 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Text-Guided Single Image Editing for Remote Sensing Images
May 09, 2024



Artificial Intelligence Generative Content (AIGC) technologies have significantly influenced the remote sensing domain, particularly in the realm of image generation. However, remote sensing image editing, an equally vital research area, has not garnered sufficient attention. Different from text-guided editing in natural images, which relies on extensive text-image paired data for semantic correlation, the application scenarios of remote sensing image editing are often extreme, such as forest on fire, so it is difficult to obtain sufficient paired samples. At the same time, the lack of remote sensing semantics and the ambiguity of text also restrict the further application of image editing in remote sensing field. To solve above problems, this letter proposes a diffusion based method to fulfill stable and controllable remote sensing image editing with text guidance. Our method avoids the use of a large number of paired image, and can achieve good image editing results using only a single image. The quantitative evaluation system including CLIP score and subjective evaluation metrics shows that our method has better editing effect on remote sensing images than the existing image editing model.
Background Debiased SAR Target Recognition via Causal Interventional Regularizer
Aug 30, 2023
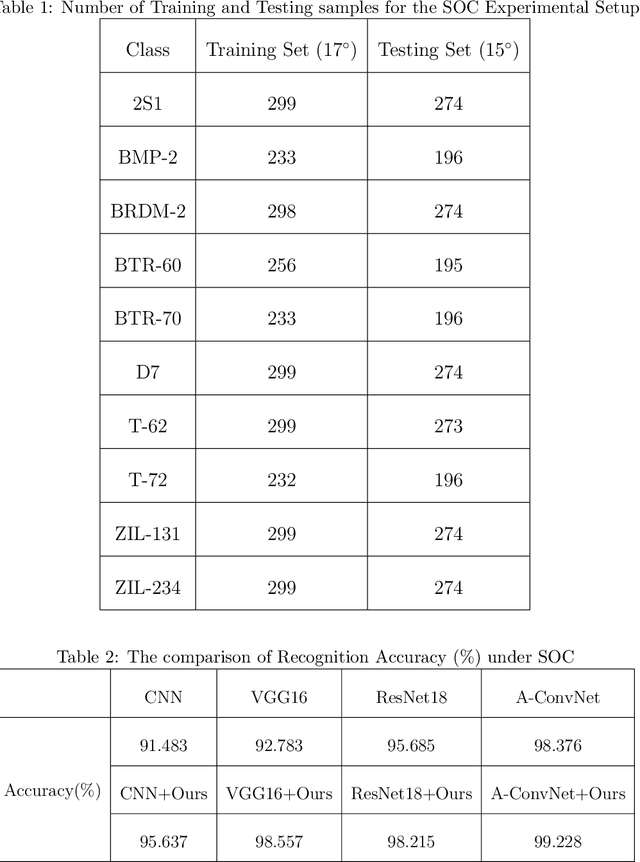
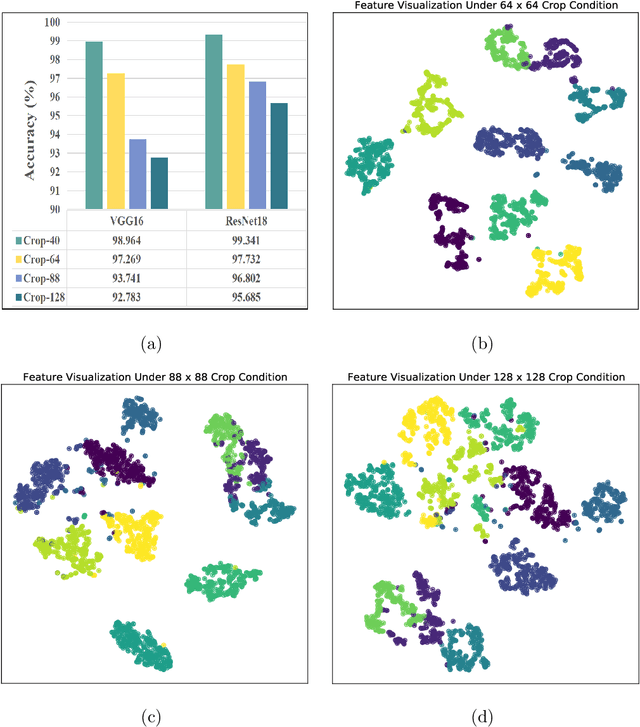
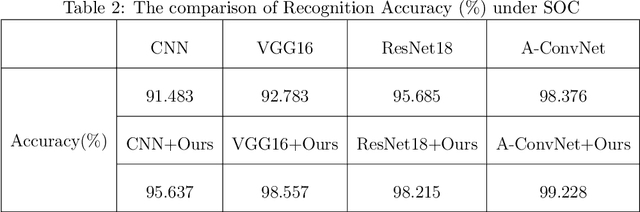
Recent studies have utilized deep learning (DL) techniques to automatically extract features from synthetic aperture radar (SAR) images, which shows great promise for enhancing the performance of SAR automatic target recognition (ATR). However, our research reveals a previously overlooked issue: SAR images to be recognized include not only the foreground (i.e., the target), but also a certain size of the background area. When a DL-model is trained exclusively on foreground data, its recognition performance is significantly superior to a model trained on original data that includes both foreground and background. This suggests that the presence of background impedes the ability of the DL-model to learn additional semantic information about the target. To address this issue, we construct a structural causal model (SCM) that incorporates the background as a confounder. Based on the constructed SCM, we propose a causal intervention based regularization method to eliminate the negative impact of background on feature semantic learning and achieve background debiased SAR-ATR. The proposed causal interventional regularizer can be integrated into any existing DL-based SAR-ATR models to mitigate the impact of background interference on the feature extraction and recognition accuracy. Experimental results on the Moving and Stationary Target Acquisition and Recognition (MSTAR) dataset indicate that the proposed method can enhance the efficiency of existing DL-based methods in a plug-and-play manner.
Deep Portrait Lighting Enhancement with 3D Guidance
Aug 04, 2021Despite recent breakthroughs in deep learning methods for image lighting enhancement, they are inferior when applied to portraits because 3D facial information is ignored in their models. To address this, we present a novel deep learning framework for portrait lighting enhancement based on 3D facial guidance. Our framework consists of two stages. In the first stage, corrected lighting parameters are predicted by a network from the input bad lighting image, with the assistance of a 3D morphable model and a differentiable renderer. Given the predicted lighting parameter, the differentiable renderer renders a face image with corrected shading and texture, which serves as the 3D guidance for learning image lighting enhancement in the second stage. To better exploit the long-range correlations between the input and the guidance, in the second stage, we design an image-to-image translation network with a novel transformer architecture, which automatically produces a lighting-enhanced result. Experimental results on the FFHQ dataset and in-the-wild images show that the proposed method outperforms state-of-the-art methods in terms of both quantitative metrics and visual quality. We will publish our dataset along with more results on https://cassiepython.github.io/egsr/index.html.
* {\dag} for equal conribution. Accepted to CGF. Project page: https://cassiepython.github.io/egsr/index.html
Exemplar-Based 3D Portrait Stylization
Apr 29, 2021

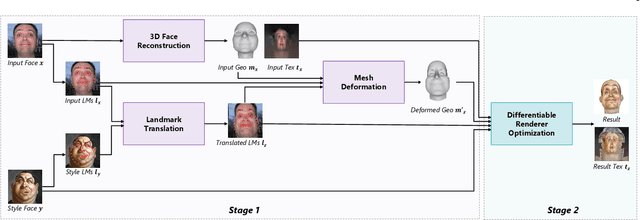

Exemplar-based portrait stylization is widely attractive and highly desired. Despite recent successes, it remains challenging, especially when considering both texture and geometric styles. In this paper, we present the first framework for one-shot 3D portrait style transfer, which can generate 3D face models with both the geometry exaggerated and the texture stylized while preserving the identity from the original content. It requires only one arbitrary style image instead of a large set of training examples for a particular style, provides geometry and texture outputs that are fully parameterized and disentangled, and enables further graphics applications with the 3D representations. The framework consists of two stages. In the first geometric style transfer stage, we use facial landmark translation to capture the coarse geometry style and guide the deformation of the dense 3D face geometry. In the second texture style transfer stage, we focus on performing style transfer on the canonical texture by adopting a differentiable renderer to optimize the texture in a multi-view framework. Experiments show that our method achieves robustly good results on different artistic styles and outperforms existing methods. We also demonstrate the advantages of our method via various 2D and 3D graphics applications. Project page is https://halfjoe.github.io/projs/3DPS/index.html.