 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Complex Wide-Area Scene Understanding with Hierarchical Coresets Selection
Jul 17, 2025Scene understanding is one of the core tasks in computer vision, aiming to extract semantic information from images to identify objects, scene categories, and their interrelationships. Although advancements in Vision-Language Models (VLMs) have driven progress in this field, existing VLMs still face challenges in adaptation to unseen complex wide-area scenes. To address the challenges, this paper proposes a Hierarchical Coresets Selection (HCS) mechanism to advance the adaptation of VLMs in complex wide-area scene understanding. It progressively refines the selected regions based on the proposed theoretically guaranteed importance function, which considers utility, representativeness, robustness, and synergy. Without requiring additional fine-tuning, HCS enables VLMs to achieve rapid understandings of unseen scenes at any scale using minimal interpretable regions while mitigating insufficient feature density. HCS is a plug-and-play method that is compatible with any VLM. Experiments demonstrate that HCS achieves superior performance and universality in various tasks.
On the Transferability and Discriminability of Repersentation Learning in Unsupervised Domain Adaptation
May 28, 2025In this paper, we addressed the limitation of relying solely on distribution alignment and source-domain empirical risk minimization in Unsupervised Domain Adaptation (UDA). Our information-theoretic analysis showed that this standard adversarial-based framework neglects the discriminability of target-domain features, leading to suboptimal performance. To bridge this theoretical-practical gap, we defined "good representation learning" as guaranteeing both transferability and discriminability, and proved that an additional loss term targeting target-domain discriminability is necessary. Building on these insights, we proposed a novel adversarial-based UDA framework that explicitly integrates a domain alignment objective with a discriminability-enhancing constraint. Instantiated as Domain-Invariant Representation Learning with Global and Local Consistency (RLGLC), our method leverages Asymmetrically-Relaxed Wasserstein of Wasserstein Distance (AR-WWD) to address class imbalance and semantic dimension weighting, and employs a local consistency mechanism to preserve fine-grained target-domain discriminative information. Extensive experiments across multiple benchmark datasets demonstrate that RLGLC consistently surpasses state-of-the-art methods, confirming the value of our theoretical perspective and underscoring the necessity of enforcing both transferability and discriminability in adversarial-based UDA.
Rethinking Meta-Learning from a Learning Lens
Sep 13, 2024Meta-learning has emerged as a powerful approach for leveraging knowledge from previous tasks to solve new tasks. The mainstream methods focus on training a well-generalized model initialization, which is then adapted to different tasks with limited data and updates. However, it pushes the model overfitting on the training tasks. Previous methods mainly attributed this to the lack of data and used augmentations to address this issue, but they were limited by sufficient training and effective augmentation strategies. In this work, we focus on the more fundamental ``learning to learn'' strategy of meta-learning to explore what causes errors and how to eliminate these errors without changing the environment. Specifically, we first rethink the algorithmic procedure of meta-learning from a ``learning'' lens. Through theoretical and empirical analyses, we find that (i) this paradigm faces the risk of both overfitting and underfitting and (ii) the model adapted to different tasks promote each other where the effect is stronger if the tasks are more similar. Based on this insight, we propose using task relations to calibrate the optimization process of meta-learning and propose a plug-and-play method called Task Relation Learner (TRLearner) to achieve this goal. Specifically, it first obtains task relation matrices from the extracted task-specific meta-data. Then, it uses the obtained matrices with relation-aware consistency regularization to guide optimization. Extensive theoretical and empirical analyses demonstrate the effectiveness of TRLearner.
On the Causal Sufficiency and Necessity of Multi-Modal Representation Learning
Jul 19, 2024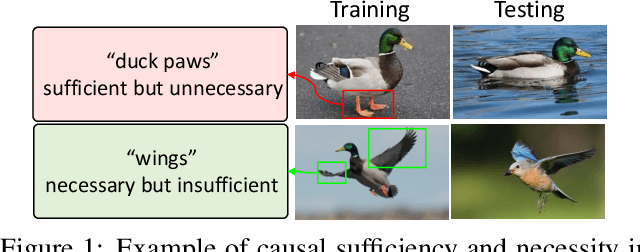
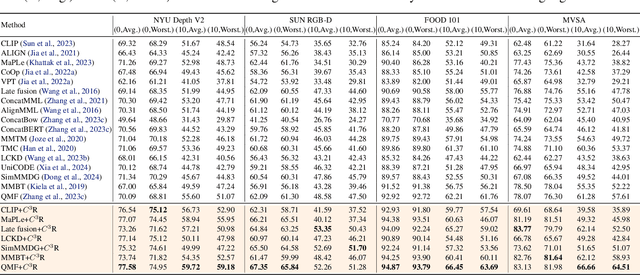
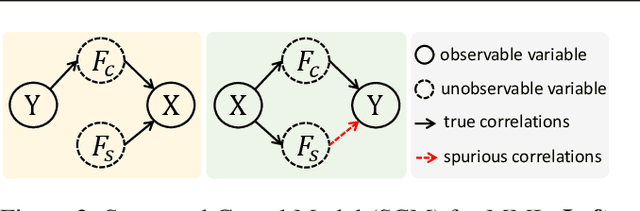
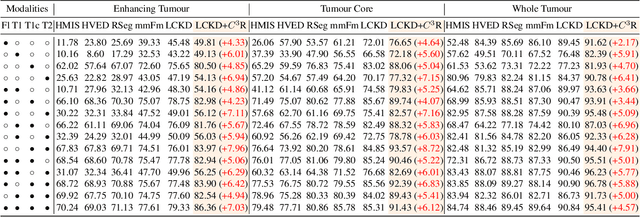
An effective paradigm of multi-modal learning (MML) is to learn unified representations among modalities. From a causal perspective, constraining the consistency between different modalities can mine causal representations that convey primary events. However, such simple consistency may face the risk of learning insufficient or unnecessary information: a necessary but insufficient cause is invariant across modalities but may not have the required accuracy; a sufficient but unnecessary cause tends to adapt well to specific modalities but may be hard to adapt to new data. To address this issue, in this paper, we aim to learn representations that are both causal sufficient and necessary, i.e., Causal Complete Cause ($C^3$), for MML. Firstly, we define the concept of $C^3$ for MML, which reflects the probability of being causal sufficiency and necessity. We also propose the identifiability and measurement of $C^3$, i.e., $C^3$ risk, to ensure calculating the learned representations' $C^3$ scores in practice. Then, we theoretically prove the effectiveness of $C^3$ risk by establishing the performance guarantee of MML with a tight generalization bound. Based on these theoretical results, we propose a plug-and-play method, namely Causal Complete Cause Regularization ($C^3$R), to learn causal complete representations by constraining the $C^3$ risk bound. Extensive experiments conducted on various benchmark datasets empirically demonstrate the effectiveness of $C^3$R.
A Physical Model-Guided Framework for Underwater Image Enhancement and Depth Estimation
Jul 05, 2024
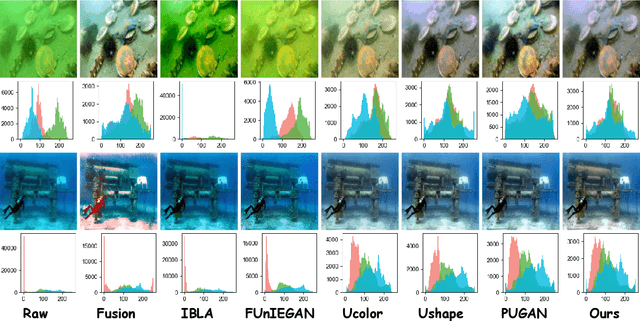


Due to the selective absorption and scattering of light by diverse aquatic media, underwater images usually suffer from various visual degradations. Existing underwater image enhancement (UIE) approaches that combine underwater physical imaging models with neural networks often fail to accurately estimate imaging model parameters such as depth and veiling light, resulting in poor performance in certain scenarios. To address this issue, we propose a physical model-guided framework for jointly training a Deep Degradation Model (DDM) with any advanced UIE model. DDM includes three well-designed sub-networks to accurately estimate various imaging parameters: a veiling light estimation sub-network, a factors estimation sub-network, and a depth estimation sub-network. Based on the estimated parameters and the underwater physical imaging model, we impose physical constraints on the enhancement process by modeling the relationship between underwater images and desired clean images, i.e., outputs of the UIE model. Moreover, while our framework is compatible with any UIE model, we design a simple yet effective fully convolutional UIE model, termed UIEConv. UIEConv utilizes both global and local features for image enhancement through a dual-branch structure. UIEConv trained within our framework achieves remarkable enhancement results across diverse underwater scenes. Furthermore, as a byproduct of UIE, the trained depth estimation sub-network enables accurate underwater scene depth estimation. Extensive experiments conducted in various real underwater imaging scenarios, including deep-sea environments with artificial light sources, validate the effectiveness of our framework and the UIEConv model.
Exploring Text-Guided Single Image Editing for Remote Sensing Images
May 09, 2024



Artificial Intelligence Generative Content (AIGC) technologies have significantly influenced the remote sensing domain, particularly in the realm of image generation. However, remote sensing image editing, an equally vital research area, has not garnered sufficient attention. Different from text-guided editing in natural images, which relies on extensive text-image paired data for semantic correlation, the application scenarios of remote sensing image editing are often extreme, such as forest on fire, so it is difficult to obtain sufficient paired samples. At the same time, the lack of remote sensing semantics and the ambiguity of text also restrict the further application of image editing in remote sensing field. To solve above problems, this letter proposes a diffusion based method to fulfill stable and controllable remote sensing image editing with text guidance. Our method avoids the use of a large number of paired image, and can achieve good image editing results using only a single image. The quantitative evaluation system including CLIP score and subjective evaluation metrics shows that our method has better editing effect on remote sensing images than the existing image editing model.
End-To-End Underwater Video Enhancement: Dataset and Model
Mar 18, 2024Underwater video enhancement (UVE) aims to improve the visibility and frame quality of underwater videos, which has significant implications for marine research and exploration. However, existing methods primarily focus on developing image enhancement algorithms to enhance each frame independently. There is a lack of supervised datasets and models specifically tailored for UVE tasks. To fill this gap, we construct the Synthetic Underwater Video Enhancement (SUVE) dataset, comprising 840 diverse underwater-style videos paired with ground-truth reference videos. Based on this dataset, we train a novel underwater video enhancement model, UVENet, which utilizes inter-frame relationships to achieve better enhancement performance. Through extensive experiments on both synthetic and real underwater videos, we demonstrate the effectiveness of our approach. This study represents the first comprehensive exploration of UVE to our knowledge. The code is available at https://anonymous.4open.science/r/UVENet.
Self-Supervised Representation Learning with Meta Comprehensive Regularization
Mar 03, 2024Self-Supervised Learning (SSL) methods harness the concept of semantic invariance by utilizing data augmentation strategies to produce similar representations for different deformations of the same input. Essentially, the model captures the shared information among multiple augmented views of samples, while disregarding the non-shared information that may be beneficial for downstream tasks. To address this issue, we introduce a module called CompMod with Meta Comprehensive Regularization (MCR), embedded into existing self-supervised frameworks, to make the learned representations more comprehensive. Specifically, we update our proposed model through a bi-level optimization mechanism, enabling it to capture comprehensive features. Additionally, guided by the constrained extraction of features using maximum entropy coding, the self-supervised learning model learns more comprehensive features on top of learning consistent features. In addition, we provide theoretical support for our proposed method from information theory and causal counterfactual perspective. Experimental results show that our method achieves significant improvement in classification, object detection and instance segmentation tasks on multiple benchmark datasets.
FreeStyle: Free Lunch for Text-guided Style Transfer using Diffusion Models
Jan 28, 2024The rapid development of generative diffusion models has significantly advanced the field of style transfer. However, most current style transfer methods based on diffusion models typically involve a slow iterative optimization process, e.g., model fine-tuning and textual inversion of style concept. In this paper, we introduce FreeStyle, an innovative style transfer method built upon a pre-trained large diffusion model, requiring no further optimization. Besides, our method enables style transfer only through a text description of the desired style, eliminating the necessity of style images. Specifically, we propose a dual-stream encoder and single-stream decoder architecture, replacing the conventional U-Net in diffusion models. In the dual-stream encoder, two distinct branches take the content image and style text prompt as inputs, achieving content and style decoupling. In the decoder, we further modulate features from the dual streams based on a given content image and the corresponding style text prompt for precise style transfer. Our experimental results demonstrate high-quality synthesis and fidelity of our method across various content images and style text prompts. The code and more results are available at our project website:https://freestylefreelunch.github.io/.
Rethinking Causal Relationships Learning in Graph Neural Networks
Dec 15, 2023



Graph Neural Networks (GNNs) demonstrate their significance by effectively modeling complex interrelationships within graph-structured data. To enhance the credibility and robustness of GNNs, it becomes exceptionally crucial to bolster their ability to capture causal relationships. However, despite recent advancements that have indeed strengthened GNNs from a causal learning perspective, conducting an in-depth analysis specifically targeting the causal modeling prowess of GNNs remains an unresolved issue. In order to comprehensively analyze various GNN models from a causal learning perspective, we constructed an artificially synthesized dataset with known and controllable causal relationships between data and labels. The rationality of the generated data is further ensured through theoretical foundations. Drawing insights from analyses conducted using our dataset, we introduce a lightweight and highly adaptable GNN module designed to strengthen GNNs' causal learning capabilities across a diverse range of tasks. Through a series of experiments conducted on both synthetic datasets and other real-world datasets, we empirically validate the effectiveness of the proposed module.