 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Theory to Application: Fine-Tuning Large EEG Model with Real-World Stress Data
May 29, 2025



Recent advancements in Large Language Models have inspired the development of foundation models across various domains. In this study, we evaluate the efficacy of Large EEG Models (LEMs) by fine-tuning LaBraM, a state-of-the-art foundation EEG model, on a real-world stress classification dataset collected in a graduate classroom. Unlike previous studies that primarily evaluate LEMs using data from controlled clinical settings, our work assesses their applicability to real-world environments. We train a binary classifier that distinguishes between normal and elevated stress states using resting-state EEG data recorded from 18 graduate students during a class session. The best-performing fine-tuned model achieves a balanced accuracy of 90.47% with a 5-second window, significantly outperforming traditional stress classifiers in both accuracy and inference efficiency. We further evaluate the robustness of the fine-tuned LEM under random data shuffling and reduced channel counts. These results demonstrate the capability of LEMs to effectively process real-world EEG data and highlight their potential to revolutionize brain-computer interface applications by shifting the focus from model-centric to data-centric design.
ArcMMLU: A Library and Information Science Benchmark for Large Language Models
Nov 30, 2023



In light of the rapidly evolving capabilities of large language models (LLMs), it becomes imperative to develop rigorous domain-specific evaluation benchmarks to accurately assess their capabilities. In response to this need, this paper introduces ArcMMLU, a specialized benchmark tailored for the Library & Information Science (LIS) domain in Chinese. This benchmark aims to measure the knowledge and reasoning capability of LLMs within four key sub-domains: Archival Science, Data Science, Library Science, and Information Science. Following the format of MMLU/CMMLU, we collected over 6,000 high-quality questions for the compilation of ArcMMLU. This extensive compilation can reflect the diverse nature of the LIS domain and offer a robust foundation for LLM evaluation. Our comprehensive evaluation reveals that while most mainstream LLMs achieve an average accuracy rate above 50% on ArcMMLU, there remains a notable performance gap, suggesting substantial headroom for refinement in LLM capabilities within the LIS domain. Further analysis explores the effectiveness of few-shot examples on model performance and highlights challenging questions where models consistently underperform, providing valuable insights for targeted improvements. ArcMMLU fills a critical gap in LLM evaluations within the Chinese LIS domain and paves the way for future development of LLMs tailored to this specialized area.
ArcGPT: A Large Language Model Tailored for Real-world Archival Applications
Jul 27, 2023



Archives play a crucial role in preserving information and knowledge, and the exponential growth of such data necessitates efficient and automated tools for managing and utilizing archive information resources. Archival applications involve managing massive data that are challenging to process and analyze. Although LLMs have made remarkable progress in diverse domains, there are no publicly available archives tailored LLM. Addressing this gap, we introduce ArcGPT, to our knowledge, the first general-purpose LLM tailored to the archival field. To enhance model performance on real-world archival tasks, ArcGPT has been pre-trained on massive and extensive archival domain data. Alongside ArcGPT, we release AMBLE, a benchmark comprising four real-world archival tasks. Evaluation on AMBLE shows that ArcGPT outperforms existing state-of-the-art models, marking a substantial step forward in effective archival data management. Ultimately, ArcGPT aims to better serve the archival community, aiding archivists in their crucial role of preserving and harnessing our collective information and knowledge.
BatGPT: A Bidirectional Autoregessive Talker from Generative Pre-trained Transformer
Jul 01, 2023
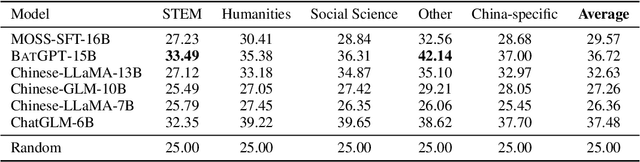

BatGPT is a large-scale language model designed and trained jointly by Wuhan University and Shanghai Jiao Tong University. It is capable of generating highly natural and fluent text in response to various types of input, including text prompts, images, and audio. In the modeling level, we employ a bidirectional autoregressive architecture that allows the model to efficiently capture the complex dependencies of natural language, making it highly effective in tasks such as language generation, dialog systems, and question answering. Moreover, the bidirectional autoregressive modeling not only operates from left to right but also from right to left, effectively reducing fixed memory effects and alleviating model hallucinations. In the training aspect, we propose a novel parameter expansion method for leveraging the pre-training of smaller models and employ reinforcement learning from both AI and human feedback, aimed at improving the model's alignment performance. Overall, these approaches significantly improve the effectiveness of BatGPT, and the model can be utilized for a wide range of natural language applications.