 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Text-Guided Single Image Editing for Remote Sensing Images
May 09, 2024



Artificial Intelligence Generative Content (AIGC) technologies have significantly influenced the remote sensing domain, particularly in the realm of image generation. However, remote sensing image editing, an equally vital research area, has not garnered sufficient attention. Different from text-guided editing in natural images, which relies on extensive text-image paired data for semantic correlation, the application scenarios of remote sensing image editing are often extreme, such as forest on fire, so it is difficult to obtain sufficient paired samples. At the same time, the lack of remote sensing semantics and the ambiguity of text also restrict the further application of image editing in remote sensing field. To solve above problems, this letter proposes a diffusion based method to fulfill stable and controllable remote sensing image editing with text guidance. Our method avoids the use of a large number of paired image, and can achieve good image editing results using only a single image. The quantitative evaluation system including CLIP score and subjective evaluation metrics shows that our method has better editing effect on remote sensing images than the existing image editing model.
Cartoondiff: Training-free Cartoon Image Generation with Diffusion Transformer Models
Sep 15, 2023



Image cartoonization has attracted significant interest in the field of image generation. However, most of the existing image cartoonization techniques require re-training models using images of cartoon style. In this paper, we present CartoonDiff, a novel training-free sampling approach which generates image cartoonization using diffusion transformer models. Specifically, we decompose the reverse process of diffusion models into the semantic generation phase and the detail generation phase. Furthermore, we implement the image cartoonization process by normalizing high-frequency signal of the noisy image in specific denoising steps. CartoonDiff doesn't require any additional reference images, complex model designs, or the tedious adjustment of multiple parameters. Extensive experimental results show the powerful ability of our CartoonDiff. The project page is available at: https://cartoondiff.github.io/
Background Debiased SAR Target Recognition via Causal Interventional Regularizer
Aug 30, 2023
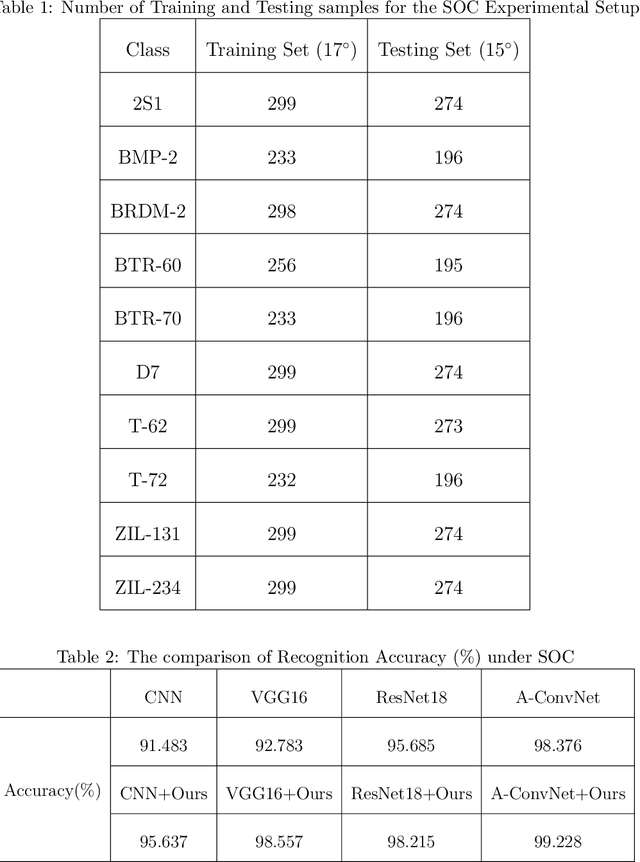
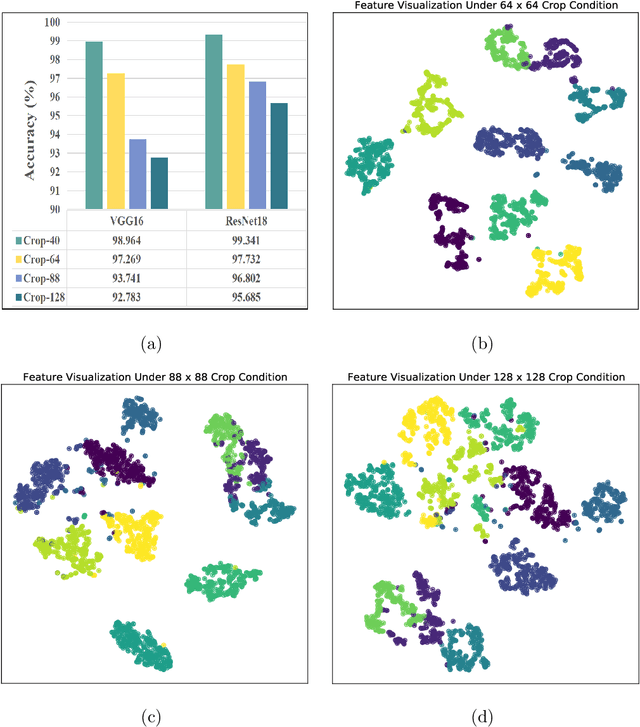
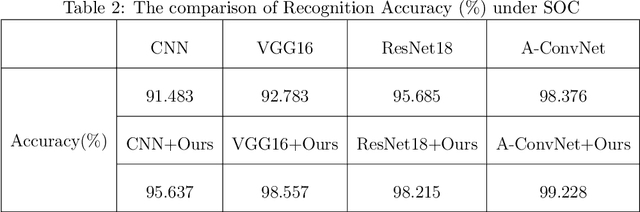
Recent studies have utilized deep learning (DL) techniques to automatically extract features from synthetic aperture radar (SAR) images, which shows great promise for enhancing the performance of SAR automatic target recognition (ATR). However, our research reveals a previously overlooked issue: SAR images to be recognized include not only the foreground (i.e., the target), but also a certain size of the background area. When a DL-model is trained exclusively on foreground data, its recognition performance is significantly superior to a model trained on original data that includes both foreground and background. This suggests that the presence of background impedes the ability of the DL-model to learn additional semantic information about the target. To address this issue, we construct a structural causal model (SCM) that incorporates the background as a confounder. Based on the constructed SCM, we propose a causal intervention based regularization method to eliminate the negative impact of background on feature semantic learning and achieve background debiased SAR-ATR. The proposed causal interventional regularizer can be integrated into any existing DL-based SAR-ATR models to mitigate the impact of background interference on the feature extraction and recognition accuracy. Experimental results on the Moving and Stationary Target Acquisition and Recognition (MSTAR) dataset indicate that the proposed method can enhance the efficiency of existing DL-based methods in a plug-and-play manner.
Learning to Sample Tasks for Meta Learning
Jul 18, 2023Through experiments on various meta-learning methods, task samplers, and few-shot learning tasks, this paper arrives at three conclusions. Firstly, there are no universal task sampling strategies to guarantee the performance of meta-learning models. Secondly, task diversity can cause the models to either underfit or overfit during training. Lastly, the generalization performance of the models are influenced by task divergence, task entropy, and task difficulty. In response to these findings, we propose a novel task sampler called Adaptive Sampler (ASr). ASr is a plug-and-play task sampler that takes task divergence, task entropy, and task difficulty to sample tasks. To optimize ASr, we rethink and propose a simple and general meta-learning algorithm. Finally, a large number of empirical experiments demonstrate the effectiveness of the proposed ASr.
A Dimensional Structure based Knowledge Distillation Method for Cross-Modal Learning
Jun 28, 2023Due to limitations in data quality, some essential visual tasks are difficult to perform independently. Introducing previously unavailable information to transfer informative dark knowledge has been a common way to solve such hard tasks. However, research on why transferred knowledge works has not been extensively explored. To address this issue, in this paper, we discover the correlation between feature discriminability and dimensional structure (DS) by analyzing and observing features extracted from simple and hard tasks. On this basis, we express DS using deep channel-wise correlation and intermediate spatial distribution, and propose a novel cross-modal knowledge distillation (CMKD) method for better supervised cross-modal learning (CML) performance. The proposed method enforces output features to be channel-wise independent and intermediate ones to be uniformly distributed, thereby learning semantically irrelevant features from the hard task to boost its accuracy. This is especially useful in specific applications where the performance gap between dual modalities is relatively large. Furthermore, we collect a real-world CML dataset to promote community development. The dataset contains more than 10,000 paired optical and radar images and is continuously being updated. Experimental results on real-world and benchmark datasets validate the effectiveness of the proposed method.
PCLNet: A Practical Way for Unsupervised Deep PolSAR Representations and Few-Shot Classification
Jun 27, 2020
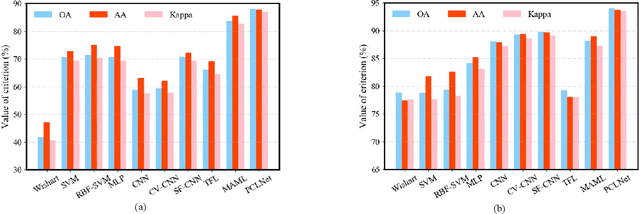
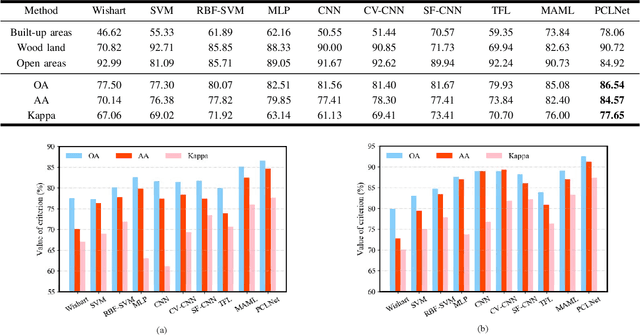
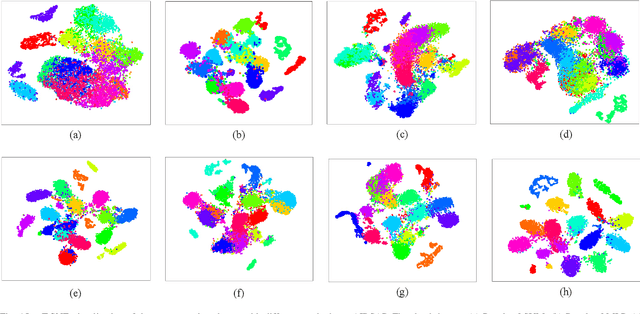
Deep learning and convolutional neural networks (CNNs) have made progress in polarimetric synthetic aperture radar (PolSAR) image classification over the past few years. However, a crucial issue has not been addressed, i.e., the requirement of CNNs for abundant labeled samples versus the insufficient human annotations of PolSAR images. It is well-known that following the supervised learning paradigm may lead to the overfitting of training data, and the lack of supervision information of PolSAR images undoubtedly aggravates this problem, which greatly affects the generalization performance of CNN-based classifiers in large-scale applications. To handle this problem, in this paper, learning transferrable representations from unlabeled PolSAR data through convolutional architectures is explored for the first time. Specifically, a PolSAR-tailored contrastive learning network (PCLNet) is proposed for unsupervised deep PolSAR representation learning and few-shot classification. Different from the utilization of optical processing methods, a diversity stimulation mechanism is constructed to narrow the application gap between optics and PolSAR. Beyond the conventional supervised methods, PCLNet develops an auxiliary pre-training phase based on the proxy objective of contrastive instance discrimination to learn useful representations from unlabeled PolSAR data. The acquired representations are transferred to the downstream task, i.e., few-shot PolSAR classification. Experiments on two widely used PolSAR benchmark datasets confirm the validity of PCLNet. Besides, this work may enlighten how to efficiently utilize the massive unlabeled PolSAR data to alleviate the greedy demands of CNN-based methods for human annotations.
Automatic Design of CNNs via Differentiable Neural Architecture Search for PolSAR Image Classification
Nov 19, 2019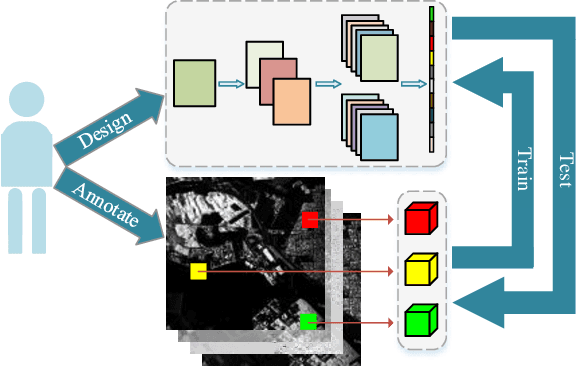
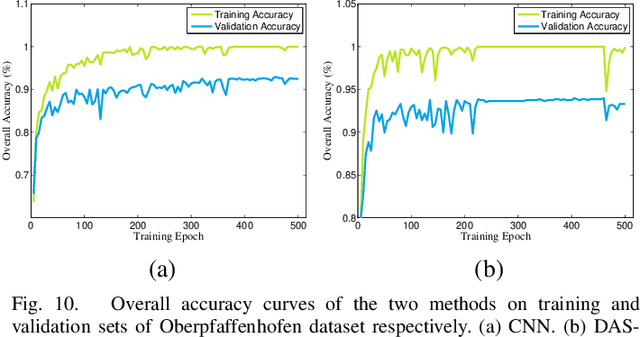

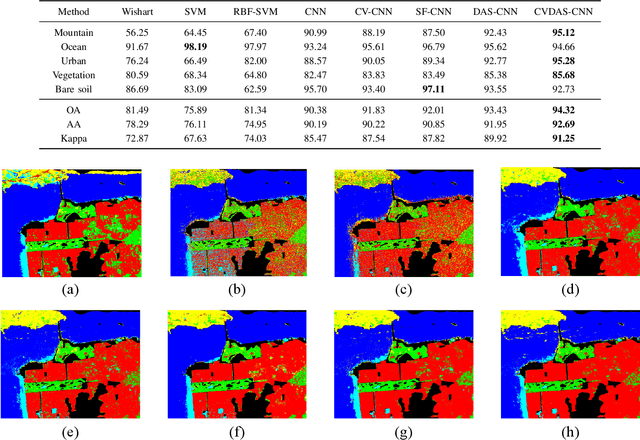
Convolutional neural networks (CNNs) have shown good performance in polarimetric synthetic aperture radar (PolSAR) image classification due to the automation of feature engineering. Excellent hand-crafted architectures of CNNs incorporated the wisdom of human experts, which is an important reason for CNN's success. However, the design of the architectures is a difficult problem, which needs a lot of professional knowledge as well as computational resources. Moreover, the architecture designed by hand might be suboptimal, because it is only one of thousands of unobserved but objective existed paths. Considering that the success of deep learning is largely due to its automation of the feature engineering process, how to design automatic architecture searching methods to replace the hand-crafted ones is an interesting topic. In this paper, we explore the application of neural architecture search (NAS) in PolSAR area for the first time. Different from the utilization of existing NAS methods, we propose a differentiable architecture search (DAS) method which is customized for PolSAR classification. The proposed DAS is equipped with a PolSAR tailored search space and an improved one-shot search strategy. By DAS, the weights parameters and architecture parameters (corresponds to the hyperparameters but not the topologies) can be optimized by stochastic gradient descent method during the training. The optimized architecture parameters should be transformed into corresponding CNN architecture and re-train to achieve high-precision PolSAR classification. In addition, complex-valued DAS is developed to take into account the characteristics of PolSAR images so as to further improve the performance. Experiments on three PolSAR benchmark datasets show that the CNNs obtained by searching have better classification performance than the hand-crafted ones.
Band Attention Convolutional Networks For Hyperspectral Image Classification
Jun 11, 2019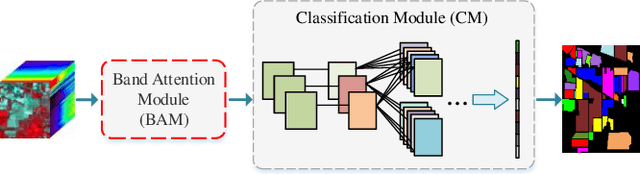
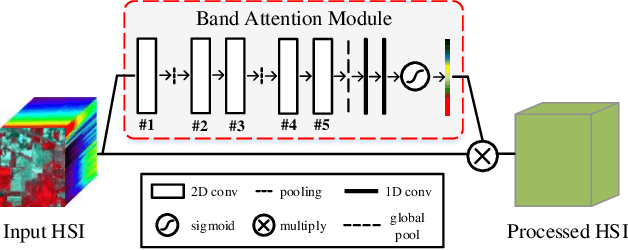
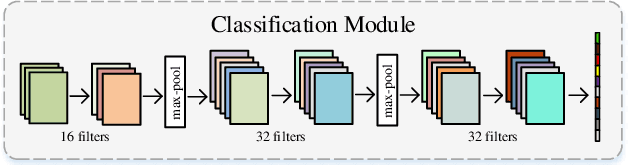

Redundancy and noise exist in the bands of hyperspectral images (HSIs). Thus, it is a good property to be able to select suitable parts from hundreds of input bands for HSIs classification methods. In this letter, a band attention module (BAM) is proposed to implement the deep learning based HSIs classification with the capacity of band selection or weighting. The proposed BAM can be seen as a plug-and-play complementary component of the existing classification networks which fully considers the adverse effects caused by the redundancy of the bands when using convolutional neural networks (CNNs) for HSIs classification. Unlike most of deep learning methods used in HSIs, the band attention module which is customized according to the characteristics of hyperspectral images is embedded in the ordinary CNNs for better performance. At the same time, unlike classical band selection or weighting methods, the proposed method achieves the end-to-end training instead of the separated stages. Experiments are carried out on two HSI benchmark datasets. Compared to some classical and advanced deep learning methods, numerical simulations under different evaluation criteria show that the proposed method have good performance. Last but not least, some advanced CNNs are combined with the proposed BAM for better performance.
Iteratively reweighted least squares for robust regression via SVM and ELM
Mar 27, 2019
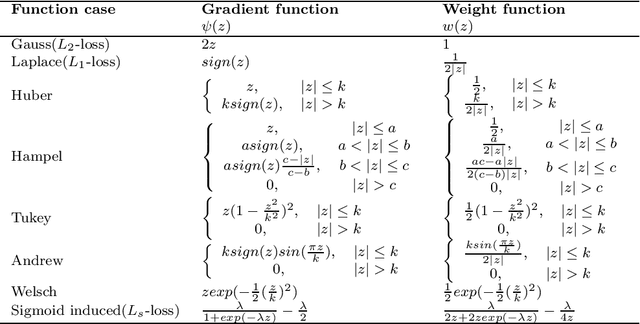

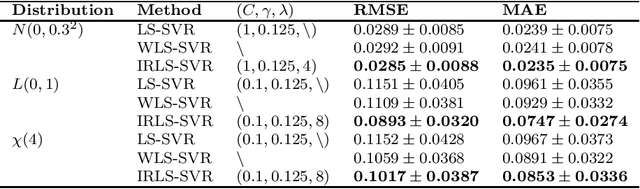
The measure of most robust machine learning methods is reweighted. To overcome the optimization difficulty of the implicitly reweighted robust methods (including modifying loss functions and objectives), we try to use a more direct method: explicitly iteratively reweighted method to handle noise (even heavy-tailed noise and outlier) robustness. In this paper, an explicitly iterative reweighted framework based on two kinds of kernel based regression algorithm (LS-SVR and ELM) is established, and a novel weight selection strategy is proposed at the same time. Combining the proposed weight function with the iteratively reweighted framework, we propose two models iteratively reweighted least squares support vector machine (IRLS-SVR) and iteratively reweighted extreme learning machine (IRLS-ELM) to implement robust regression. Different from the traditional explicitly reweighted robust methods, we carry out multiple reweighted operations in our work to further improve robustness. The convergence and approximability of the proposed algorithms are proved theoretically. Moreover, the robustness of the algorithm is analyzed in detail from many angles. Experiments on both artificial data and benchmark datasets confirm the validity of the proposed methods.
Efficiently utilizing complex-valued PolSAR image data via a multi-task deep learning framework
Mar 24, 2019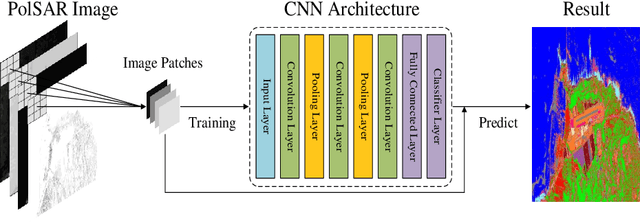

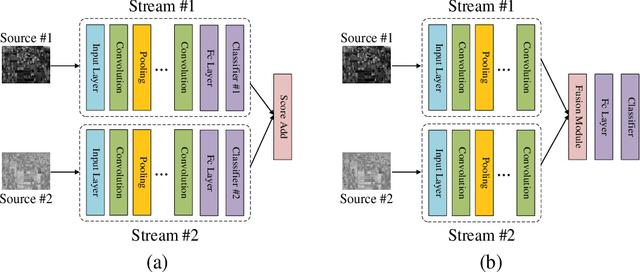
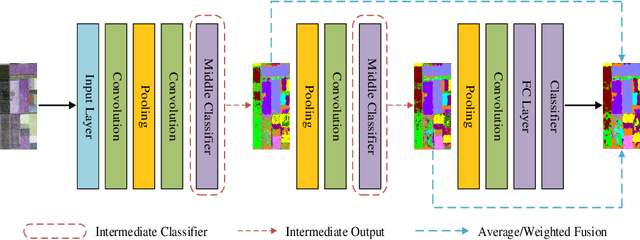
Accompanied by the successful progress of deep representation learning, convolutional neural networks (CNNs) have been widely applied to improve the accuracy of polarimetric synthetic aperture radar (PolSAR) image classification. However, in most applications, the difference between PolSAR image and optical image is rarely considered. The design of most existing network structures is not tailored to the characteristics of PolSAR image data and complex-valued data of PolSAR image are simply equated to real-valued data to adapt to the existing mainstream network pipeline to avoid complex-valued operations. These make CNNs unable to perform their full capabilities in the PolSAR image classification tasks. In this paper, we focus on finding a better input form of PolSAR image data and designing special CNN structures that are more compatible with PolSAR image. Considering the relationship between complex number and its amplitude and phase, we extract the amplitude and phase of the complex-valued PolSAR image data as input to maintain the integrity of the original information while avoiding the current immature complex-valued operations, and a novel multi-task CNN framework is proposed to adapt to novel form of input data. Furthermore, in order to better explore the unique phase information in the PolSAR image data, depthwise separable convolutions are applied to the proposed multi-task CNN model. Experiments on three benchmark datasets not only prove that using amplitude and phase information as input does contribute to the improvement of classification accuracy, but also verify the effectiveness of the proposed methods for amplitude and phase input.