 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep-ultraviolet ptychographic pocket-scope (DART): mesoscale lensless molecular imaging with label-free spectroscopic contrast
Nov 08, 2025The mesoscale characterization of biological specimens has traditionally required compromises between resolution, field-of-view, depth-of-field, and molecular specificity, with most approaches relying on external labels. Here we present the Deep-ultrAviolet ptychogRaphic pockeT-scope (DART), a handheld platform that transforms label-free molecular imaging through intrinsic deep-ultraviolet spectroscopic contrast. By leveraging biomolecules' natural absorption fingerprints and combining them with lensless ptychographic microscopy, DART resolves down to 308-nm linewidths across centimeter-scale areas while maintaining millimeter-scale depth-of-field. The system's virtual error-bin methodology effectively eliminates artifacts from limited temporal coherence and other optical imperfections, enabling high-fidelity molecular imaging without lenses. Through differential spectroscopic imaging at deep-ultraviolet wavelengths, DART quantitatively maps nucleic acid and protein distributions with femtogram sensitivity, providing an intrinsic basis for explainable virtual staining. We demonstrate DART's capabilities through molecular imaging of tissue sections, cytopathology specimens, blood cells, and neural populations, revealing detailed molecular contrast without external labels. The combination of high-resolution molecular mapping and broad mesoscale imaging in a portable platform opens new possibilities from rapid clinical diagnostics, tissue analysis, to biological characterization in space exploration.
Video-rate gigapixel ptychography via space-time neural field representations
Nov 08, 2025Achieving gigapixel space-bandwidth products (SBP) at video rates represents a fundamental challenge in imaging science. Here we demonstrate video-rate ptychography that overcomes this barrier by exploiting spatiotemporal correlations through neural field representations. Our approach factorizes the space-time volume into low-rank spatial and temporal features, transforming SBP scaling from sequential measurements to efficient correlation extraction. The architecture employs dual networks for decoding real and imaginary field components, avoiding phase-wrapping discontinuities plagued in amplitude-phase representations. A gradient-domain loss on spatial derivatives ensures robust convergence. We demonstrate video-rate gigapixel imaging with centimeter-scale coverage while resolving 308-nm linewidths. Validations span from monitoring sample dynamics of crystals, bacteria, stem cells, microneedle to characterizing time-varying probes in extreme ultraviolet experiments, demonstrating versatility across wavelengths. By transforming temporal variations from a constraint into exploitable correlations, we establish that gigapixel video is tractable with single-sensor measurements, making ptychography a high-throughput sensing tool for monitoring mesoscale dynamics without lenses.
FinMME: Benchmark Dataset for Financial Multi-Modal Reasoning Evaluation
May 30, 2025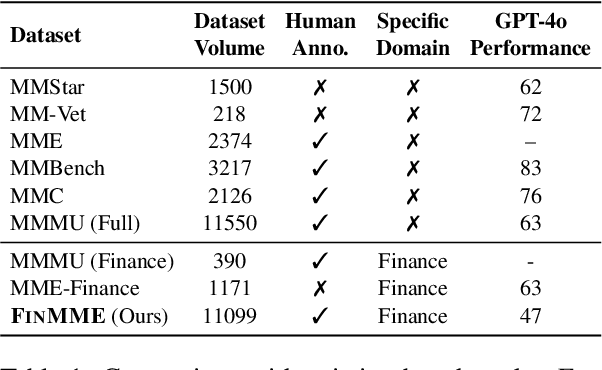
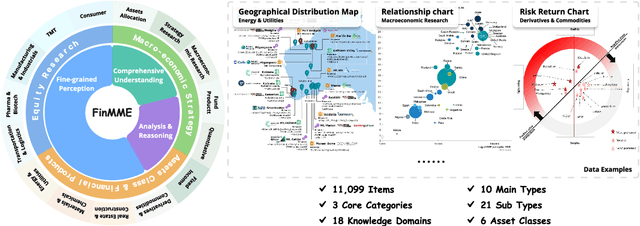
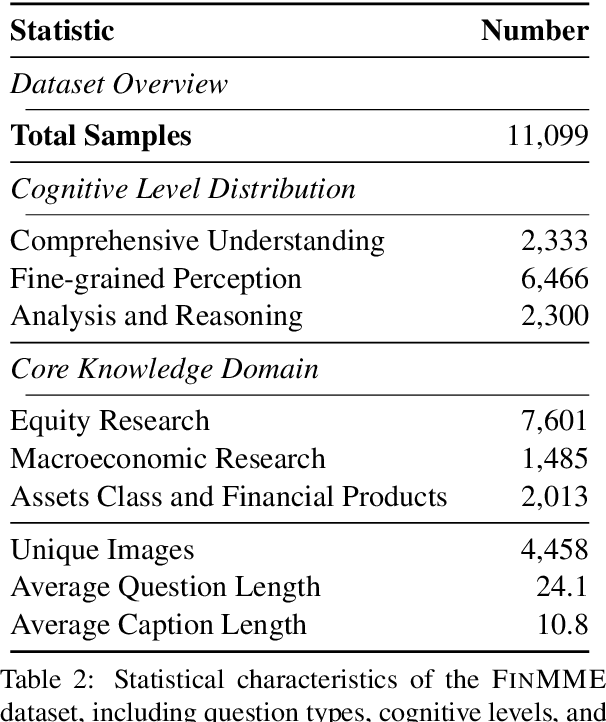
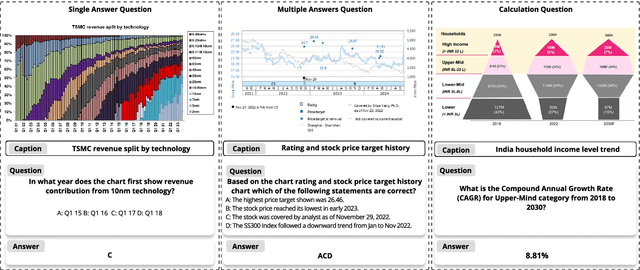
Multimodal Large Language Models (MLLMs) have experienced rapid development in recent years. However, in the financial domain, there is a notable lack of effective and specialized multimodal evaluation datasets. To advance the development of MLLMs in the finance domain, we introduce FinMME, encompassing more than 11,000 high-quality financial research samples across 18 financial domains and 6 asset classes, featuring 10 major chart types and 21 subtypes. We ensure data quality through 20 annotators and carefully designed validation mechanisms. Additionally, we develop FinScore, an evaluation system incorporating hallucination penalties and multi-dimensional capability assessment to provide an unbiased evaluation. Extensive experimental results demonstrate that even state-of-the-art models like GPT-4o exhibit unsatisfactory performance on FinMME, highlighting its challenging nature. The benchmark exhibits high robustness with prediction variations under different prompts remaining below 1%, demonstrating superior reliability compared to existing datasets. Our dataset and evaluation protocol are available at https://huggingface.co/datasets/luojunyu/FinMME and https://github.com/luo-junyu/FinMME.
Empowering 1000 tokens/second on-device LLM prefilling with mllm-NPU
Jul 08, 2024



On-device large language models (LLMs) are catalyzing novel mobile applications such as UI task automation and personalized email auto-reply, without giving away users' private data. However, on-device LLMs still suffer from unacceptably long inference latency, especially the time to first token (prefill stage) due to the need of long context for accurate, personalized content generation, as well as the lack of parallel computing capacity of mobile CPU/GPU. To enable practical on-device LLM, we present mllm-NPU, the first-of-its-kind LLM inference system that efficiently leverages on-device Neural Processing Unit (NPU) offloading. Essentially, mllm-NPU is an algorithm-system co-design that tackles a few semantic gaps between the LLM architecture and contemporary NPU design. Specifically, it re-constructs the prompt and model in three levels: (1) At prompt level, it divides variable-length prompts into multiple fixed-sized chunks while maintaining data dependencies; (2) At tensor level, it identifies and extracts significant outliers to run on the CPU/GPU in parallel with minimal overhead; (3) At block level, it schedules Transformer blocks in an out-of-order manner to the CPU/GPU and NPU based on their hardware affinity and sensitivity to accuracy. Compared to competitive baselines, mllm-NPU achieves 22.4x faster prefill speed and 30.7x energy savings on average, and up to 32.8x speedup in an end-to-end real-world application. For the first time, mllm-NPU achieves more than 1,000 tokens/sec prefilling for a billion-sized model (Qwen1.5-1.8B), paving the way towards practical on-device LLM.
History Matters: Temporal Knowledge Editing in Large Language Model
Dec 14, 2023



The imperative task of revising or updating the knowledge stored within large language models arises from two distinct sources: intrinsic errors inherent in the model which should be corrected and outdated knowledge due to external shifts in the real world which should be updated. Prevailing efforts in model editing conflate these two distinct categories of edits arising from distinct reasons and directly modify the original knowledge in models into new knowledge. However, we argue that preserving the model's original knowledge remains pertinent. Specifically, if a model's knowledge becomes outdated due to evolving worldly dynamics, it should retain recollection of the historical knowledge while integrating the newfound knowledge. In this work, we introduce the task of Temporal Knowledge Editing (TKE) and establish a benchmark AToKe (Assessment of TempOral Knowledge Editing) to evaluate current model editing methods. We find that while existing model editing methods are effective at making models remember new knowledge, the edited model catastrophically forgets historical knowledge. To address this gap, we propose a simple and general framework termed Multi-Editing with Time Objective (METO) for enhancing existing editing models, which edits both historical and new knowledge concurrently and optimizes the model's prediction for the time of each fact. Our assessments demonstrate that while AToKe is still difficult, METO maintains the effectiveness of learning new knowledge and meanwhile substantially improves the performance of edited models on utilizing historical knowledge.
ArcMMLU: A Library and Information Science Benchmark for Large Language Models
Nov 30, 2023



In light of the rapidly evolving capabilities of large language models (LLMs), it becomes imperative to develop rigorous domain-specific evaluation benchmarks to accurately assess their capabilities. In response to this need, this paper introduces ArcMMLU, a specialized benchmark tailored for the Library & Information Science (LIS) domain in Chinese. This benchmark aims to measure the knowledge and reasoning capability of LLMs within four key sub-domains: Archival Science, Data Science, Library Science, and Information Science. Following the format of MMLU/CMMLU, we collected over 6,000 high-quality questions for the compilation of ArcMMLU. This extensive compilation can reflect the diverse nature of the LIS domain and offer a robust foundation for LLM evaluation. Our comprehensive evaluation reveals that while most mainstream LLMs achieve an average accuracy rate above 50% on ArcMMLU, there remains a notable performance gap, suggesting substantial headroom for refinement in LLM capabilities within the LIS domain. Further analysis explores the effectiveness of few-shot examples on model performance and highlights challenging questions where models consistently underperform, providing valuable insights for targeted improvements. ArcMMLU fills a critical gap in LLM evaluations within the Chinese LIS domain and paves the way for future development of LLMs tailored to this specialized area.
Iteratively reweighted least squares for robust regression via SVM and ELM
Mar 27, 2019
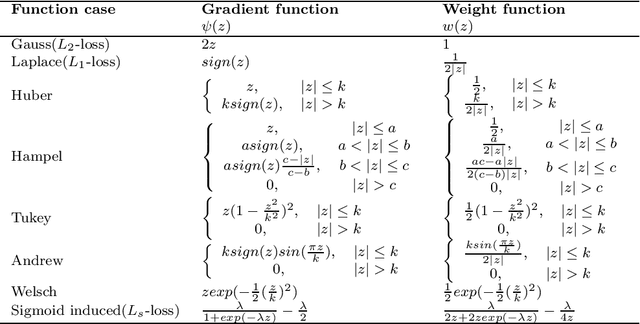

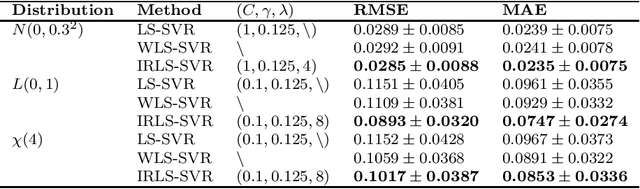
The measure of most robust machine learning methods is reweighted. To overcome the optimization difficulty of the implicitly reweighted robust methods (including modifying loss functions and objectives), we try to use a more direct method: explicitly iteratively reweighted method to handle noise (even heavy-tailed noise and outlier) robustness. In this paper, an explicitly iterative reweighted framework based on two kinds of kernel based regression algorithm (LS-SVR and ELM) is established, and a novel weight selection strategy is proposed at the same time. Combining the proposed weight function with the iteratively reweighted framework, we propose two models iteratively reweighted least squares support vector machine (IRLS-SVR) and iteratively reweighted extreme learning machine (IRLS-ELM) to implement robust regression. Different from the traditional explicitly reweighted robust methods, we carry out multiple reweighted operations in our work to further improve robustness. The convergence and approximability of the proposed algorithms are proved theoretically. Moreover, the robustness of the algorithm is analyzed in detail from many angles. Experiments on both artificial data and benchmark datasets confirm the validity of the proposed methods.