 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Causal Sufficiency and Necessity of Multi-Modal Representation Learning
Paper and Code
Jul 19, 2024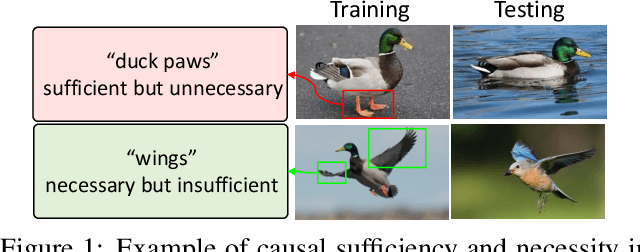
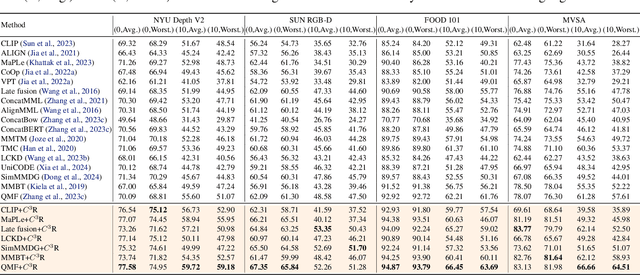
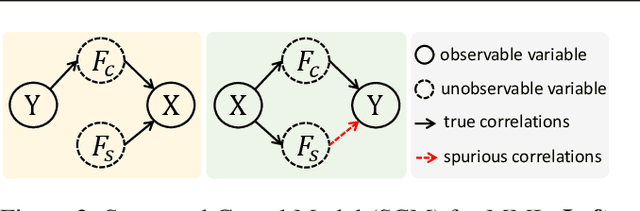
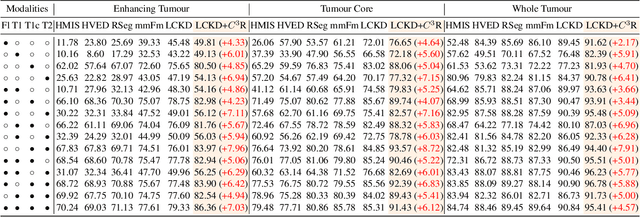
An effective paradigm of multi-modal learning (MML) is to learn unified representations among modalities. From a causal perspective, constraining the consistency between different modalities can mine causal representations that convey primary events. However, such simple consistency may face the risk of learning insufficient or unnecessary information: a necessary but insufficient cause is invariant across modalities but may not have the required accuracy; a sufficient but unnecessary cause tends to adapt well to specific modalities but may be hard to adapt to new data. To address this issue, in this paper, we aim to learn representations that are both causal sufficient and necessary, i.e., Causal Complete Cause ($C^3$), for MML. Firstly, we define the concept of $C^3$ for MML, which reflects the probability of being causal sufficiency and necessity. We also propose the identifiability and measurement of $C^3$, i.e., $C^3$ risk, to ensure calculating the learned representations' $C^3$ scores in practice. Then, we theoretically prove the effectiveness of $C^3$ risk by establishing the performance guarantee of MML with a tight generalization bound. Based on these theoretical results, we propose a plug-and-play method, namely Causal Complete Cause Regularization ($C^3$R), to learn causal complete representations by constraining the $C^3$ risk bound. Extensive experiments conducted on various benchmark datasets empirically demonstrate the effectiveness of $C^3$R.