maternity care across ethnic groups. A combination of offline and online methods was utilised to ensure data protection whilst enabling advanced analysis, with offline processing for sensitive data and online processing for non-sensitive data using the `Claude 3 Opus' language model. Interactive topic analysis and semantic network visualisation were employed to extract and display thematic topics and visualise semantic relationships among keywords. The analysis revealed disparities in care among different ethnic groups, with distinct focus areas for the Black, Asian, and White British ethnic groups. The study demonstrates the effectiveness of topic modelling and NLP techniques in analysing maternity incident investigation reports and highlighting disparities in care. The findings emphasise the crucial role of advanced data analysis in improving maternity care quality and equity.