Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Machine Unranking
Paper and Code
Aug 09, 2024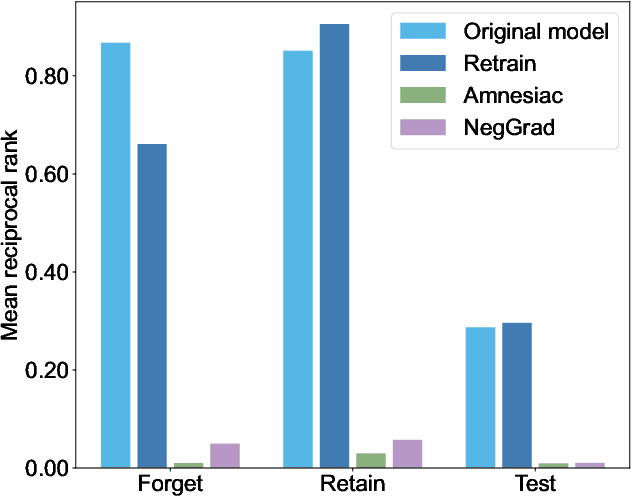
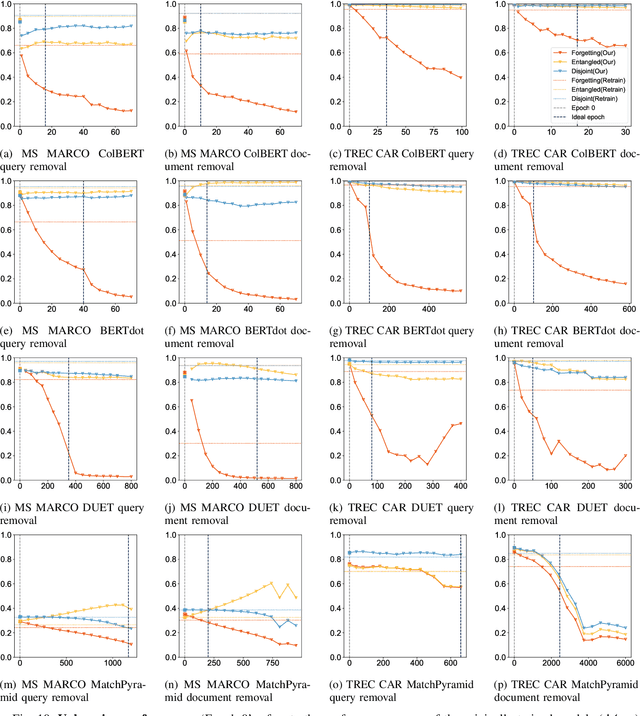

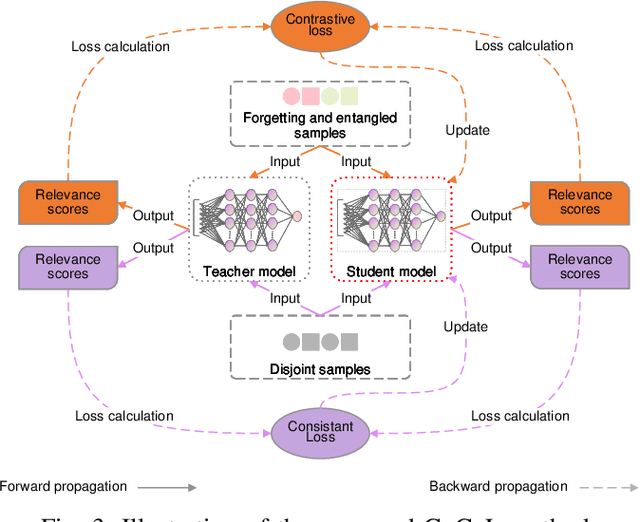
We tackle the problem of machine unlearning within neural information retrieval, termed Neural Machine UnRanking (NuMuR) for short. Many of the mainstream task- or model-agnostic approaches for machine unlearning were designed for classification tasks. First, we demonstrate that these methods perform poorly on NuMuR tasks due to the unique challenges posed by neural information retrieval. Then, we develop a methodology for NuMuR named Contrastive and Consistent Loss (CoCoL), which effectively balances the objectives of data forgetting and model performance retention. Experimental results demonstrate that CoCoL facilitates more effective and controllable data removal than existing techniques.
View paper on